 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-based Decision Criteria Are Suboptimal in In-context Learning
Jun 24, 2024In-Context Learning (ICL) typically utilizes classification criteria from probabilities of manually selected label tokens. However, we argue that such token-based classification criteria lead to suboptimal decision boundaries, despite delicate calibrations through translation and constrained rotation. To address this problem, we propose Hidden Calibration, which renounces token probabilities and uses the nearest centroid classifier on the LM's last hidden states. In detail, we use the nearest centroid classification on the hidden states, assigning the category of the nearest centroid previously observed from a few-shot calibration set to the test sample as the predicted label. Our experiments on 3 models and 10 classification datasets indicate that Hidden Calibration consistently outperforms current token-based calibrations by about 20%. Our further analysis demonstrates that Hidden Calibration finds better classification criteria with less inter-categories overlap, and LMs provide linearly separable intra-category clusters with the help of demonstrations, which supports Hidden Calibration and gives new insights into the conventional ICL.
Understanding Token Probability Encoding in Output Embeddings
Jun 03, 2024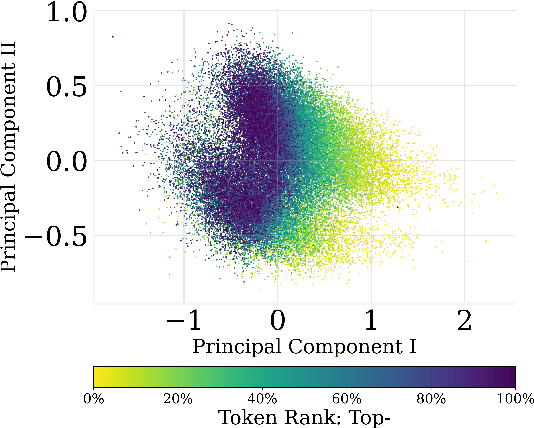
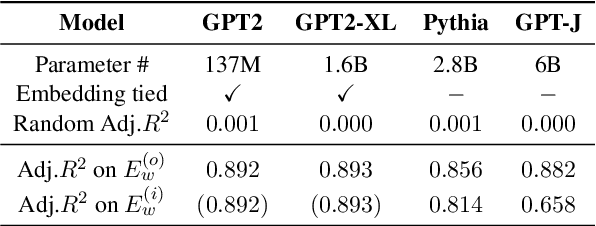
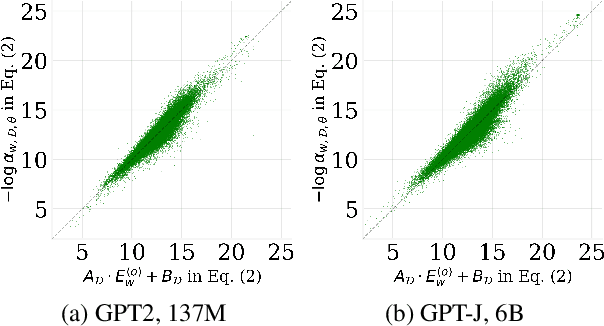
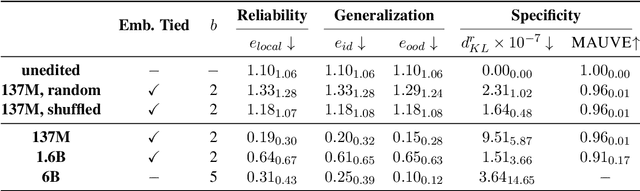
In this paper, we investigate the output token probability information in the output embedding of language models. We provide an approximate common log-linear encoding of output token probabilities within the output embedding vectors and demonstrate that it is accurate and sparse when the output space is large and output logits are concentrated. Based on such findings, we edit the encoding in output embedding to modify the output probability distribution accurately. Moreover, the sparsity we find in output probability encoding suggests that a large number of dimensions in the output embedding do not contribute to causal language modeling. Therefore, we attempt to delete the output-unrelated dimensions and find more than 30% of the dimensions can be deleted without significant movement in output distribution and degeneration on sequence generation. Additionally, in training dynamics, we use such encoding as a probe and find that the output embeddings capture token frequency information in early steps, even before an obvious convergence starts.