 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlee the Flaw: Annotating the Underlying Logic of Fallacious Arguments Through Templates and Slot-filling
Jun 18, 2024
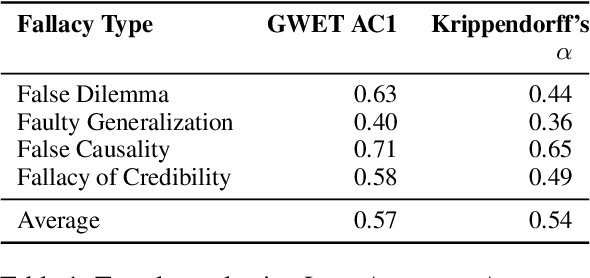
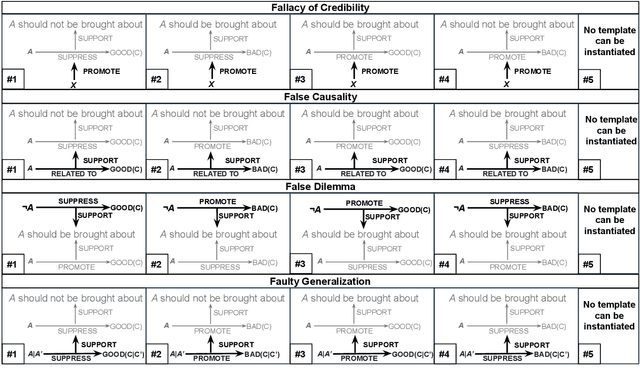
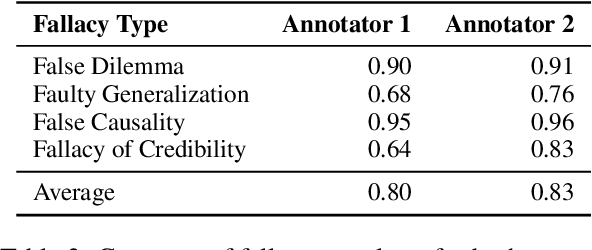
Prior research in computational argumentation has mainly focused on scoring the quality of arguments, with less attention on explicating logical errors. In this work, we introduce four sets of explainable templates for common informal logical fallacies designed to explicate a fallacy's implicit logic. Using our templates, we conduct an annotation study on top of 400 fallacious arguments taken from LOGIC dataset and achieve a high agreement score (Krippendorf's alpha of 0.54) and reasonable coverage (0.83). Finally, we conduct an experiment for detecting the structure of fallacies and discover that state-of-the-art language models struggle with detecting fallacy templates (0.47 accuracy). To facilitate research on fallacies, we make our dataset and guidelines publicly available.
Ain't Misbehavin' -- Using LLMs to Generate Expressive Robot Behavior in Conversations with the Tabletop Robot Haru
Feb 18, 2024Social robots aim to establish long-term bonds with humans through engaging conversation. However, traditional conversational approaches, reliant on scripted interactions, often fall short in maintaining engaging conversations. This paper addresses this limitation by integrating large language models (LLMs) into social robots to achieve more dynamic and expressive conversations. We introduce a fully-automated conversation system that leverages LLMs to generate robot responses with expressive behaviors, congruent with the robot's personality. We incorporate robot behavior with two modalities: 1) a text-to-speech (TTS) engine capable of various delivery styles, and 2) a library of physical actions for the robot. We develop a custom, state-of-the-art emotion recognition model to dynamically select the robot's tone of voice and utilize emojis from LLM output as cues for generating robot actions. A demo of our system is available here. To illuminate design and implementation issues, we conduct a pilot study where volunteers chat with a social robot using our proposed system, and we analyze their feedback, conducting a rigorous error analysis of chat transcripts. Feedback was overwhelmingly positive, with participants commenting on the robot's empathy, helpfulness, naturalness, and entertainment. Most negative feedback was due to automatic speech recognition (ASR) errors which had limited impact on conversations. However, we observed a small class of errors, such as the LLM repeating itself or hallucinating fictitious information and human responses, that have the potential to derail conversations, raising important issues for LLM application.
