 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Forgetting: Machine Unlearning Elicits Controllable Side Behaviors and Capabilities
Jan 29, 2026We consider representation misdirection (RM), a class of LLM unlearning methods that achieves forgetting by manipulating the forget-representations, that is, latent representations of forget samples. Despite being important, the roles of target vectors used in RM, however, remain underexplored. Here, we approach and revisit RM through the lens of the linear representation hypothesis. Specifically, if one can somehow identify a one-dimensional representation corresponding to a high-level concept, the linear representation hypothesis enables linear operations on this concept vector within the forget-representation space. Under this view, we hypothesize that, beyond forgetting, machine unlearning elicits controllable side behaviors and stronger side capabilities corresponding to the high-level concept. Our hypothesis is empirically validated across a wide range of tasks, including behavioral control (e.g., controlling unlearned models' truth, sentiment, and refusal) and capability enhancement (e.g., improving unlearned models' in-context learning capability). Our findings reveal that this fairly attractive phenomenon could be either a hidden risk if misused or a mechanism that can be harnessed for developing models that require stronger capabilities and controllable behaviors.
Improving Chain-of-Thought for Logical Reasoning via Attention-Aware Intervention
Jan 14, 2026Modern logical reasoning with LLMs primarily relies on employing complex interactive frameworks that decompose the reasoning process into subtasks solved through carefully designed prompts or requiring external resources (e.g., symbolic solvers) to exploit their strong logical structures. While interactive approaches introduce additional overhead, hybrid approaches depend on external components, which limit their scalability. A non-interactive, end-to-end framework enables reasoning to emerge within the model itself -- improving generalization while preserving analyzability without any external resources. In this work, we introduce a non-interactive, end-to-end framework for reasoning tasks. We show that introducing structural information into the few-shot prompt activates a subset of attention heads that patterns aligned with logical reasoning operators. Building on this insight, we propose Attention-Aware Intervention (AAI), an inference-time intervention method that reweights attention scores across selected heads identified by their logical patterns. AAI offers an efficient way to steer the model's reasoning toward leveraging prior knowledge through attention modulation. Extensive experiments show that AAI enhances logical reasoning performance across diverse benchmarks and model architectures, while incurring negligible additional computational overhead. Code is available at https://github.com/phuongnm94/aai_for_logical_reasoning.
Non-Iterative Symbolic-Aided Chain-of-Thought for Logical Reasoning
Aug 17, 2025This work introduces Symbolic-Aided Chain-of-Thought (CoT), an improved approach to standard CoT, for logical reasoning in large language models (LLMs). The key idea is to integrate lightweight symbolic representations into few-shot prompts, structuring the inference steps with a consistent strategy to make reasoning patterns more explicit within a non-iterative reasoning process. By incorporating these symbolic structures, our method preserves the generalizability of standard prompting techniques while enhancing the transparency, interpretability, and analyzability of LLM logical reasoning. Extensive experiments on four well-known logical reasoning benchmarks -- ProofWriter, FOLIO, ProntoQA, and LogicalDeduction, which cover diverse reasoning scenarios -- demonstrate the effectiveness of the proposed approach, particularly in complex reasoning tasks that require navigating multiple constraints or rules. Notably, Symbolic-Aided CoT consistently improves LLMs' reasoning capabilities across various model sizes and significantly outperforms conventional CoT on three out of four datasets, ProofWriter, ProntoQA, and LogicalDeduction.
Unifying Attention Heads and Task Vectors via Hidden State Geometry in In-Context Learning
May 24, 2025The unusual properties of in-context learning (ICL) have prompted investigations into the internal mechanisms of large language models. Prior work typically focuses on either special attention heads or task vectors at specific layers, but lacks a unified framework linking these components to the evolution of hidden states across layers that ultimately produce the model's output. In this paper, we propose such a framework for ICL in classification tasks by analyzing two geometric factors that govern performance: the separability and alignment of query hidden states. A fine-grained analysis of layer-wise dynamics reveals a striking two-stage mechanism: separability emerges in early layers, while alignment develops in later layers. Ablation studies further show that Previous Token Heads drive separability, while Induction Heads and task vectors enhance alignment. Our findings thus bridge the gap between attention heads and task vectors, offering a unified account of ICL's underlying mechanisms.
Mechanistic Fine-tuning for In-context Learning
May 20, 2025In-context Learning (ICL) utilizes structured demonstration-query inputs to induce few-shot learning on Language Models (LMs), which are not originally pre-trained on ICL-style data. To bridge the gap between ICL and pre-training, some approaches fine-tune LMs on large ICL-style datasets by an end-to-end paradigm with massive computational costs. To reduce such costs, in this paper, we propose Attention Behavior Fine-Tuning (ABFT), utilizing the previous findings on the inner mechanism of ICL, building training objectives on the attention scores instead of the final outputs, to force the attention scores to focus on the correct label tokens presented in the context and mitigate attention scores from the wrong label tokens. Our experiments on 9 modern LMs and 8 datasets empirically find that ABFT outperforms in performance, robustness, unbiasedness, and efficiency, with only around 0.01% data cost compared to the previous methods. Moreover, our subsequent analysis finds that the end-to-end training objective contains the ABFT objective, suggesting the implicit bias of ICL-style data to the emergence of induction heads. Our work demonstrates the possibility of controlling specific module sequences within LMs to improve their behavior, opening up the future application of mechanistic interpretability.
