 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubRegWeigh: Effective and Efficient Annotation Weighing with Subword Regularization
Paper and Code



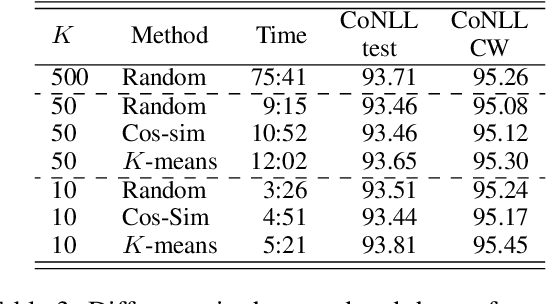
Many datasets of natural language processing (NLP) sometimes include annotation errors. Researchers have attempted to develop methods to reduce the adverse effect of errors in datasets automatically. However, an existing method is time-consuming because it requires many trained models to detect errors. We propose a novel method to reduce the time of error detection. Specifically, we use a tokenization technique called subword regularization to create pseudo-multiple models which are used to detect errors. Our proposed method, SubRegWeigh, can perform annotation weighting four to five times faster than the existing method. Additionally, SubRegWeigh improved performance in both document classification and named entity recognition tasks. In experiments with pseudo-incorrect labels, pseudo-incorrect labels were adequately detected.