 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023
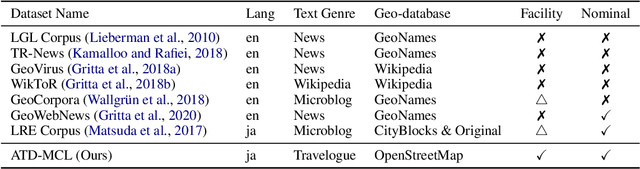
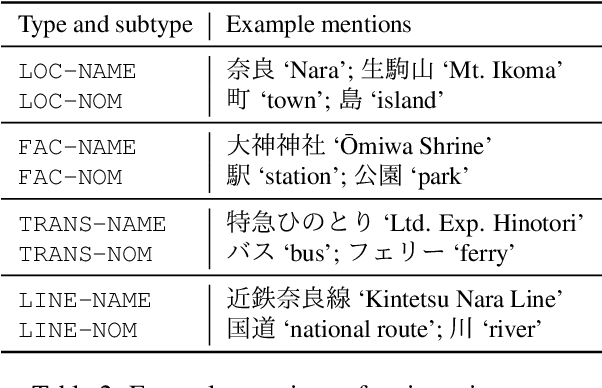

Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.
Arukikata Travelogue Dataset
May 19, 2023
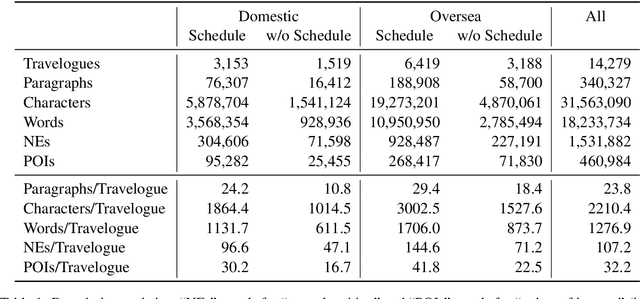
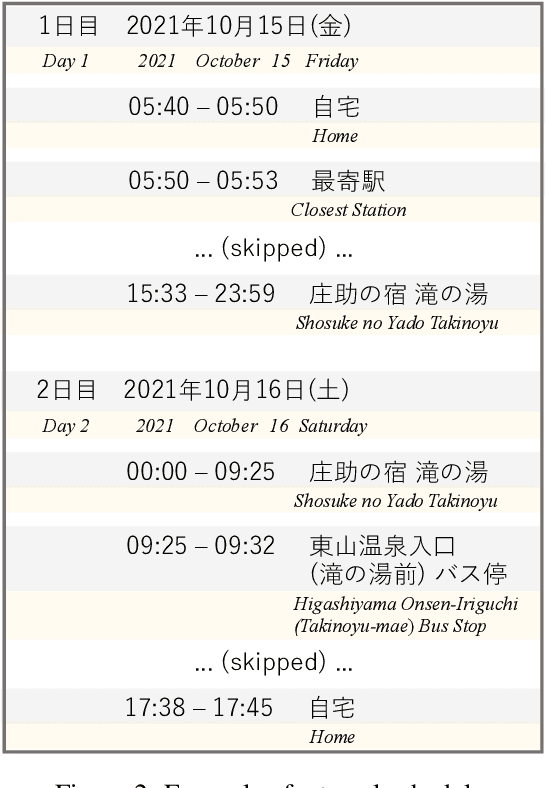
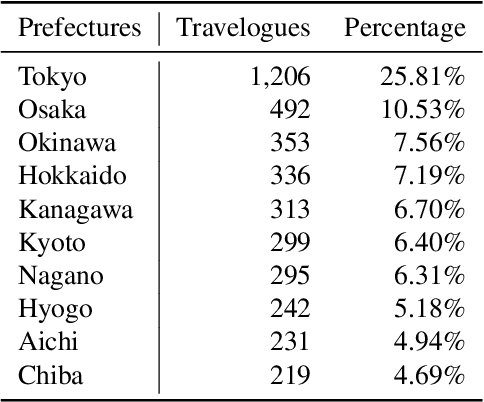
We have constructed Arukikata Travelogue Dataset and released it free of charge for academic research. This dataset is a Japanese text dataset with a total of over 31 million words, comprising 4,672 Japanese domestic travelogues and 9,607 overseas travelogues. Before providing our dataset, there was a scarcity of widely available travelogue data for research purposes, and each researcher had to prepare their own data. This hinders the replication of existing studies and fair comparative analysis of experimental results. Our dataset enables any researchers to conduct investigation on the same data and to ensure transparency and reproducibility in research. In this paper, we describe the academic significance, characteristics, and prospects of our dataset.
