 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Me How to Improve My Argumentation Skills: A Survey on Feedback in Argumentation
Jul 28, 2023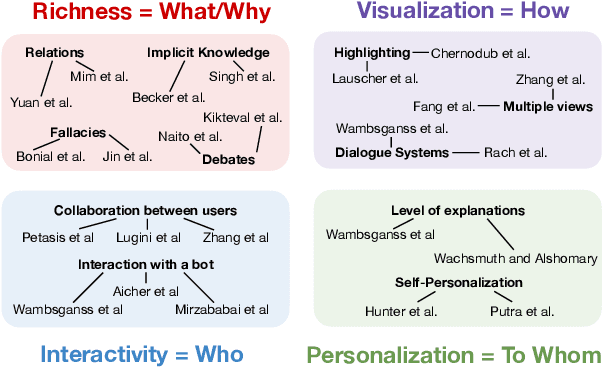
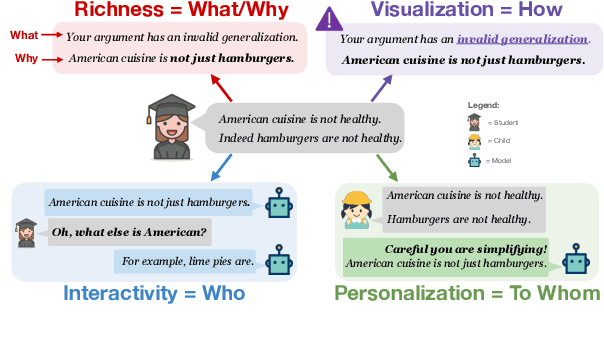
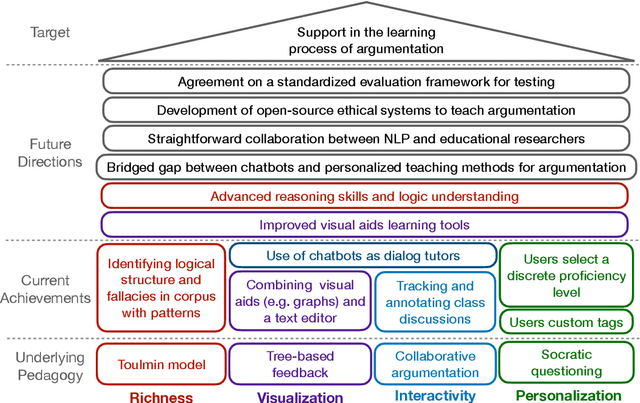
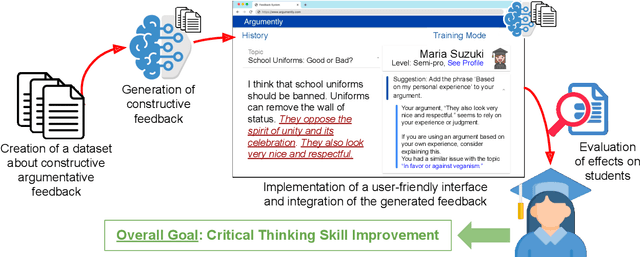
The use of argumentation in education has been shown to improve critical thinking skills for end-users such as students, and computational models for argumentation have been developed to assist in this process. Although these models are useful for evaluating the quality of an argument, they oftentimes cannot explain why a particular argument is considered poor or not, which makes it difficult to provide constructive feedback to users to strengthen their critical thinking skills. In this survey, we aim to explore the different dimensions of feedback (Richness, Visualization, Interactivity, and Personalization) provided by the current computational models for argumentation, and the possibility of enhancing the power of explanations of such models, ultimately helping learners improve their critical thinking skills.