* Accepted as Late Breaking Report (LBR) at the 19th Annual ACM/IEEE International Conference on Human Robot Interaction (HRI '24)
Teach Me How to Improve My Argumentation Skills: A Survey on Feedback in Argumentation
Jul 28, 2023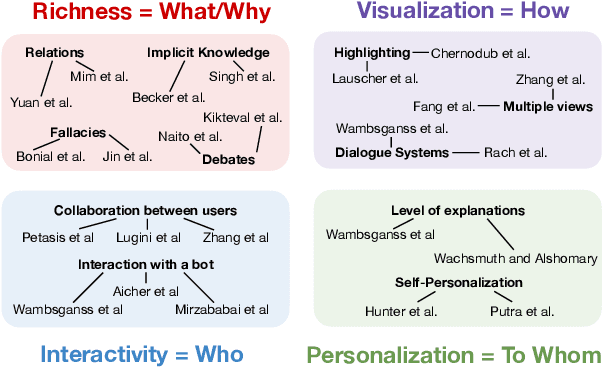
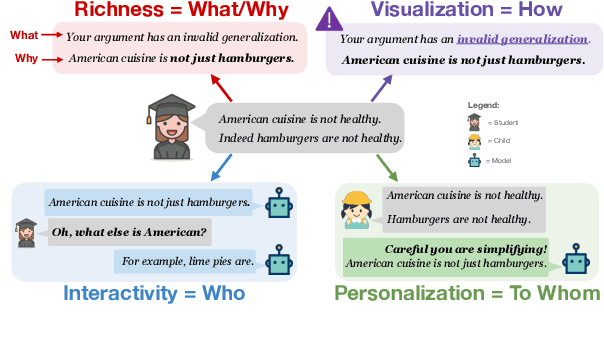
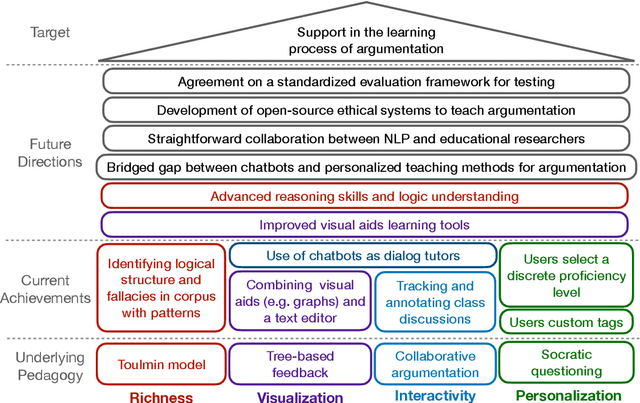
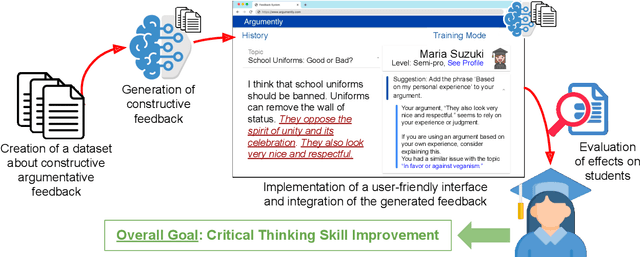
The use of argumentation in education has been shown to improve critical thinking skills for end-users such as students, and computational models for argumentation have been developed to assist in this process. Although these models are useful for evaluating the quality of an argument, they oftentimes cannot explain why a particular argument is considered poor or not, which makes it difficult to provide constructive feedback to users to strengthen their critical thinking skills. In this survey, we aim to explore the different dimensions of feedback (Richness, Visualization, Interactivity, and Personalization) provided by the current computational models for argumentation, and the possibility of enhancing the power of explanations of such models, ultimately helping learners improve their critical thinking skills.
