 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Neurons and Heads in Transformer-based LLMs for Typographical Errors
Feb 27, 2025



This paper investigates how LLMs encode inputs with typos. We hypothesize that specific neurons and attention heads recognize typos and fix them internally using local and global contexts. We introduce a method to identify typo neurons and typo heads that work actively when inputs contain typos. Our experimental results suggest the following: 1) LLMs can fix typos with local contexts when the typo neurons in either the early or late layers are activated, even if those in the other are not. 2) Typo neurons in the middle layers are responsible for the core of typo-fixing with global contexts. 3) Typo heads fix typos by widely considering the context not focusing on specific tokens. 4) Typo neurons and typo heads work not only for typo-fixing but also for understanding general contexts.
SubRegWeigh: Effective and Efficient Annotation Weighing with Subword Regularization
Sep 10, 2024


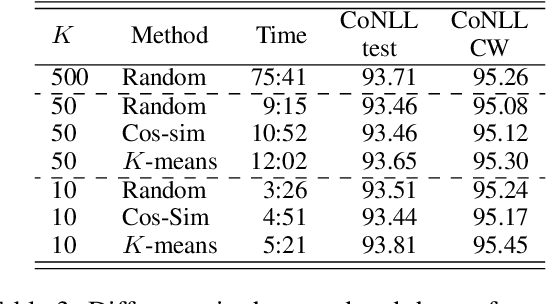
Many datasets of natural language processing (NLP) sometimes include annotation errors. Researchers have attempted to develop methods to reduce the adverse effect of errors in datasets automatically. However, an existing method is time-consuming because it requires many trained models to detect errors. We propose a novel method to reduce the time of error detection. Specifically, we use a tokenization technique called subword regularization to create pseudo-multiple models which are used to detect errors. Our proposed method, SubRegWeigh, can perform annotation weighting four to five times faster than the existing method. Additionally, SubRegWeigh improved performance in both document classification and named entity recognition tasks. In experiments with pseudo-incorrect labels, pseudo-incorrect labels were adequately detected.
Sharing Parameter by Conjugation for Knowledge Graph Embeddings in Complex Space
Apr 18, 2024A Knowledge Graph (KG) is the directed graphical representation of entities and relations in the real world. KG can be applied in diverse Natural Language Processing (NLP) tasks where knowledge is required. The need to scale up and complete KG automatically yields Knowledge Graph Embedding (KGE), a shallow machine learning model that is suffering from memory and training time consumption issues. To mitigate the computational load, we propose a parameter-sharing method, i.e., using conjugate parameters for complex numbers employed in KGE models. Our method improves memory efficiency by 2x in relation embedding while achieving comparable performance to the state-of-the-art non-conjugate models, with faster, or at least comparable, training time. We demonstrated the generalizability of our method on two best-performing KGE models $5^{\bigstar}\mathrm{E}$ and $\mathrm{ComplEx}$ on five benchmark datasets.