Annotation-Scheme Reconstruction for "Fake News" and Japanese Fake News Dataset
Apr 06, 2022



Fake news provokes many societal problems; therefore, there has been extensive research on fake news detection tasks to counter it. Many fake news datasets were constructed as resources to facilitate this task. Contemporary research focuses almost exclusively on the factuality aspect of the news. However, this aspect alone is insufficient to explain "fake news," which is a complex phenomenon that involves a wide range of issues. To fully understand the nature of each instance of fake news, it is important to observe it from various perspectives, such as the intention of the false news disseminator, the harmfulness of the news to our society, and the target of the news. We propose a novel annotation scheme with fine-grained labeling based on detailed investigations of existing fake news datasets to capture these various aspects of fake news. Using the annotation scheme, we construct and publish the first Japanese fake news dataset. The annotation scheme is expected to provide an in-depth understanding of fake news. We plan to build datasets for both Japanese and other languages using our scheme. Our Japanese dataset is published at https://hkefka385.github.io/dataset/fakenews-japanese/.
Mitigation of Diachronic Bias in Fake News Detection Dataset
Aug 28, 2021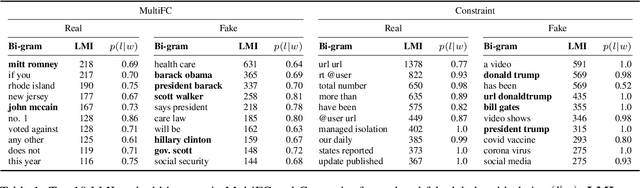
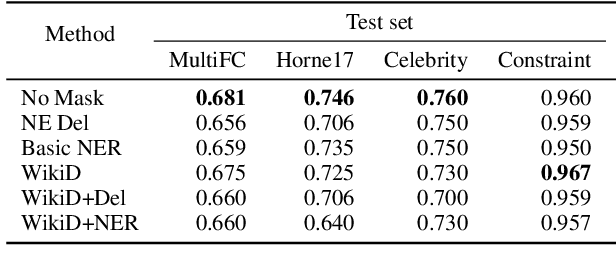
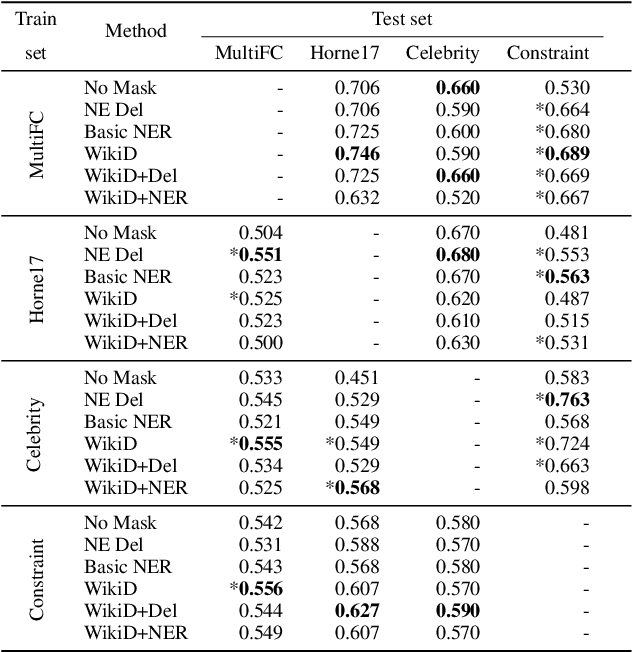
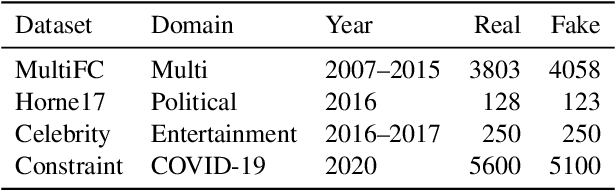
Fake news causes significant damage to society.To deal with these fake news, several studies on building detection models and arranging datasets have been conducted. Most of the fake news datasets depend on a specific time period. Consequently, the detection models trained on such a dataset have difficulty detecting novel fake news generated by political changes and social changes; they may possibly result in biased output from the input, including specific person names and organizational names. We refer to this problem as \textbf{Diachronic Bias} because it is caused by the creation date of news in each dataset. In this study, we confirm the bias, especially proper nouns including person names, from the deviation of phrase appearances in each dataset. Based on these findings, we propose masking methods using Wikidata to mitigate the influence of person names and validate whether they make fake news detection models robust through experiments with in-domain and out-of-domain data.