Affinity and Diversity: A Unified Metric for Demonstration Selection via Internal Representations
Feb 20, 2025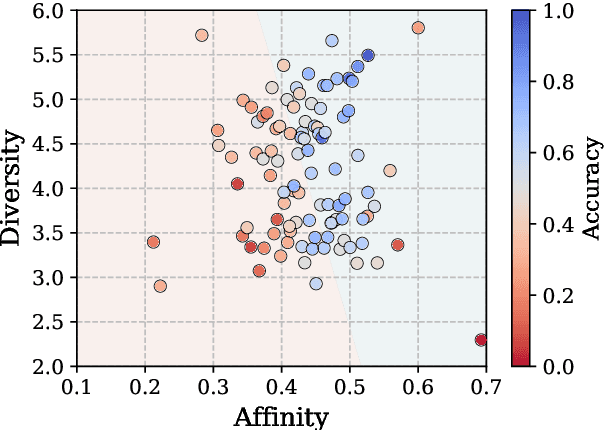
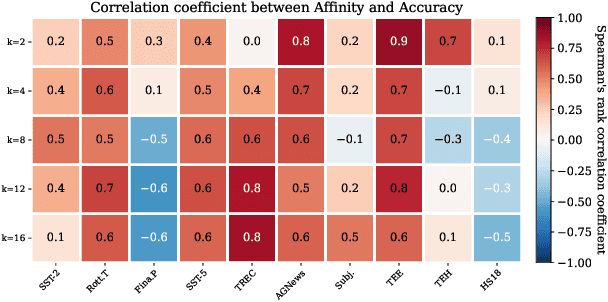
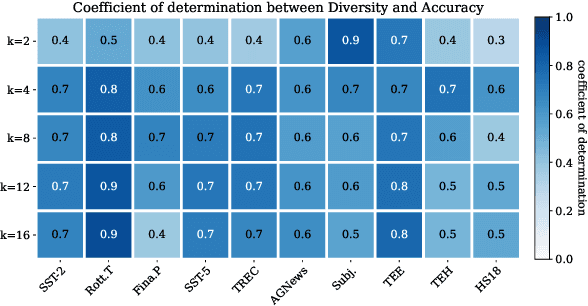
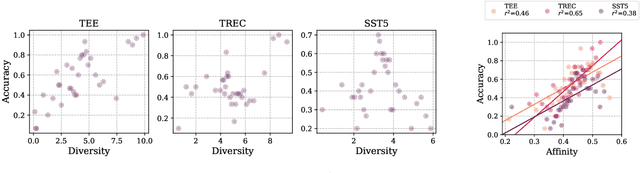
The performance of In-Context Learning (ICL) is highly sensitive to the selected demonstrations. Existing approaches to demonstration selection optimize different objectives, yielding inconsistent results. To address this, we propose a unified metric--affinity and diversity--that leverages ICL model's internal representations. Our experiments show that both affinity and diversity strongly correlate with test accuracies, indicating their effectiveness for demonstration selection. Moreover, we show that our proposed metrics align well with various previous works to unify the inconsistency.
Improving the Robustness of Representation Misdirection for Large Language Model Unlearning
Jan 31, 2025Representation Misdirection (RM) and variants are established large language model (LLM) unlearning methods with state-of-the-art performance. In this paper, we show that RM methods inherently reduce models' robustness, causing them to misbehave even when a single non-adversarial forget-token is in the retain-query. Toward understanding underlying causes, we reframe the unlearning process as backdoor attacks and defenses: forget-tokens act as backdoor triggers that, when activated in retain-queries, cause disruptions in RM models' behaviors, similar to successful backdoor attacks. To mitigate this vulnerability, we propose Random Noise Augmentation -- a model and method agnostic approach with theoretical guarantees for improving the robustness of RM methods. Extensive experiments demonstrate that RNA significantly improves the robustness of RM models while enhancing the unlearning performances.
StaICC: Standardized Evaluation for Classification Task in In-context Learning
Jan 27, 2025Classification tasks are widely investigated in the In-Context Learning (ICL) paradigm. However, current efforts are evaluated on disjoint benchmarks and settings, while their performances are significantly influenced by some trivial variables, such as prompt templates, data sampling, instructions, etc., which leads to significant inconsistencies in the results reported across various literature, preventing fair comparison or meta-analysis across different papers. Therefore, this paper proposes a standardized and easy-to-use evaluation toolkit (StaICC) for in-context classification. Including, for the normal classification task, we provide StaICC-Normal, selecting 10 widely used datasets, and generating prompts with a fixed form, to mitigate the variance among the experiment implementations. To enrich the usage of our benchmark, we also provide a sub-benchmark StaICC-Diag for diagnosing ICL from several aspects, aiming for a more robust inference processing.
