 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic Fine-tuning for In-context Learning
May 20, 2025In-context Learning (ICL) utilizes structured demonstration-query inputs to induce few-shot learning on Language Models (LMs), which are not originally pre-trained on ICL-style data. To bridge the gap between ICL and pre-training, some approaches fine-tune LMs on large ICL-style datasets by an end-to-end paradigm with massive computational costs. To reduce such costs, in this paper, we propose Attention Behavior Fine-Tuning (ABFT), utilizing the previous findings on the inner mechanism of ICL, building training objectives on the attention scores instead of the final outputs, to force the attention scores to focus on the correct label tokens presented in the context and mitigate attention scores from the wrong label tokens. Our experiments on 9 modern LMs and 8 datasets empirically find that ABFT outperforms in performance, robustness, unbiasedness, and efficiency, with only around 0.01% data cost compared to the previous methods. Moreover, our subsequent analysis finds that the end-to-end training objective contains the ABFT objective, suggesting the implicit bias of ICL-style data to the emergence of induction heads. Our work demonstrates the possibility of controlling specific module sequences within LMs to improve their behavior, opening up the future application of mechanistic interpretability.
Affinity and Diversity: A Unified Metric for Demonstration Selection via Internal Representations
Feb 20, 2025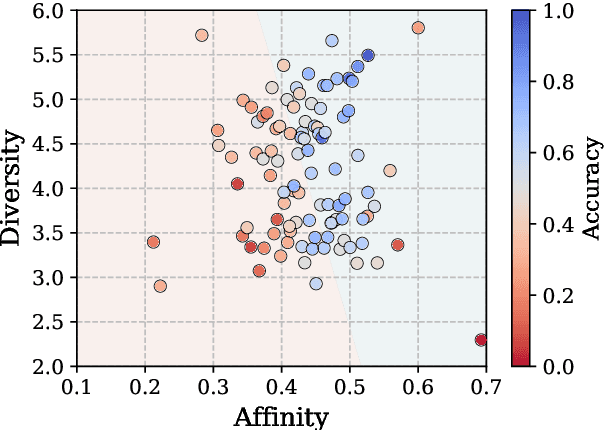
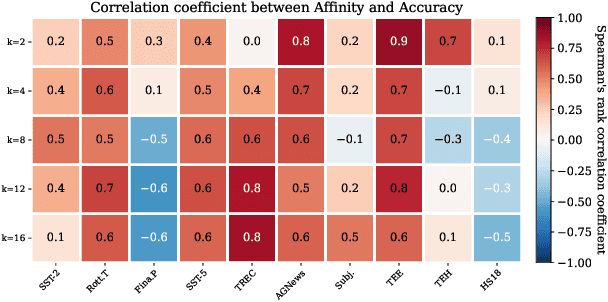
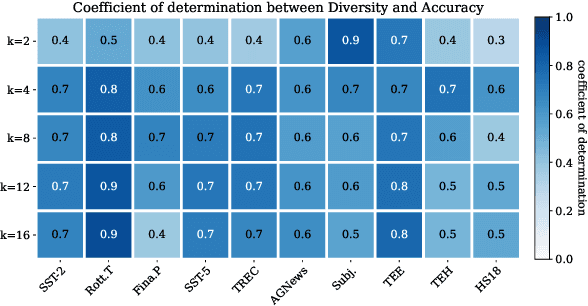
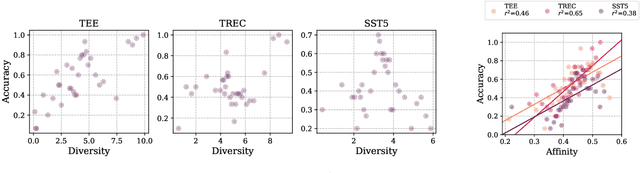
The performance of In-Context Learning (ICL) is highly sensitive to the selected demonstrations. Existing approaches to demonstration selection optimize different objectives, yielding inconsistent results. To address this, we propose a unified metric--affinity and diversity--that leverages ICL model's internal representations. Our experiments show that both affinity and diversity strongly correlate with test accuracies, indicating their effectiveness for demonstration selection. Moreover, we show that our proposed metrics align well with various previous works to unify the inconsistency.