A Comparative Study on Collecting High-Quality Implicit Reasonings at a Large-scale
Apr 16, 2021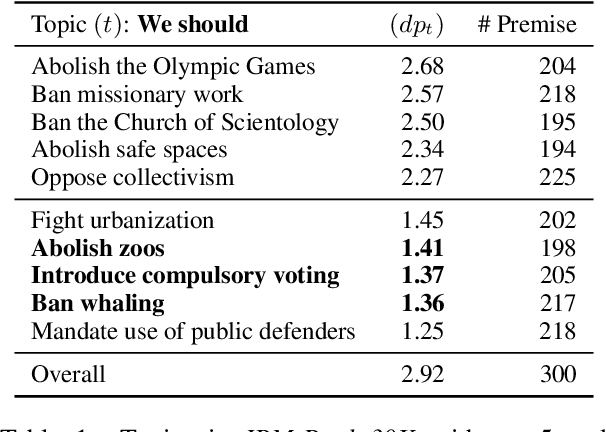

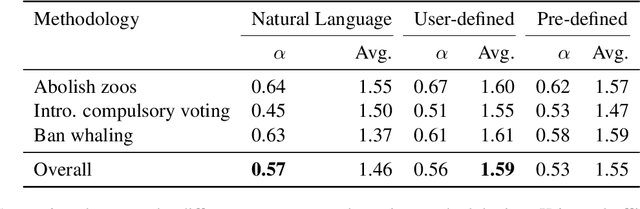

Explicating implicit reasoning (i.e. warrants) in arguments is a long-standing challenge for natural language understanding systems. While recent approaches have focused on explicating warrants via crowdsourcing or expert annotations, the quality of warrants has been questionable due to the extreme complexity and subjectivity of the task. In this paper, we tackle the complex task of warrant explication and devise various methodologies for collecting warrants. We conduct an extensive study with trained experts to evaluate the resulting warrants of each methodology and find that our methodologies allow for high-quality warrants to be collected. We construct a preliminary dataset of 6,000 warrants annotated over 600 arguments for 3 debatable topics. To facilitate research in related downstream tasks, we release our guidelines and preliminary dataset.
Corruption Is Not All Bad: Incorporating Discourse Structure into Pre-training via Corruption for Essay Scoring
Oct 13, 2020
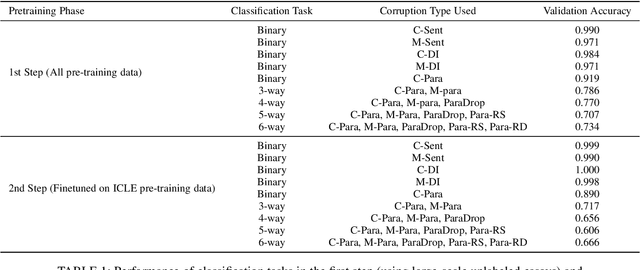
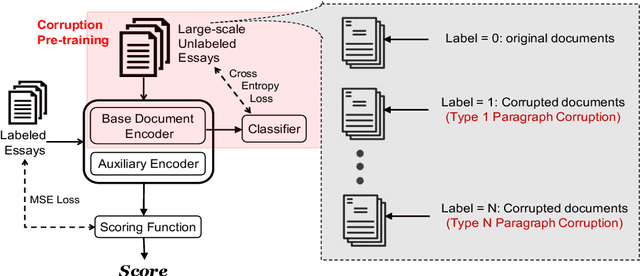
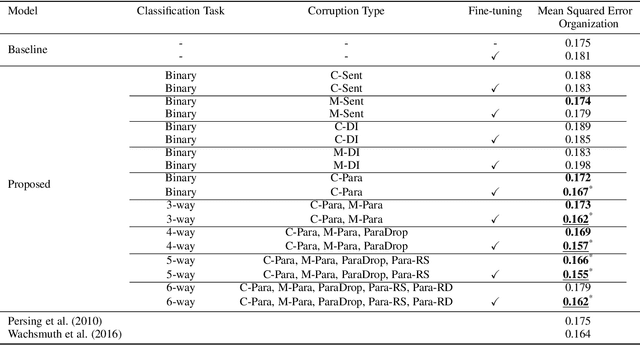
Existing approaches for automated essay scoring and document representation learning typically rely on discourse parsers to incorporate discourse structure into text representation. However, the performance of parsers is not always adequate, especially when they are used on noisy texts, such as student essays. In this paper, we propose an unsupervised pre-training approach to capture discourse structure of essays in terms of coherence and cohesion that does not require any discourse parser or annotation. We introduce several types of token, sentence and paragraph-level corruption techniques for our proposed pre-training approach and augment masked language modeling pre-training with our pre-training method to leverage both contextualized and discourse information. Our proposed unsupervised approach achieves new state-of-the-art result on essay Organization scoring task.
