 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Cross-camera Person Re-identification
Jun 05, 2023Camera-based person re-identification is a heavily privacy-invading task by design, benefiting from rich visual data to match together person representations across different cameras. This high-dimensional data can then easily be used for other, perhaps less desirable, applications. We here investigate the possibility of protecting such image data against uses outside of the intended re-identification task, and introduce a differential privacy mechanism leveraging both pixelisation and colour quantisation for this purpose. We show its ability to distort images in such a way that adverse task performances are significantly reduced, while retaining high re-identification performances.
Arukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023
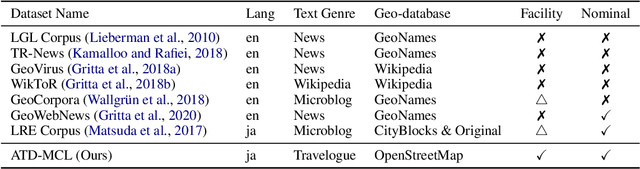
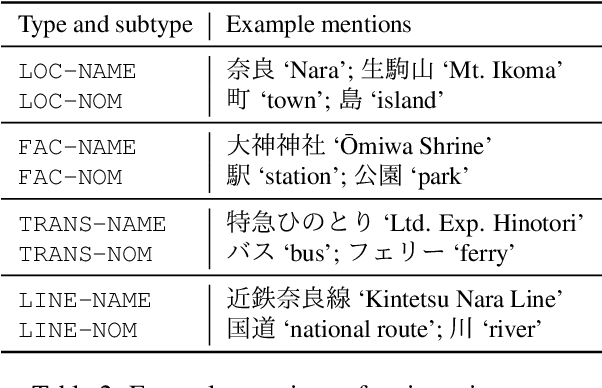

Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.
Arukikata Travelogue Dataset
May 19, 2023
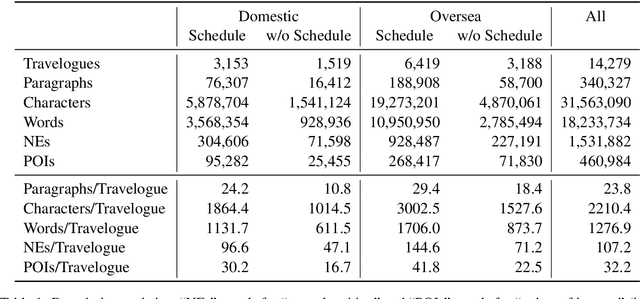
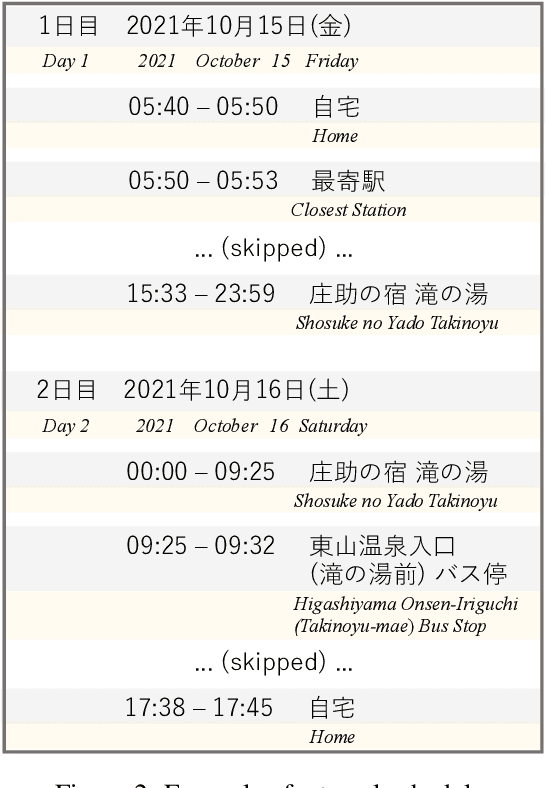
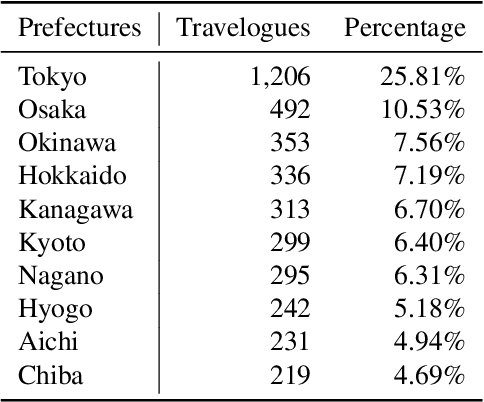
We have constructed Arukikata Travelogue Dataset and released it free of charge for academic research. This dataset is a Japanese text dataset with a total of over 31 million words, comprising 4,672 Japanese domestic travelogues and 9,607 overseas travelogues. Before providing our dataset, there was a scarcity of widely available travelogue data for research purposes, and each researcher had to prepare their own data. This hinders the replication of existing studies and fair comparative analysis of experimental results. Our dataset enables any researchers to conduct investigation on the same data and to ensure transparency and reproducibility in research. In this paper, we describe the academic significance, characteristics, and prospects of our dataset.