LPAttack: A Feasible Annotation Scheme for Capturing Logic Pattern of Attacks in Arguments
Apr 04, 2022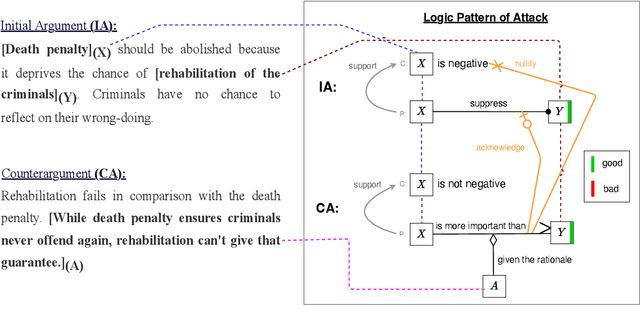
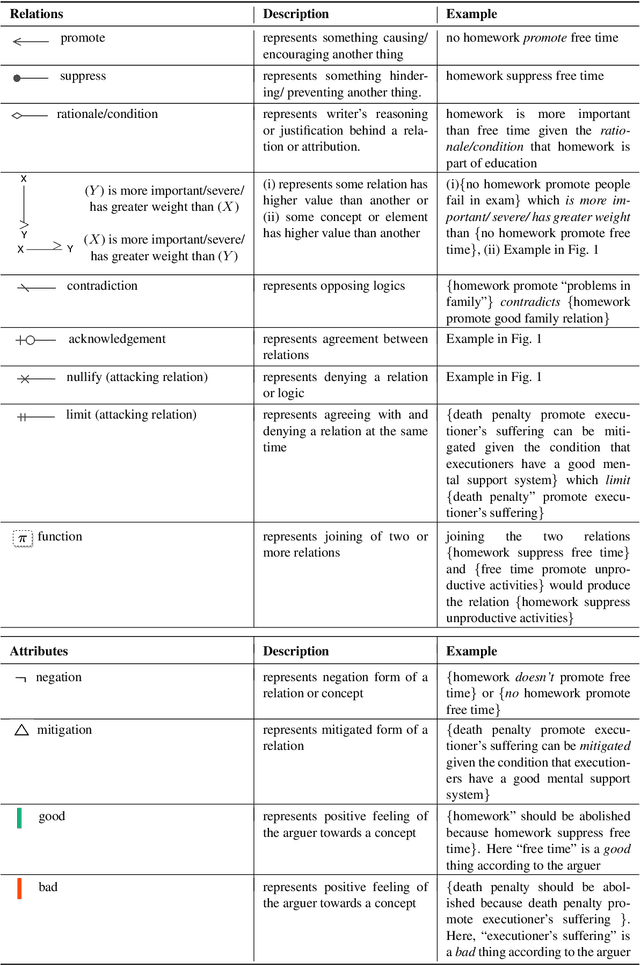
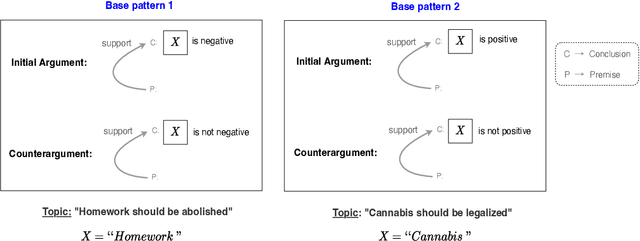

In argumentative discourse, persuasion is often achieved by refuting or attacking others arguments. Attacking is not always straightforward and often comprise complex rhetorical moves such that arguers might agree with a logic of an argument while attacking another logic. Moreover, arguer might neither deny nor agree with any logics of an argument, instead ignore them and attack the main stance of the argument by providing new logics and presupposing that the new logics have more value or importance than the logics present in the attacked argument. However, no existing studies in the computational argumentation capture such complex rhetorical moves in attacks or the presuppositions or value judgements in them. In order to address this gap, we introduce LPAttack, a novel annotation scheme that captures the common modes and complex rhetorical moves in attacks along with the implicit presuppositions and value judgements in them. Our annotation study shows moderate inter-annotator agreement, indicating that human annotation for the proposed scheme is feasible. We publicly release our annotated corpus and the annotation guidelines.
TYPIC: A Corpus of Template-Based Diagnostic Comments on Argumentation
Jan 18, 2022



Providing feedback on the argumentation of learner is essential for development of critical thinking skills, but it takes a lot of time and effort. To reduce the burden on teachers, we aim to automate a process of giving feedback, especially giving diagnostic comments which point out the weaknesses inherent in the argumentation. It is advisable to give specific diagnostic comments so that learners can recognize the diagnosis without misunderstanding. However, it is not obvious how the task of providing specific diagnostic comments should be formulated. We present a formulation of the task as template selection and slot filling to make an automatic evaluation easier and the behavior of the model more tractable. The key to the formulation is the possibility of creating a template set that is sufficient for practical use. In this paper, we define three criteria that a template set should satisfy: expressiveness, informativeness, and uniqueness, and verify the feasibility to create a template set that satisfies these criteria as a first trial. We will show that it is feasible through an annotation study that converts diagnostic comments given in text into a template format. The corpus used in the annotation study is publicly available.