When Choosing Plausible Alternatives, Clever Hans can be Clever
Nov 01, 2019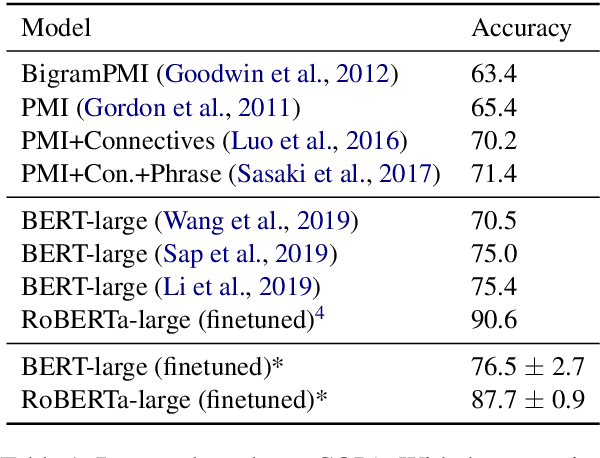
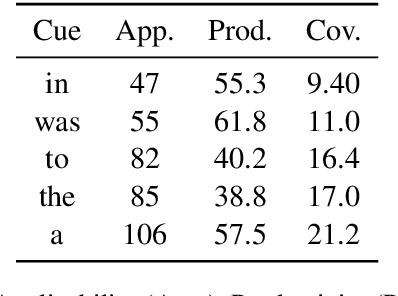
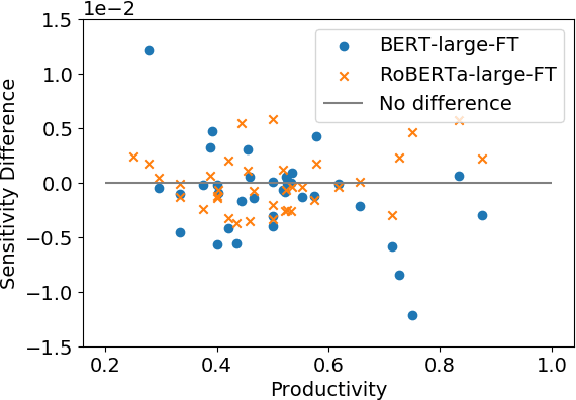

Pretrained language models, such as BERT and RoBERTa, have shown large improvements in the commonsense reasoning benchmark COPA. However, recent work found that many improvements in benchmarks of natural language understanding are not due to models learning the task, but due to their increasing ability to exploit superficial cues, such as tokens that occur more often in the correct answer than the wrong one. Are BERT's and RoBERTa's good performance on COPA also caused by this? We find superficial cues in COPA, as well as evidence that BERT exploits these cues. To remedy this problem, we introduce Balanced COPA, an extension of COPA that does not suffer from easy-to-exploit single token cues. We analyze BERT's and RoBERTa's performance on original and Balanced COPA, finding that BERT relies on superficial cues when they are present, but still achieves comparable performance once they are made ineffective, suggesting that BERT learns the task to a certain degree when forced to. In contrast, RoBERTa does not appear to rely on superficial cues.
