 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA thin and soft optical tactile sensor for highly sensitive object perception
Feb 03, 2026Tactile sensing is crucial in robotics and wearable devices for safe perception and interaction with the environment. Optical tactile sensors have emerged as promising solutions, as they are immune to electromagnetic interference and have high spatial resolution. However, existing optical approaches, particularly vision-based tactile sensors, rely on complex optical assemblies that involve lenses and cameras, resulting in bulky, rigid, and alignment-sensitive designs. In this study, we present a thin, compact, and soft optical tactile sensor featuring an alignment-free configuration. The soft optical sensor operates by capturing deformation-induced changes in speckle patterns generated within a soft silicone material, thereby enabling precise force measurements and texture recognition via machine learning. The experimental results show a root-mean-square error of 40 mN in the force measurement and a classification accuracy of 93.33% over nine classes of textured surfaces, including Mahjong tiles. The proposed speckle-based approach provides a compact, easily fabricated, and mechanically compliant platform that bridges optical sensing with flexible shape-adaptive architectures, thereby demonstrating its potential as a novel tactile-sensing paradigm for soft robotics and wearable haptic interfaces.
Investigating Neurons and Heads in Transformer-based LLMs for Typographical Errors
Feb 27, 2025



This paper investigates how LLMs encode inputs with typos. We hypothesize that specific neurons and attention heads recognize typos and fix them internally using local and global contexts. We introduce a method to identify typo neurons and typo heads that work actively when inputs contain typos. Our experimental results suggest the following: 1) LLMs can fix typos with local contexts when the typo neurons in either the early or late layers are activated, even if those in the other are not. 2) Typo neurons in the middle layers are responsible for the core of typo-fixing with global contexts. 3) Typo heads fix typos by widely considering the context not focusing on specific tokens. 4) Typo neurons and typo heads work not only for typo-fixing but also for understanding general contexts.
SubRegWeigh: Effective and Efficient Annotation Weighing with Subword Regularization
Sep 10, 2024


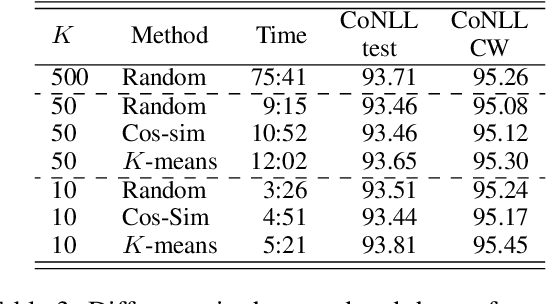
Many datasets of natural language processing (NLP) sometimes include annotation errors. Researchers have attempted to develop methods to reduce the adverse effect of errors in datasets automatically. However, an existing method is time-consuming because it requires many trained models to detect errors. We propose a novel method to reduce the time of error detection. Specifically, we use a tokenization technique called subword regularization to create pseudo-multiple models which are used to detect errors. Our proposed method, SubRegWeigh, can perform annotation weighting four to five times faster than the existing method. Additionally, SubRegWeigh improved performance in both document classification and named entity recognition tasks. In experiments with pseudo-incorrect labels, pseudo-incorrect labels were adequately detected.
Optical hyperdimensional soft sensing: Speckle-based touch interface and tactile sensor
Jan 06, 2024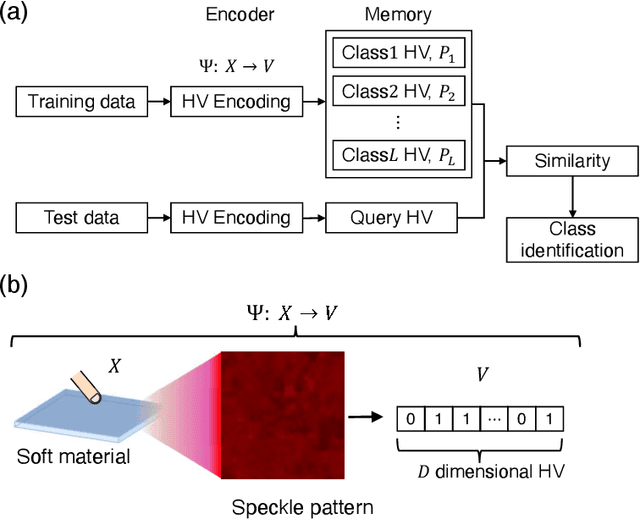
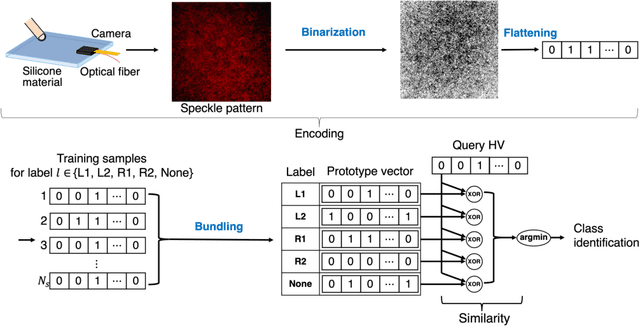
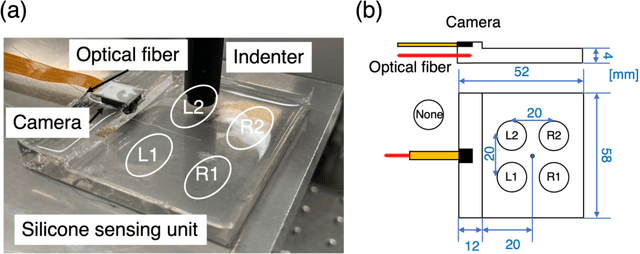
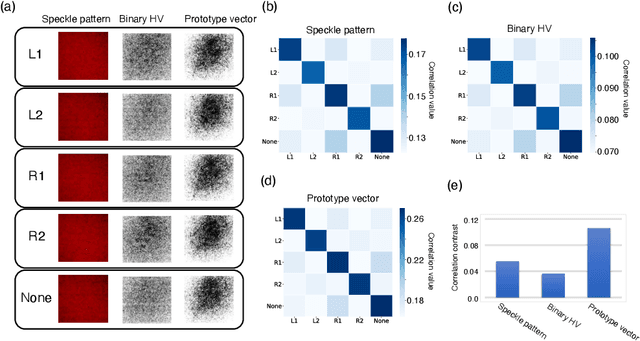
Hyperdimensional computing (HDC) is an emerging computing paradigm that exploits the distributed representation of input data in a hyperdimensional space, the dimensions of which are typically between 1,000--10,000. The hyperdimensional distributed representation enables energy-efficient, low-latency, and noise-robust computations with low-precision and basic arithmetic operations. In this study, we propose optical hyperdimensional distributed representations based on laser speckles for adaptive, efficient, and low-latency optical sensor processing. In the proposed approach, sensory information is optically mapped into a hyperdimensional space with >250,000 dimensions, enabling HDC-based cognitive processing. We use this approach for the processing of a soft-touch interface and a tactile sensor and demonstrate to achieve high accuracy of touch or tactile recognition while significantly reducing training data amount and computational burdens, compared with previous machine-learning-based sensing approaches. Furthermore, we show that this approach enables adaptive recalibration to keep high accuracy even under different conditions.