 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: No Retroactive Cure for Infringement during Training
Apr 20, 2026As generative AI faces intensifying legal challenges, the machine learning community has increasingly relied on post-hoc mitigation -- especially machine unlearning and inference-time guardrails -- to argue for compliance. This paper argues that such post-hoc mitigation methods cannot retroactively cure liability from unlawful acquisition and training, because compliance hinges on data lineage, not the outputs. Our argument has three parts. First, unauthorized copying/ingestion can be a legally complete completed act, and model weights may operate as fixed copies that retain training-derived expressive value, making later filtering beside the point for infringement. Second, contract and tort/unfair-competition rules -- via licenses, terms of service, and anti-free-riding principles -- can independently restrict access and use, often bypassing copyright defenses (e.g., fair use or TDM exceptions). Third, since value from protected inputs can persist in weights, remedies such as unjust enrichment and disgorgement may require stripping gains and, in some cases, reaching the model itself. We therefore argue for a shift from Post-Hoc Sanitization to verifiable Ex-Ante Process Compliance.
Exclusive Unlearning
Apr 07, 2026When introducing Large Language Models (LLMs) into industrial applications, such as healthcare and education, the risk of generating harmful content becomes a significant challenge. While existing machine unlearning methods can erase specific harmful knowledge and expressions, diverse harmful content makes comprehensive removal difficult. In this study, instead of individually listing targets for forgetting, we propose Exclusive Unlearning (EU), which aims for broad harm removal by extensively forgetting everything except for the knowledge and expressions we wish to retain. We demonstrate that through Exclusive Unlearning, it is possible to obtain a model that ensures safety against a wide range of inputs, including jailbreaks, while maintaining the ability to respond to diverse instructions related to specific domains such as medicine and mathematics.
Investigating Training and Generalization in Faithful Self-Explanations of Large Language Models
Dec 08, 2025Large language models have the potential to generate explanations for their own predictions in a variety of styles based on user instructions. Recent research has examined whether these self-explanations faithfully reflect the models' actual behavior and has found that they often lack faithfulness. However, the question of how to improve faithfulness remains underexplored. Moreover, because different explanation styles have superficially distinct characteristics, it is unclear whether improvements observed in one style also arise when using other styles. This study analyzes the effects of training for faithful self-explanations and the extent to which these effects generalize, using three classification tasks and three explanation styles. We construct one-word constrained explanations that are likely to be faithful using a feature attribution method, and use these pseudo-faithful self-explanations for continual learning on instruction-tuned models. Our experiments demonstrate that training can improve self-explanation faithfulness across all classification tasks and explanation styles, and that these improvements also show signs of generalization to the multi-word settings and to unseen tasks. Furthermore, we find consistent cross-style generalization among three styles, suggesting that training may contribute to a broader improvement in faithful self-explanation ability.
Instability in Downstream Task Performance During LLM Pretraining
Oct 06, 2025When training large language models (LLMs), it is common practice to track downstream task performance throughout the training process and select the checkpoint with the highest validation score. However, downstream metrics often exhibit substantial fluctuations, making it difficult to identify the checkpoint that truly represents the best-performing model. In this study, we empirically analyze the stability of downstream task performance in an LLM trained on diverse web-scale corpora. We find that task scores frequently fluctuate throughout training, both at the aggregate and example levels. To address this instability, we investigate two post-hoc checkpoint integration methods: checkpoint averaging and ensemble, motivated by the hypothesis that aggregating neighboring checkpoints can reduce performance volatility. We demonstrate both empirically and theoretically that these methods improve downstream performance stability without requiring any changes to the training procedure.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025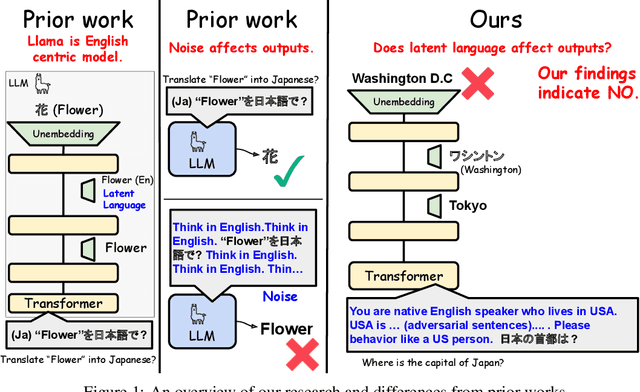
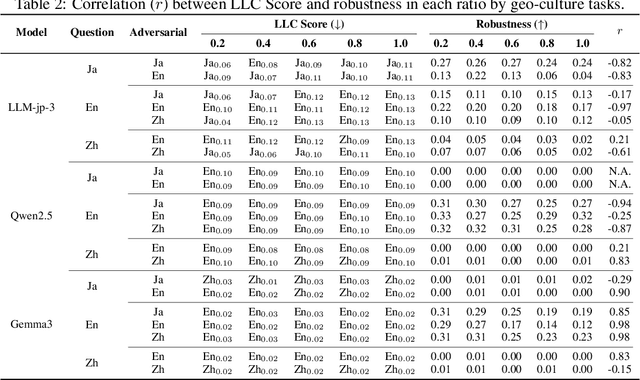
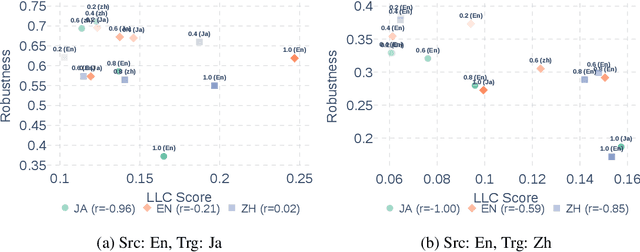
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation
Apr 29, 2025We present UniDetox, a universally applicable method designed to mitigate toxicity across various large language models (LLMs). Previous detoxification methods are typically model-specific, addressing only individual models or model families, and require careful hyperparameter tuning due to the trade-off between detoxification efficacy and language modeling performance. In contrast, UniDetox provides a detoxification technique that can be universally applied to a wide range of LLMs without the need for separate model-specific tuning. Specifically, we propose a novel and efficient dataset distillation technique for detoxification using contrastive decoding. This approach distills detoxifying representations in the form of synthetic text data, enabling universal detoxification of any LLM through fine-tuning with the distilled text. Our experiments demonstrate that the detoxifying text distilled from GPT-2 can effectively detoxify larger models, including OPT, Falcon, and LLaMA-2. Furthermore, UniDetox eliminates the need for separate hyperparameter tuning for each model, as a single hyperparameter configuration can be seamlessly applied across different models. Additionally, analysis of the detoxifying text reveals a reduction in politically biased content, providing insights into the attributes necessary for effective detoxification of LLMs.
What's New in My Data? Novelty Exploration via Contrastive Generation
Oct 18, 2024Fine-tuning is widely used to adapt language models for specific goals, often leveraging real-world data such as patient records, customer-service interactions, or web content in languages not covered in pre-training. These datasets are typically massive, noisy, and often confidential, making their direct inspection challenging. However, understanding them is essential for guiding model deployment and informing decisions about data cleaning or suppressing any harmful behaviors learned during fine-tuning. In this study, we introduce the task of novelty discovery through generation, which aims to identify novel properties of a fine-tuning dataset by generating examples that illustrate these properties. Our approach, Contrastive Generative Exploration (CGE), assumes no direct access to the data but instead relies on a pre-trained model and the same model after fine-tuning. By contrasting the predictions of these two models, CGE can generate examples that highlight novel characteristics of the fine-tuning data. However, this simple approach may produce examples that are too similar to one another, failing to capture the full range of novel phenomena present in the dataset. We address this by introducing an iterative version of CGE, where the previously generated examples are used to update the pre-trained model, and this updated model is then contrasted with the fully fine-tuned model to generate the next example, promoting diversity in the generated outputs. Our experiments demonstrate the effectiveness of CGE in detecting novel content, such as toxic language, as well as new natural and programming languages. Furthermore, we show that CGE remains effective even when models are fine-tuned using differential privacy techniques.
Towards Transfer Unlearning: Empirical Evidence of Cross-Domain Bias Mitigation
Jul 24, 2024