Phase Diagram of Vision Large Language Models Inference: A Perspective from Interaction across Image and Instruction
Nov 01, 2024Vision Large Language Models (VLLMs) usually take input as a concatenation of image token embeddings and text token embeddings and conduct causal modeling. However, their internal behaviors remain underexplored, raising the question of interaction among two types of tokens. To investigate such multimodal interaction during model inference, in this paper, we measure the contextualization among the hidden state vectors of tokens from different modalities. Our experiments uncover a four-phase inference dynamics of VLLMs against the depth of Transformer-based LMs, including (I) Alignment: In very early layers, contextualization emerges between modalities, suggesting a feature space alignment. (II) Intra-modal Encoding: In early layers, intra-modal contextualization is enhanced while inter-modal interaction is suppressed, suggesting a local encoding within modalities. (III) Inter-modal Encoding: In later layers, contextualization across modalities is enhanced, suggesting a deeper fusion across modalities. (IV) Output Preparation: In very late layers, contextualization is reduced globally, and hidden states are aligned towards the unembedding space.
Revisiting In-context Learning Inference Circuit in Large Language Models
Oct 06, 2024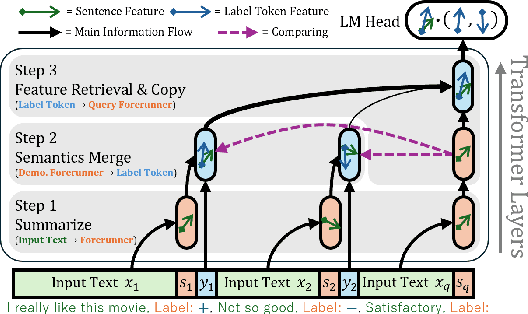
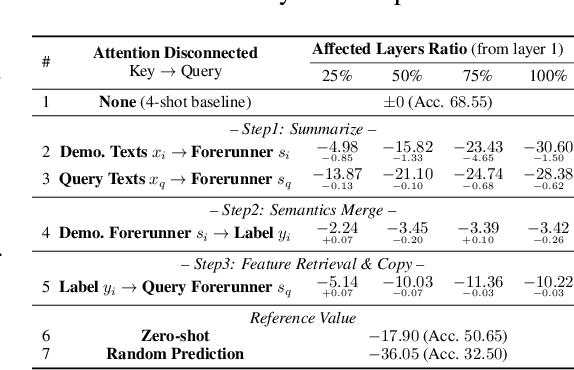
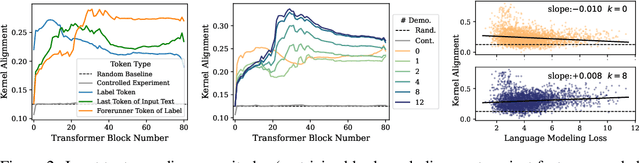
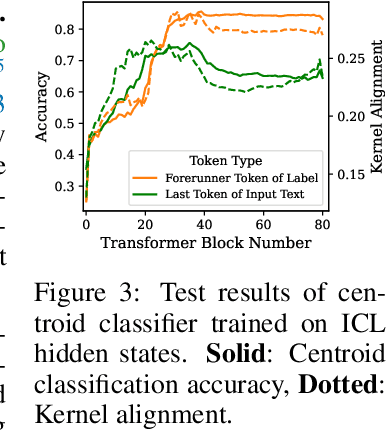
In-context Learning (ICL) is an emerging few-shot learning paradigm on Language Models (LMs) with inner mechanisms un-explored. There are already existing works describing the inner processing of ICL, while they struggle to capture all the inference phenomena in large language models. Therefore, this paper proposes a comprehensive circuit to model the inference dynamics and try to explain the observed phenomena of ICL. In detail, we divide ICL inference into 3 major operations: (1) Summarize: LMs encode every input text (demonstrations and queries) into linear representation in the hidden states with sufficient information to solve ICL tasks. (2) Semantics Merge: LMs merge the encoded representations of demonstrations with their corresponding label tokens to produce joint representations of labels and demonstrations. (3) Feature Retrieval and Copy: LMs search the joint representations similar to the query representation on a task subspace, and copy the searched representations into the query. Then, language model heads capture these copied label representations to a certain extent and decode them into predicted labels. The proposed inference circuit successfully captured many phenomena observed during the ICL process, making it a comprehensive and practical explanation of the ICL inference process. Moreover, ablation analysis by disabling the proposed steps seriously damages the ICL performance, suggesting the proposed inference circuit is a dominating mechanism. Additionally, we confirm and list some bypass mechanisms that solve ICL tasks in parallel with the proposed circuit.