 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophancy Hides Linearly in the Attention Heads
Jan 23, 2026We find that correct-to-incorrect sycophancy signals are most linearly separable within multi-head attention activations. Motivated by the linear representation hypothesis, we train linear probes across the residual stream, multilayer perceptron (MLP), and attention layers to analyze where these signals emerge. Although separability appears in the residual stream and MLPs, steering using these probes is most effective in a sparse subset of middle-layer attention heads. Using TruthfulQA as the base dataset, we find that probes trained on it transfer effectively to other factual QA benchmarks. Furthermore, comparing our discovered direction to previously identified "truthful" directions reveals limited overlap, suggesting that factual accuracy, and deference resistance, arise from related but distinct mechanisms. Attention-pattern analysis further indicates that the influential heads attend disproportionately to expressions of user doubt, contributing to sycophantic shifts. Overall, these findings suggest that sycophancy can be mitigated through simple, targeted linear interventions that exploit the internal geometry of attention activations.
Understanding and Controlling Repetition Neurons and Induction Heads in In-Context Learning
Jul 10, 2025This paper investigates the relationship between large language models' (LLMs) ability to recognize repetitive input patterns and their performance on in-context learning (ICL). In contrast to prior work that has primarily focused on attention heads, we examine this relationship from the perspective of skill neurons, specifically repetition neurons. Our experiments reveal that the impact of these neurons on ICL performance varies depending on the depth of the layer in which they reside. By comparing the effects of repetition neurons and induction heads, we further identify strategies for reducing repetitive outputs while maintaining strong ICL capabilities.
Spelling-out is not Straightforward: LLMs' Capability of Tokenization from Token to Characters
Jun 12, 2025Large language models (LLMs) can spell out tokens character by character with high accuracy, yet they struggle with more complex character-level tasks, such as identifying compositional subcomponents within tokens. In this work, we investigate how LLMs internally represent and utilize character-level information during the spelling-out process. Our analysis reveals that, although spelling out is a simple task for humans, it is not handled in a straightforward manner by LLMs. Specifically, we show that the embedding layer does not fully encode character-level information, particularly beyond the first character. As a result, LLMs rely on intermediate and higher Transformer layers to reconstruct character-level knowledge, where we observe a distinct "breakthrough" in their spelling behavior. We validate this mechanism through three complementary analyses: probing classifiers, identification of knowledge neurons, and inspection of attention weights.
Bit-level BPE: Below the byte boundary
Jun 09, 2025Byte-level fallbacks for subword tokenization have become a common practice in large language models. In particular, it has been demonstrated to be incredibly effective as a pragmatic solution for preventing OOV, especially in the context of larger models. However, breaking a character down to individual bytes significantly increases the sequence length for long-tail tokens in languages such as Chinese, Japanese, and Korean (CJK) and other character-diverse contexts such as emoji. The increased sequence length results in longer computation during both training and inference. In this work, we propose a simple compression technique that reduces the sequence length losslessly.
Do LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025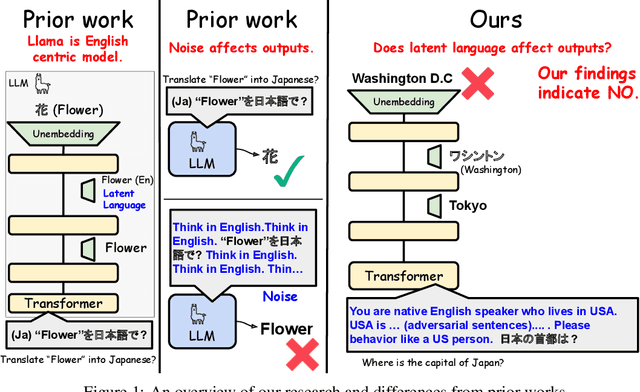
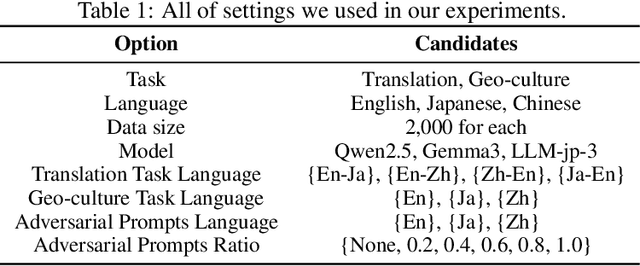
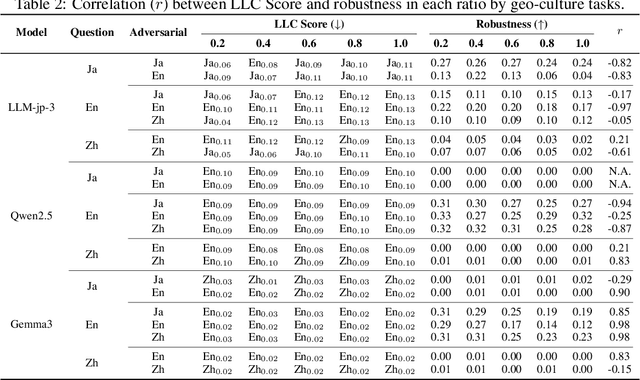
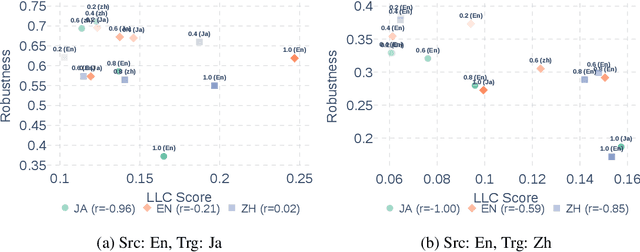
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors
Feb 27, 2025