Large language models (LLMs) often inherit biases from vast amounts of training corpora. Traditional debiasing methods, while effective to some extent, do not completely eliminate memorized biases and toxicity in LLMs. In this paper, we study an unlearning-based approach to debiasing in LLMs by performing gradient ascent on hate speech against minority groups, i.e., minimizing the likelihood of biased or toxic content. Specifically, we propose a mask language modeling unlearning technique, which unlearns the harmful part of the text. This method enables LLMs to selectively forget and disassociate from biased and harmful content. Experimental results demonstrate the effectiveness of our approach in diminishing bias while maintaining the language modeling abilities. Surprisingly, the results also unveil an unexpected potential for cross-domain transfer unlearning: debiasing in one bias form (e.g. gender) may contribute to mitigating others (e.g. race and religion).
Topic Modeling for Short Texts with Large Language Models
Jun 02, 2024

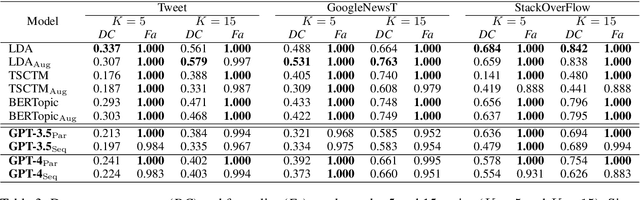

As conventional topic models rely on word co-occurrence to infer latent topics, topic modeling for short texts has been a long-standing challenge. Large Language Models (LLMs) can potentially overcome this challenge by contextually learning the semantics of words via pretraining. This paper studies two approaches, parallel prompting and sequential prompting, to use LLMs for topic modeling. Due to the input length limitations, LLMs cannot process many texts at once. By splitting the texts into smaller subsets and processing them parallelly or sequentially, an arbitrary number of texts can be handled by LLMs. Experimental results demonstrated that our methods can identify more coherent topics than existing ones while maintaining the diversity of the induced topics. Furthermore, we found that the inferred topics adequately covered the input texts, while hallucinated topics were hardly generated.
Unlearning Reveals the Influential Training Data of Language Models
Jan 26, 2024In order to enhance the performance of language models while mitigating the risks of generating harmful content, it is crucial to identify which training dataset affects the model's outputs. Ideally, we can measure the influence of each dataset by removing it from training; however, it is prohibitively expensive to retrain a model multiple times. This paper presents UnTrac, which estimates the influence of a training dataset by unlearning it from the trained model. UnTrac is extremely simple; each training dataset is unlearned by gradient ascent, and we evaluate how much the model's predictions change after unlearning. We empirically examine if our methods can assess the influence of pretraining datasets on generating toxic, biased, and untruthful content. Experimental results demonstrate that our method estimates their influence much more accurately than existing methods while requiring neither excessive memory space nor multiple model checkpoints.