Revisiting In-context Learning Inference Circuit in Large Language Models
Oct 06, 2024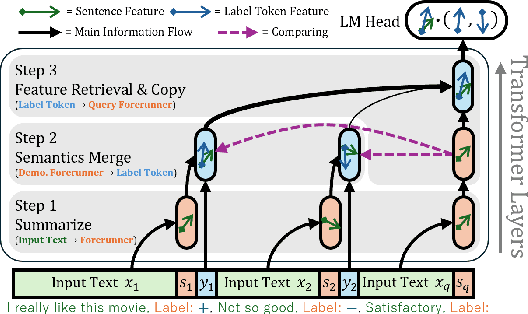
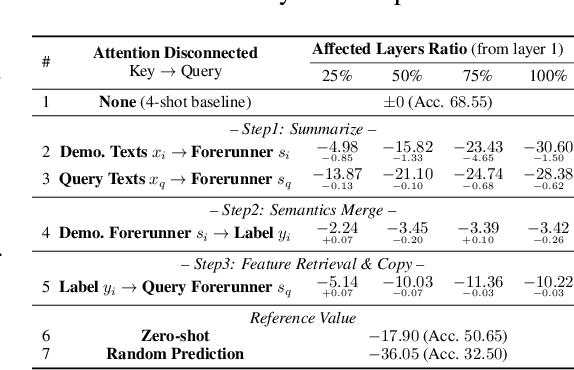
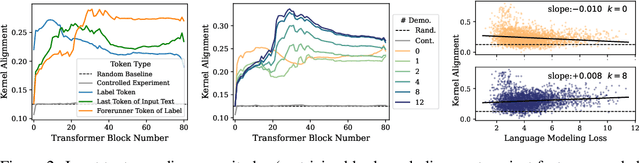
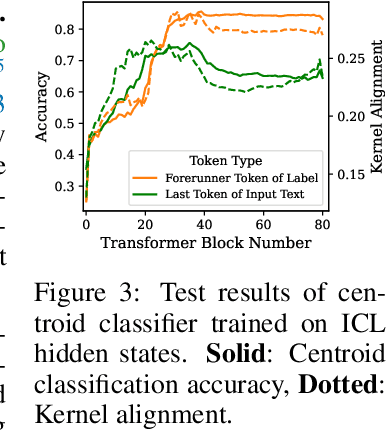
In-context Learning (ICL) is an emerging few-shot learning paradigm on Language Models (LMs) with inner mechanisms un-explored. There are already existing works describing the inner processing of ICL, while they struggle to capture all the inference phenomena in large language models. Therefore, this paper proposes a comprehensive circuit to model the inference dynamics and try to explain the observed phenomena of ICL. In detail, we divide ICL inference into 3 major operations: (1) Summarize: LMs encode every input text (demonstrations and queries) into linear representation in the hidden states with sufficient information to solve ICL tasks. (2) Semantics Merge: LMs merge the encoded representations of demonstrations with their corresponding label tokens to produce joint representations of labels and demonstrations. (3) Feature Retrieval and Copy: LMs search the joint representations similar to the query representation on a task subspace, and copy the searched representations into the query. Then, language model heads capture these copied label representations to a certain extent and decode them into predicted labels. The proposed inference circuit successfully captured many phenomena observed during the ICL process, making it a comprehensive and practical explanation of the ICL inference process. Moreover, ablation analysis by disabling the proposed steps seriously damages the ICL performance, suggesting the proposed inference circuit is a dominating mechanism. Additionally, we confirm and list some bypass mechanisms that solve ICL tasks in parallel with the proposed circuit.