Single Model for Influenza Forecasting of Multiple Countries by Multi-task Learning
Jul 07, 2021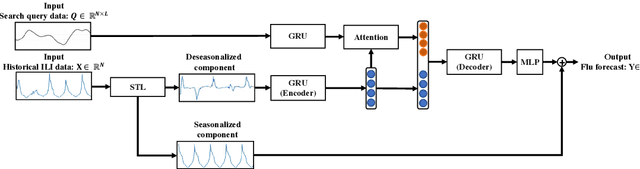
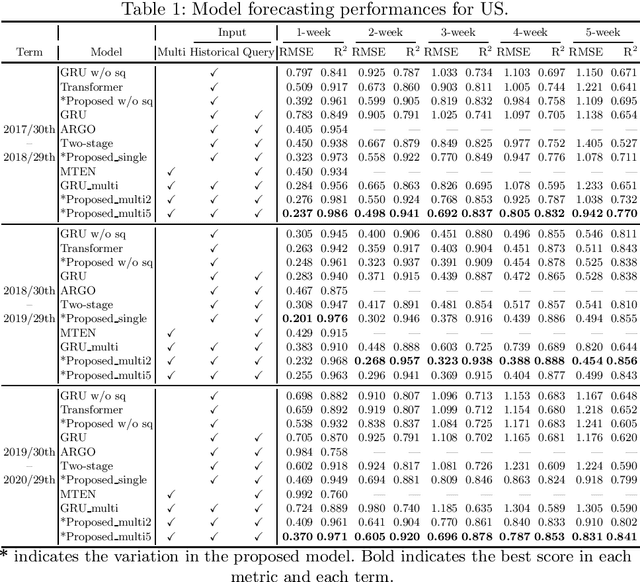
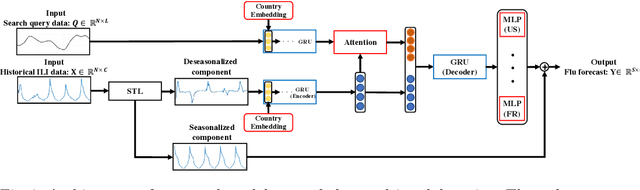
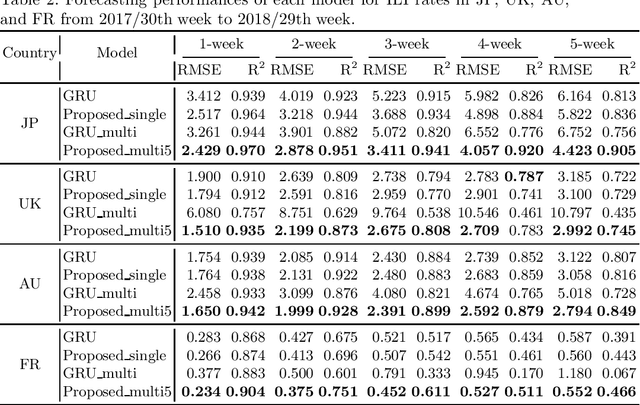
The accurate forecasting of infectious epidemic diseases such as influenza is a crucial task undertaken by medical institutions. Although numerous flu forecasting methods and models based mainly on historical flu activity data and online user-generated contents have been proposed in previous studies, no flu forecasting model targeting multiple countries using two types of data exists at present. Our paper leverages multi-task learning to tackle the challenge of building one flu forecasting model targeting multiple countries; each country as each task. Also, to develop the flu prediction model with higher performance, we solved two issues; finding suitable search queries, which are part of the user-generated contents, and how to leverage search queries efficiently in the model creation. For the first issue, we propose the transfer approaches from English to other languages. For the second issue, we propose a novel flu forecasting model that takes advantage of search queries using an attention mechanism and extend the model to a multi-task model for multiple countries' flu forecasts. Experiments on forecasting flu epidemics in five countries demonstrate that our model significantly improved the performance by leveraging the search queries and multi-task learning compared to the baselines.