Annotating Implicit Reasoning in Arguments with Causal Links
Oct 26, 2021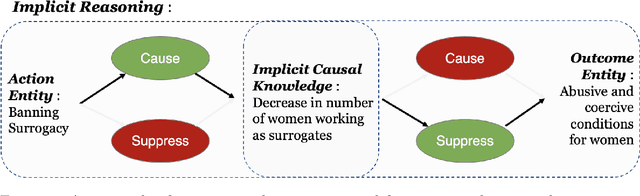

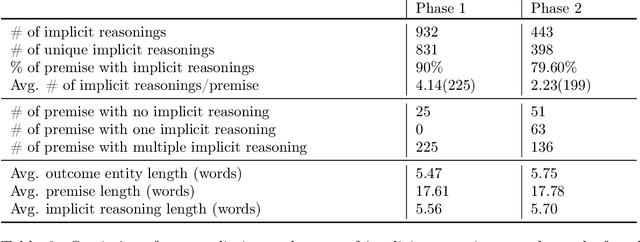
Most of the existing work that focus on the identification of implicit knowledge in arguments generally represent implicit knowledge in the form of commonsense or factual knowledge. However, such knowledge is not sufficient to understand the implicit reasoning link between individual argumentative components (i.e., claim and premise). In this work, we focus on identifying the implicit knowledge in the form of argumentation knowledge which can help in understanding the reasoning link in arguments. Being inspired by the Argument from Consequences scheme, we propose a semi-structured template to represent such argumentation knowledge that explicates the implicit reasoning in arguments via causality. We create a novel two-phase annotation process with simplified guidelines and show how to collect and filter high-quality implicit reasonings via crowdsourcing. We find substantial inter-annotator agreement for quality evaluation between experts, but find evidence that casts a few questions on the feasibility of collecting high-quality semi-structured implicit reasoning through our crowdsourcing process. We release our materials(i.e., crowdsourcing guidelines and collected implicit reasonings) to facilitate further research towards the structured representation of argumentation knowledge.
Corruption Is Not All Bad: Incorporating Discourse Structure into Pre-training via Corruption for Essay Scoring
Oct 13, 2020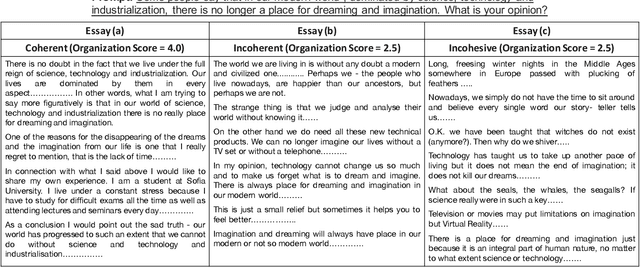
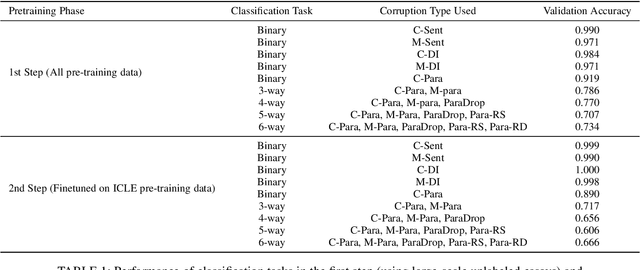
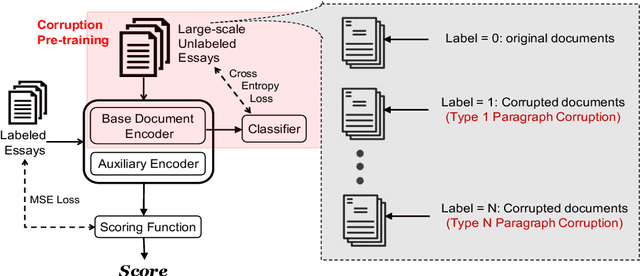
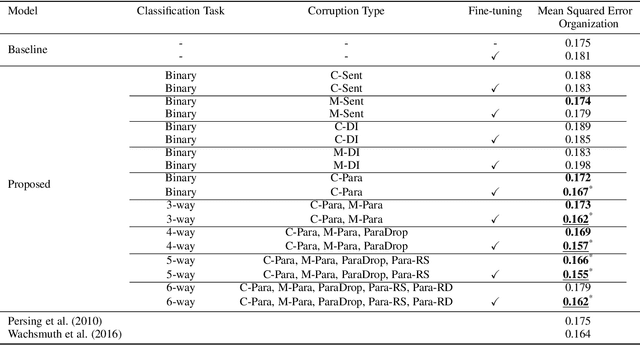
Existing approaches for automated essay scoring and document representation learning typically rely on discourse parsers to incorporate discourse structure into text representation. However, the performance of parsers is not always adequate, especially when they are used on noisy texts, such as student essays. In this paper, we propose an unsupervised pre-training approach to capture discourse structure of essays in terms of coherence and cohesion that does not require any discourse parser or annotation. We introduce several types of token, sentence and paragraph-level corruption techniques for our proposed pre-training approach and augment masked language modeling pre-training with our pre-training method to leverage both contextualized and discourse information. Our proposed unsupervised approach achieves new state-of-the-art result on essay Organization scoring task.