Token-based Decision Criteria Are Suboptimal in In-context Learning
Jun 24, 2024In-Context Learning (ICL) typically utilizes classification criteria from probabilities of manually selected label tokens. However, we argue that such token-based classification criteria lead to suboptimal decision boundaries, despite delicate calibrations through translation and constrained rotation. To address this problem, we propose Hidden Calibration, which renounces token probabilities and uses the nearest centroid classifier on the LM's last hidden states. In detail, we use the nearest centroid classification on the hidden states, assigning the category of the nearest centroid previously observed from a few-shot calibration set to the test sample as the predicted label. Our experiments on 3 models and 10 classification datasets indicate that Hidden Calibration consistently outperforms current token-based calibrations by about 20%. Our further analysis demonstrates that Hidden Calibration finds better classification criteria with less inter-categories overlap, and LMs provide linearly separable intra-category clusters with the help of demonstrations, which supports Hidden Calibration and gives new insights into the conventional ICL.
Understanding Token Probability Encoding in Output Embeddings
Jun 03, 2024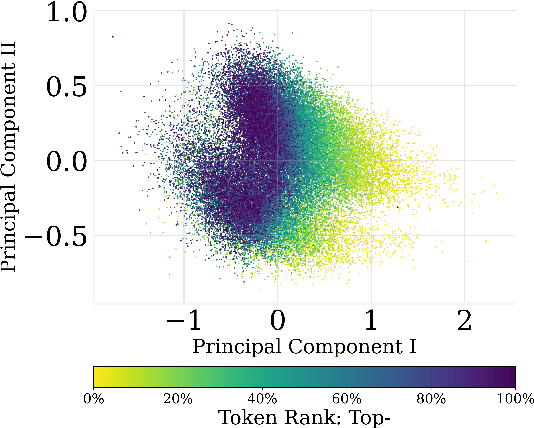
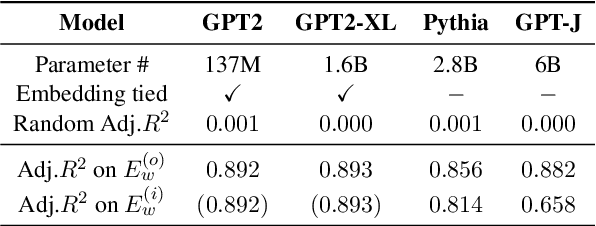
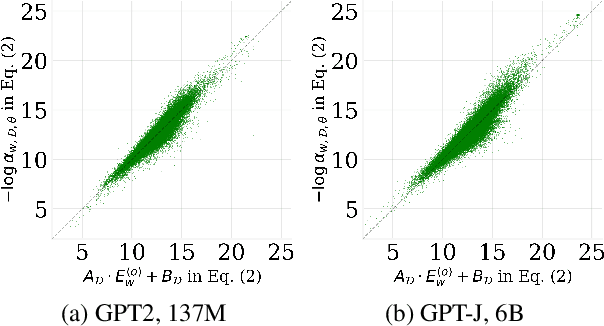
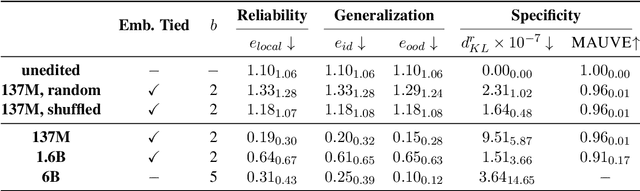
In this paper, we investigate the output token probability information in the output embedding of language models. We provide an approximate common log-linear encoding of output token probabilities within the output embedding vectors and demonstrate that it is accurate and sparse when the output space is large and output logits are concentrated. Based on such findings, we edit the encoding in output embedding to modify the output probability distribution accurately. Moreover, the sparsity we find in output probability encoding suggests that a large number of dimensions in the output embedding do not contribute to causal language modeling. Therefore, we attempt to delete the output-unrelated dimensions and find more than 30% of the dimensions can be deleted without significant movement in output distribution and degeneration on sequence generation. Additionally, in training dynamics, we use such encoding as a probe and find that the output embeddings capture token frequency information in early steps, even before an obvious convergence starts.