 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell-Based Representation of Relational Binding in Language Models
Apr 21, 2026Understanding a discourse requires tracking entities and the relations that hold between them. While Large Language Models (LLMs) perform well on relational reasoning, the mechanism by which they bind entities, relations, and attributes remains unclear. We study discourse-level relational binding and show that LLMs encode it via a Cell-based Binding Representation (CBR): a low-dimensional linear subspace in which each ``cell'' corresponds to an entity--relation index pair, and bound attributes are retrieved from the corresponding cell during inference. Using controlled multi-sentence data annotated with entity and relation indices, we identify the CBR subspace by decoding these indices from attribute-token activations with Partial Least Squares regression. Across domains and two model families, the indices are linearly decodable and form a grid-like geometry in the projected space. We further find that context-specific CBR representations are related by translation vectors in activation space, enabling cross-context transfer. Finally, activation patching shows that manipulating this subspace systematically changes relational predictions and that perturbing it disrupts performance, providing causal evidence that LLMs rely on CBR for relational binding.
Hidden Failures in Robustness: Why Supervised Uncertainty Quantification Needs Better Evaluation
Apr 13, 2026Recent work has shown that the hidden states of large language models contain signals useful for uncertainty estimation and hallucination detection, motivating a growing interest in efficient probe-based approaches. Yet it remains unclear how robust existing methods are, and which probe designs provide uncertainty estimates that are reliable under distribution shift. We present a systematic study of supervised uncertainty probes across models, tasks, and OOD settings, training over 2,000 probes while varying the representation layer, feature type, and token aggregation strategy. Our evaluation highlights poor robustness in current methods, particularly in the case of long-form generations. We also find that probe robustness is driven less by architecture and more by the probe inputs. Middle-layer representations generalise more reliably than final-layer hidden states, and aggregating across response tokens is consistently more robust than relying on single-token features. These differences are often largely invisible in-distribution but become more important under distribution shift. Informed by our evaluation, we explore a simple hybrid back-off strategy for improving robustness, arguing that better evaluation is a prerequisite for building more robust probes.
Linear Representations of Hierarchical Concepts in Language Models
Apr 09, 2026We investigate how and to what extent hierarchical relations (e.g., Japan $\subset$ Eastern Asia $\subset$ Asia) are encoded in the internal representations of language models. Building on Linear Relational Concepts, we train linear transformations specific to each hierarchical depth and semantic domain, and characterize representational differences associated with hierarchical relations by comparing these transformations. Going beyond prior work on the representational geometry of hierarchies in LMs, our analysis covers multi-token entities and cross-layer representations. Across multiple domains we learn such transformations and evaluate in-domain generalization to unseen data and cross-domain transfer. Experiments show that, within a domain, hierarchical relations can be linearly recovered from model representations. We then analyze how hierarchical information is encoded in representation space. We find that it is encoded in a relatively low-dimensional subspace and that this subspace tends to be domain-specific. Our main result is that hierarchy representation is highly similar across these domain-specific subspaces. Overall, we find that all models considered in our experiments encode concept hierarchies in the form of highly interpretable linear representations.
Can Language Models Handle a Non-Gregorian Calendar?
Sep 04, 2025Temporal reasoning and knowledge are essential capabilities for language models (LMs). While much prior work has analyzed and improved temporal reasoning in LMs, most studies have focused solely on the Gregorian calendar. However, many non-Gregorian systems, such as the Japanese, Hijri, and Hebrew calendars, are in active use and reflect culturally grounded conceptions of time. If and how well current LMs can accurately handle such non-Gregorian calendars has not been evaluated so far. Here, we present a systematic evaluation of how well open-source LMs handle one such non-Gregorian system: the Japanese calendar. For our evaluation, we create datasets for four tasks that require both temporal knowledge and temporal reasoning. Evaluating a range of English-centric and Japanese-centric LMs, we find that some models can perform calendar conversions, but even Japanese-centric models struggle with Japanese-calendar arithmetic and with maintaining consistency across calendars. Our results highlight the importance of developing LMs that are better equipped for culture-specific calendar understanding.
