 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Token Probability Encoding in Output Embeddings
Paper and Code
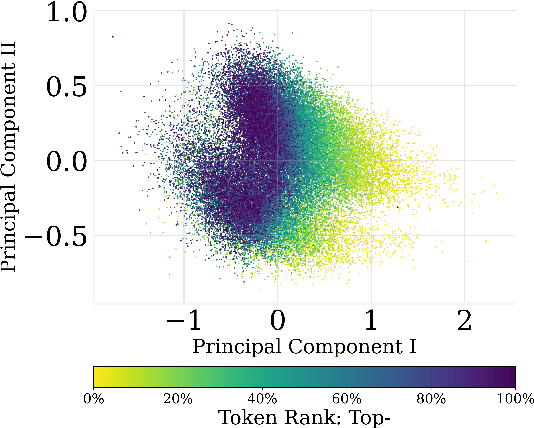
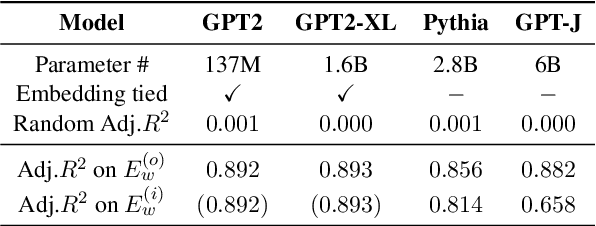
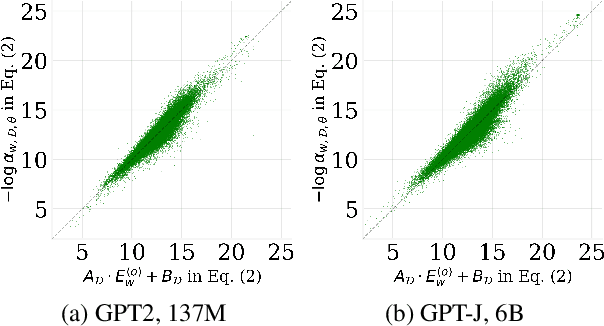
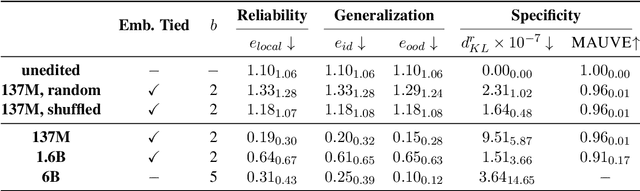
In this paper, we investigate the output token probability information in the output embedding of language models. We provide an approximate common log-linear encoding of output token probabilities within the output embedding vectors and demonstrate that it is accurate and sparse when the output space is large and output logits are concentrated. Based on such findings, we edit the encoding in output embedding to modify the output probability distribution accurately. Moreover, the sparsity we find in output probability encoding suggests that a large number of dimensions in the output embedding do not contribute to causal language modeling. Therefore, we attempt to delete the output-unrelated dimensions and find more than 30% of the dimensions can be deleted without significant movement in output distribution and degeneration on sequence generation. Additionally, in training dynamics, we use such encoding as a probe and find that the output embeddings capture token frequency information in early steps, even before an obvious convergence starts.