End-to-end Biomedical Entity Linking with Span-based Dictionary Matching
Apr 21, 2021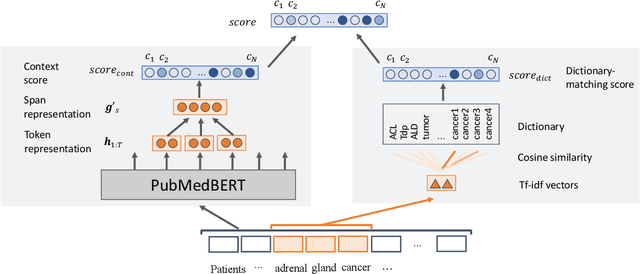
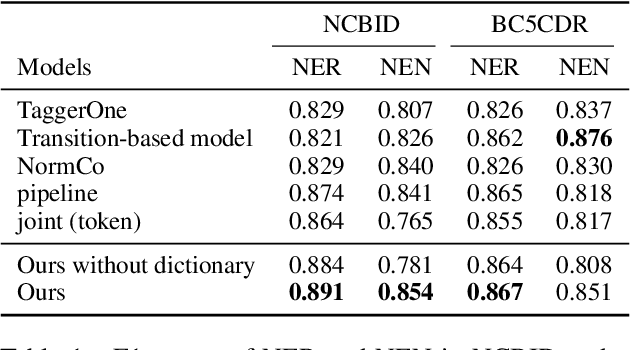
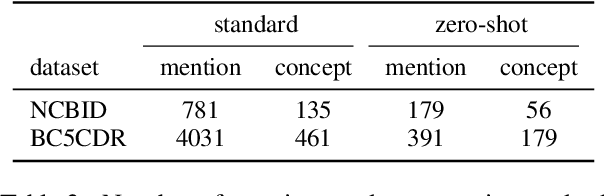

Disease name recognition and normalization, which is generally called biomedical entity linking, is a fundamental process in biomedical text mining. Recently, neural joint learning of both tasks has been proposed to utilize the mutual benefits. While this approach achieves high performance, disease concepts that do not appear in the training dataset cannot be accurately predicted. This study introduces a novel end-to-end approach that combines span representations with dictionary-matching features to address this problem. Our model handles unseen concepts by referring to a dictionary while maintaining the performance of neural network-based models, in an end-to-end fashion. Experiments using two major datasets demonstrate that our model achieved competitive results with strong baselines, especially for unseen concepts during training.