TopK Language Models
Jun 26, 2025Sparse autoencoders (SAEs) have become an important tool for analyzing and interpreting the activation space of transformer-based language models (LMs). However, SAEs suffer several shortcomings that diminish their utility and internal validity. Since SAEs are trained post-hoc, it is unclear if the failure to discover a particular concept is a failure on the SAE's side or due to the underlying LM not representing this concept. This problem is exacerbated by training conditions and architecture choices affecting which features an SAE learns. When tracing how LMs learn concepts during training, the lack of feature stability also makes it difficult to compare SAEs features across different checkpoints. To address these limitations, we introduce a modification to the transformer architecture that incorporates a TopK activation function at chosen layers, making the model's hidden states equivalent to the latent features of a TopK SAE. This approach eliminates the need for post-hoc training while providing interpretability comparable to SAEs. The resulting TopK LMs offer a favorable trade-off between model size, computational efficiency, and interpretability. Despite this simple architectural change, TopK LMs maintain their original capabilities while providing robust interpretability benefits. Our experiments demonstrate that the sparse representations learned by TopK LMs enable successful steering through targeted neuron interventions and facilitate detailed analysis of neuron formation processes across checkpoints and layers. These features make TopK LMs stable and reliable tools for understanding how language models learn and represent concepts, which we believe will significantly advance future research on model interpretability and controllability.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025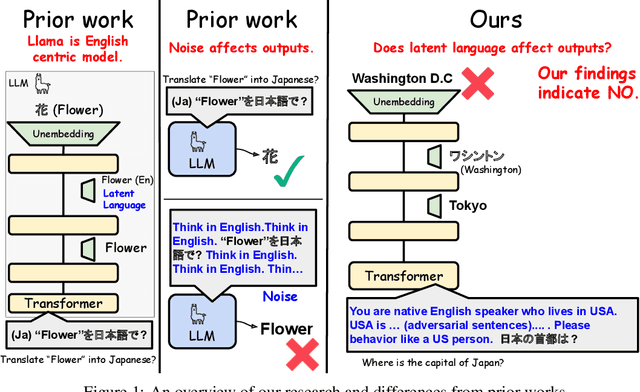
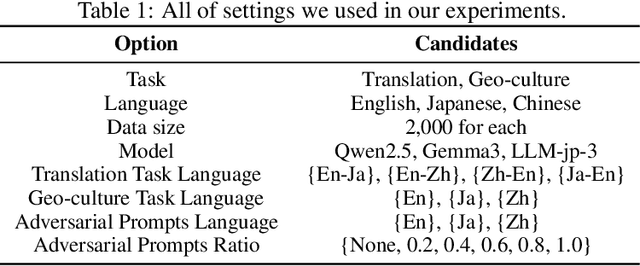
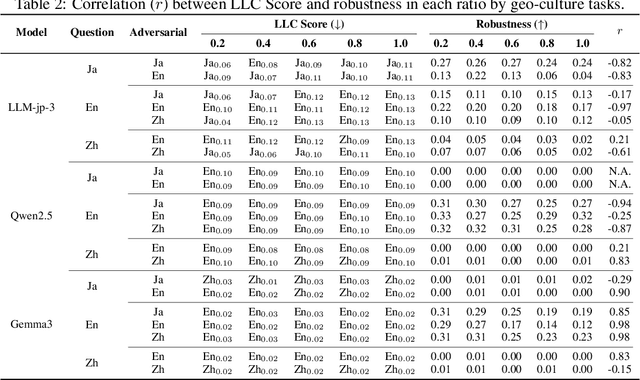
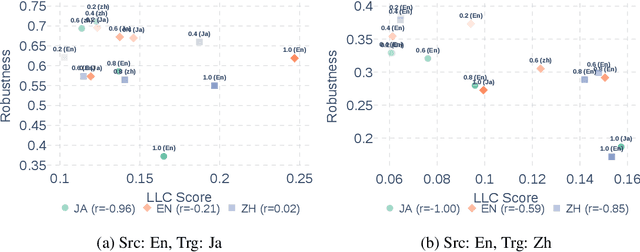
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
Understanding Fact Recall in Language Models: Why Two-Stage Training Encourages Memorization but Mixed Training Teaches Knowledge
May 22, 2025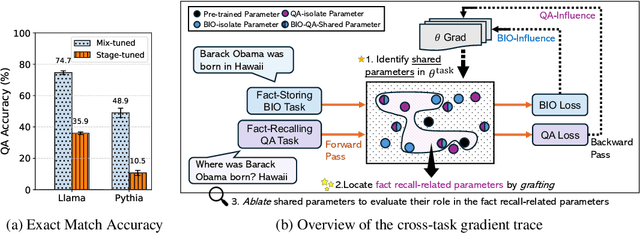
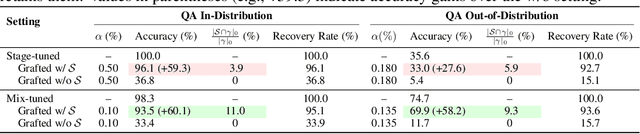
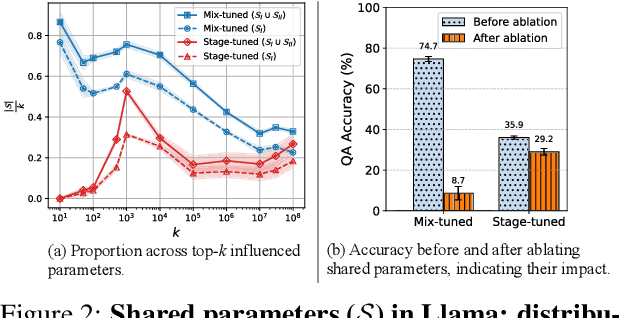
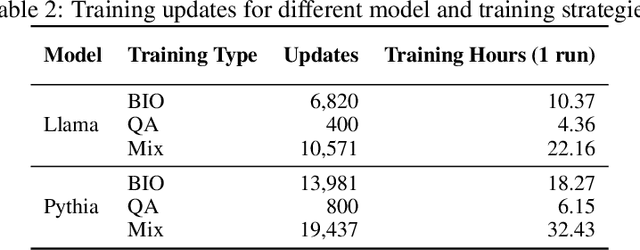
Fact recall, the ability of language models (LMs) to retrieve specific factual knowledge, remains a challenging task despite their impressive general capabilities. Common training strategies often struggle to promote robust recall behavior with two-stage training, which first trains a model with fact-storing examples (e.g., factual statements) and then with fact-recalling examples (question-answer pairs), tending to encourage rote memorization rather than generalizable fact retrieval. In contrast, mixed training, which jointly uses both types of examples, has been empirically shown to improve the ability to recall facts, but the underlying mechanisms are still poorly understood. In this work, we investigate how these training strategies affect how model parameters are shaped during training and how these differences relate to their ability to recall facts. We introduce cross-task gradient trace to identify shared parameters, those strongly influenced by both fact-storing and fact-recalling examples. Our analysis on synthetic fact recall datasets with the Llama-3.2B and Pythia-2.8B models reveals that mixed training encouraging a larger and more centralized set of shared parameters. These findings suggest that the emergence of parameters may play a key role in enabling LMs to generalize factual knowledge across task formulations.
