 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorruption Is Not All Bad: Incorporating Discourse Structure into Pre-training via Corruption for Essay Scoring
Paper and Code
Oct 13, 2020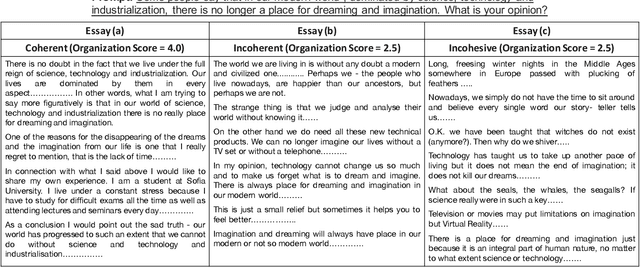
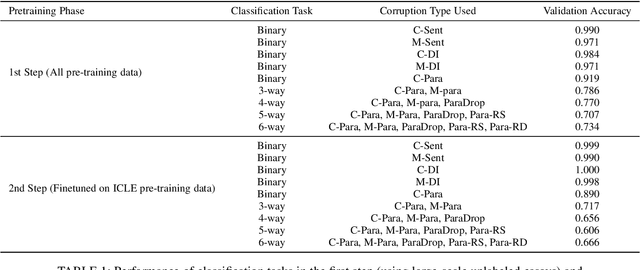
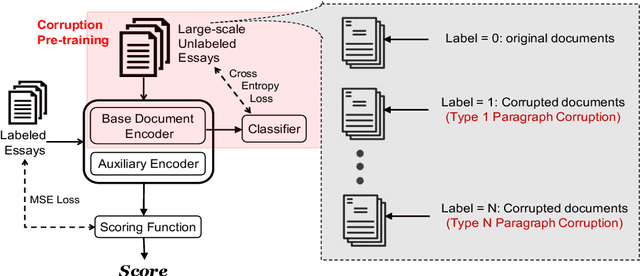
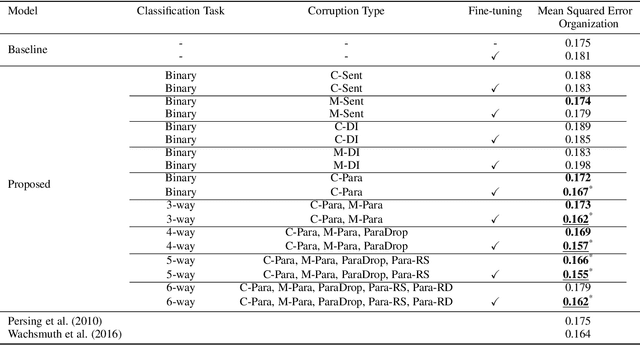
Existing approaches for automated essay scoring and document representation learning typically rely on discourse parsers to incorporate discourse structure into text representation. However, the performance of parsers is not always adequate, especially when they are used on noisy texts, such as student essays. In this paper, we propose an unsupervised pre-training approach to capture discourse structure of essays in terms of coherence and cohesion that does not require any discourse parser or annotation. We introduce several types of token, sentence and paragraph-level corruption techniques for our proposed pre-training approach and augment masked language modeling pre-training with our pre-training method to leverage both contextualized and discourse information. Our proposed unsupervised approach achieves new state-of-the-art result on essay Organization scoring task.