Riposte! A Large Corpus of Counter-Arguments
Oct 08, 2019

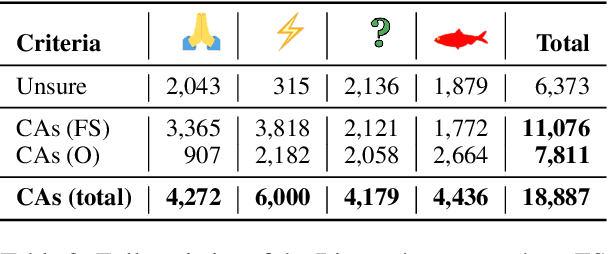

Constructive feedback is an effective method for improving critical thinking skills. Counter-arguments (CAs), one form of constructive feedback, have been proven to be useful for critical thinking skills. However, little work has been done for constructing a large-scale corpus of them which can drive research on automatic generation of CAs for fallacious micro-level arguments (i.e. a single claim and premise pair). In this work, we cast providing constructive feedback as a natural language processing task and create Riposte!, a corpus of CAs, towards this goal. Produced by crowdworkers, Riposte! contains over 18k CAs. We instruct workers to first identify common fallacy types and produce a CA which identifies the fallacy. We analyze how workers create CAs and construct a baseline model based on our analysis.
A Corpus of Deep Argumentative Structures as an Explanation to Argumentative Relations
Dec 07, 2017
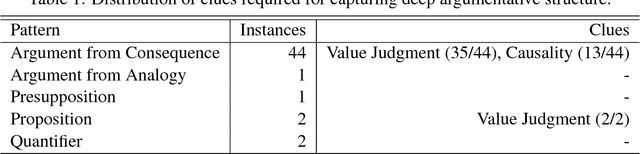
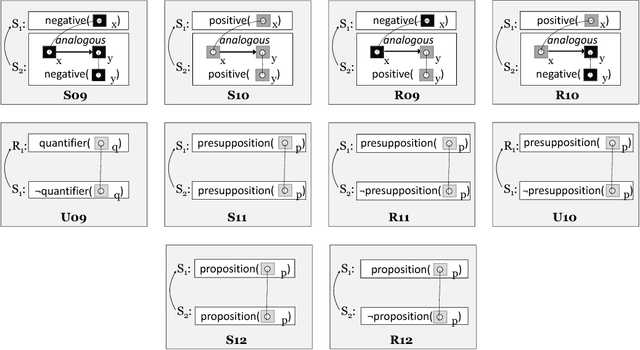
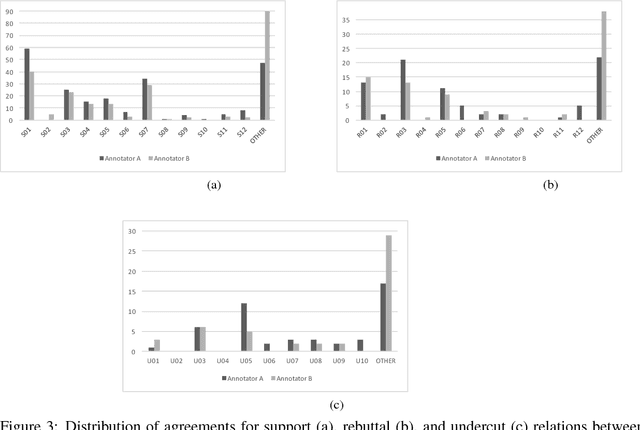
In this paper, we compose a new task for deep argumentative structure analysis that goes beyond shallow discourse structure analysis. The idea is that argumentative relations can reasonably be represented with a small set of predefined patterns. For example, using value judgment and bipolar causality, we can explain a support relation between two argumentative segments as follows: Segment 1 states that something is good, and Segment 2 states that it is good because it promotes something good when it happens. We are motivated by the following questions: (i) how do we formulate the task?, (ii) can a reasonable pattern set be created?, and (iii) do the patterns work? To examine the task feasibility, we conduct a three-stage, detailed annotation study using 357 argumentative relations from the argumentative microtext corpus, a small, but highly reliable corpus. We report the coverage of explanations captured by our patterns on a test set composed of 270 relations. Our coverage result of 74.6% indicates that argumentative relations can reasonably be explained by our small pattern set. Our agreement result of 85.9% shows that a reasonable inter-annotator agreement can be achieved. To assist with future work in computational argumentation, the annotated corpus is made publicly available.