This paper investigates how LLMs encode inputs with typos. We hypothesize that specific neurons and attention heads recognize typos and fix them internally using local and global contexts. We introduce a method to identify typo neurons and typo heads that work actively when inputs contain typos. Our experimental results suggest the following: 1) LLMs can fix typos with local contexts when the typo neurons in either the early or late layers are activated, even if those in the other are not. 2) Typo neurons in the middle layers are responsible for the core of typo-fixing with global contexts. 3) Typo heads fix typos by widely considering the context not focusing on specific tokens. 4) Typo neurons and typo heads work not only for typo-fixing but also for understanding general contexts.
Number Representations in LLMs: A Computational Parallel to Human Perception
Feb 22, 2025Humans are believed to perceive numbers on a logarithmic mental number line, where smaller values are represented with greater resolution than larger ones. This cognitive bias, supported by neuroscience and behavioral studies, suggests that numerical magnitudes are processed in a sublinear fashion rather than on a uniform linear scale. Inspired by this hypothesis, we investigate whether large language models (LLMs) exhibit a similar logarithmic-like structure in their internal numerical representations. By analyzing how numerical values are encoded across different layers of LLMs, we apply dimensionality reduction techniques such as PCA and PLS followed by geometric regression to uncover latent structures in the learned embeddings. Our findings reveal that the model's numerical representations exhibit sublinear spacing, with distances between values aligning with a logarithmic scale. This suggests that LLMs, much like humans, may encode numbers in a compressed, non-uniform manner.
The Geometry of Numerical Reasoning: Language Models Compare Numeric Properties in Linear Subspaces
Oct 17, 2024This paper investigates whether large language models (LLMs) utilize numerical attributes encoded in a low-dimensional subspace of the embedding space when answering logical comparison questions (e.g., Was Cristiano born before Messi?). We first identified these subspaces using partial least squares regression, which effectively encodes the numerical attributes associated with the entities in comparison prompts. Further, we demonstrate causality by intervening in these subspaces to manipulate hidden states, thereby altering the LLM's comparison outcomes. Experimental results show that our findings hold for different numerical attributes, indicating that LLMs utilize the linearly encoded information for numerical reasoning.
Repetition Neurons: How Do Language Models Produce Repetitions?
Oct 17, 2024This paper introduces repetition neurons, regarded as skill neurons responsible for the repetition problem in text generation tasks. These neurons are progressively activated more strongly as repetition continues, indicating that they perceive repetition as a task to copy the previous context repeatedly, similar to in-context learning. We identify these repetition neurons by comparing activation values before and after the onset of repetition in texts generated by recent pre-trained language models. We analyze the repetition neurons in three English and one Japanese pre-trained language models and observe similar patterns across them.
SubRegWeigh: Effective and Efficient Annotation Weighing with Subword Regularization
Sep 10, 2024


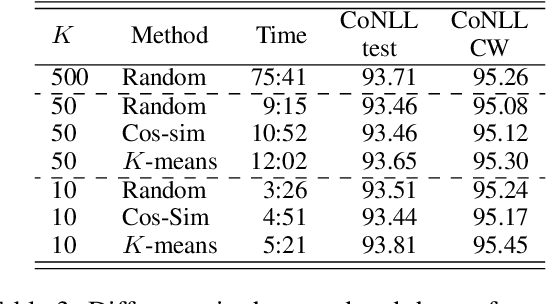
Many datasets of natural language processing (NLP) sometimes include annotation errors. Researchers have attempted to develop methods to reduce the adverse effect of errors in datasets automatically. However, an existing method is time-consuming because it requires many trained models to detect errors. We propose a novel method to reduce the time of error detection. Specifically, we use a tokenization technique called subword regularization to create pseudo-multiple models which are used to detect errors. Our proposed method, SubRegWeigh, can perform annotation weighting four to five times faster than the existing method. Additionally, SubRegWeigh improved performance in both document classification and named entity recognition tasks. In experiments with pseudo-incorrect labels, pseudo-incorrect labels were adequately detected.