KART: Privacy Leakage Framework of Language Models Pre-trained with Clinical Records
Dec 31, 2020
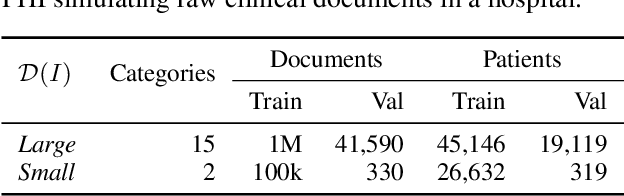

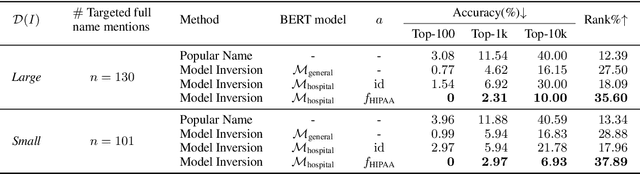
Nowadays, mainstream natural language pro-cessing (NLP) is empowered by pre-trained language models. In the biomedical domain, only models pre-trained with anonymized data have been published. This policy is acceptable, but there are two questions: Can the privacy policy of language models be different from that of data? What happens if private language models are accidentally made public? We empirically evaluated the privacy risk of language models, using several BERT models pre-trained with MIMIC-III corpus in different data anonymity and corpus sizes. We simulated model inversion attacks to obtain the clinical information of target individuals, whose full names are already known to attackers. The BERT models were probably low-risk because the Top-100 accuracy of each attack was far below expected by chance. Moreover, most privacy leakage situations have several common primary factors; therefore, we formalized various privacy leakage scenarios under a universal novel framework named Knowledge, Anonymization, Resource, and Target (KART) framework. The KART framework helps parameterize complex privacy leakage scenarios and simplifies the comprehensive evaluation. Since the concept of the KART framework is domain agnostic, it can contribute to the establishment of privacy guidelines of language models beyond the biomedical domain.
Density Estimation for Geolocation via Convolutional Mixture Density Network
May 08, 2017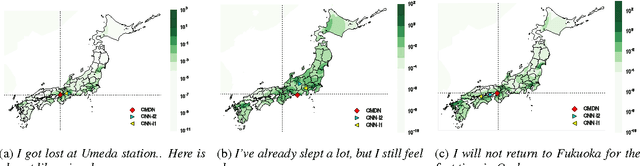
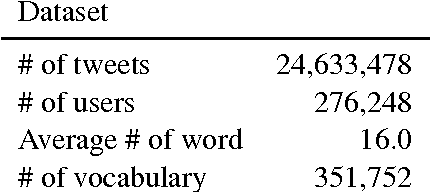
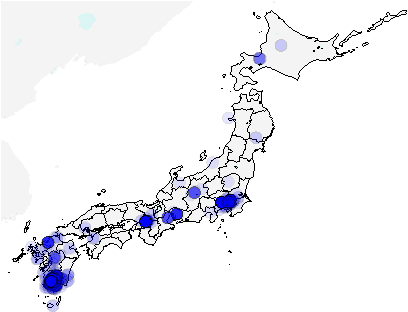
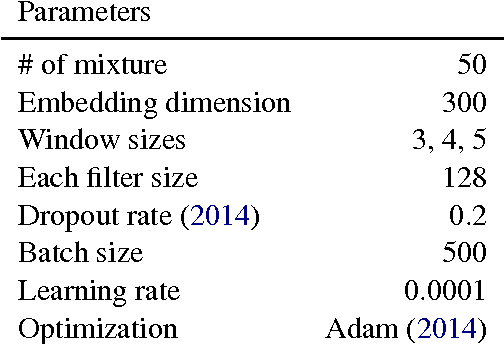
Nowadays, geographic information related to Twitter is crucially important for fine-grained applications. However, the amount of geographic information avail- able on Twitter is low, which makes the pursuit of many applications challenging. Under such circumstances, estimating the location of a tweet is an important goal of the study. Unlike most previous studies that estimate the pre-defined district as the classification task, this study employs a probability distribution to represent richer information of the tweet, not only the location but also its ambiguity. To realize this modeling, we propose the convolutional mixture density network (CMDN), which uses text data to estimate the mixture model parameters. Experimentally obtained results reveal that CMDN achieved the highest prediction performance among the method for predicting the exact coordinates. It also provides a quantitative representation of the location ambiguity for each tweet that properly works for extracting the reliable location estimations.