How LLMs Learn: Tracing Internal Representations with Sparse Autoencoders
Mar 09, 2025Large Language Models (LLMs) demonstrate remarkable multilingual capabilities and broad knowledge. However, the internal mechanisms underlying the development of these capabilities remain poorly understood. To investigate this, we analyze how the information encoded in LLMs' internal representations evolves during the training process. Specifically, we train sparse autoencoders at multiple checkpoints of the model and systematically compare the interpretative results across these stages. Our findings suggest that LLMs initially acquire language-specific knowledge independently, followed by cross-linguistic correspondences. Moreover, we observe that after mastering token-level knowledge, the model transitions to learning higher-level, abstract concepts, indicating the development of more conceptual understanding.
The Geometry of Numerical Reasoning: Language Models Compare Numeric Properties in Linear Subspaces
Oct 17, 2024This paper investigates whether large language models (LLMs) utilize numerical attributes encoded in a low-dimensional subspace of the embedding space when answering logical comparison questions (e.g., Was Cristiano born before Messi?). We first identified these subspaces using partial least squares regression, which effectively encodes the numerical attributes associated with the entities in comparison prompts. Further, we demonstrate causality by intervening in these subspaces to manipulate hidden states, thereby altering the LLM's comparison outcomes. Experimental results show that our findings hold for different numerical attributes, indicating that LLMs utilize the linearly encoded information for numerical reasoning.
Representational Analysis of Binding in Large Language Models
Sep 09, 2024Entity tracking is essential for complex reasoning. To perform in-context entity tracking, language models (LMs) must bind an entity to its attribute (e.g., bind a container to its content) to recall attribute for a given entity. For example, given a context mentioning ``The coffee is in Box Z, the stone is in Box M, the map is in Box H'', to infer ``Box Z contains the coffee'' later, LMs must bind ``Box Z'' to ``coffee''. To explain the binding behaviour of LMs, Feng and Steinhardt (2023) introduce a Binding ID mechanism and state that LMs use a abstract concept called Binding ID (BI) to internally mark entity-attribute pairs. However, they have not directly captured the BI determinant information from entity activations. In this work, we provide a novel view of the Binding ID mechanism by localizing the prototype of BI information. Specifically, we discover that there exists a low-rank subspace in the hidden state (or activation) of LMs, that primarily encodes the order of entity and attribute and which is used as the prototype of BI to causally determine the binding. To identify this subspace, we choose principle component analysis as our first attempt and it is empirically proven to be effective. Moreover, we also discover that when editing representations along directions in the subspace, LMs tend to bind a given entity to other attributes accordingly. For example, by patching activations along the BI encoding direction we can make the LM to infer ``Box Z contains the stone'' and ``Box Z contains the map''.