 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Interpretation of Smoothing Methods for Negative Sampling Loss Functions in Knowledge Graph Embedding
Jul 05, 2024Knowledge Graphs (KGs) are fundamental resources in knowledge-intensive tasks in NLP. Due to the limitation of manually creating KGs, KG Completion (KGC) has an important role in automatically completing KGs by scoring their links with KG Embedding (KGE). To handle many entities in training, KGE relies on Negative Sampling (NS) loss that can reduce the computational cost by sampling. Since the appearance frequencies for each link are at most one in KGs, sparsity is an essential and inevitable problem. The NS loss is no exception. As a solution, the NS loss in KGE relies on smoothing methods like Self-Adversarial Negative Sampling (SANS) and subsampling. However, it is uncertain what kind of smoothing method is suitable for this purpose due to the lack of theoretical understanding. This paper provides theoretical interpretations of the smoothing methods for the NS loss in KGE and induces a new NS loss, Triplet Adaptive Negative Sampling (TANS), that can cover the characteristics of the conventional smoothing methods. Experimental results of TransE, DistMult, ComplEx, RotatE, HAKE, and HousE on FB15k-237, WN18RR, and YAGO3-10 datasets and their sparser subsets show the soundness of our interpretation and performance improvement by our TANS.
Sharing Parameter by Conjugation for Knowledge Graph Embeddings in Complex Space
Apr 18, 2024A Knowledge Graph (KG) is the directed graphical representation of entities and relations in the real world. KG can be applied in diverse Natural Language Processing (NLP) tasks where knowledge is required. The need to scale up and complete KG automatically yields Knowledge Graph Embedding (KGE), a shallow machine learning model that is suffering from memory and training time consumption issues. To mitigate the computational load, we propose a parameter-sharing method, i.e., using conjugate parameters for complex numbers employed in KGE models. Our method improves memory efficiency by 2x in relation embedding while achieving comparable performance to the state-of-the-art non-conjugate models, with faster, or at least comparable, training time. We demonstrated the generalizability of our method on two best-performing KGE models $5^{\bigstar}\mathrm{E}$ and $\mathrm{ComplEx}$ on five benchmark datasets.
Llama-VITS: Enhancing TTS Synthesis with Semantic Awareness
Apr 12, 2024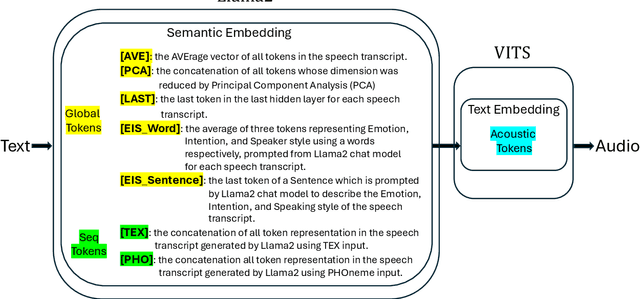



Recent advancements in Natural Language Processing (NLP) have seen Large-scale Language Models (LLMs) excel at producing high-quality text for various purposes. Notably, in Text-To-Speech (TTS) systems, the integration of BERT for semantic token generation has underscored the importance of semantic content in producing coherent speech outputs. Despite this, the specific utility of LLMs in enhancing TTS synthesis remains considerably limited. This research introduces an innovative approach, Llama-VITS, which enhances TTS synthesis by enriching the semantic content of text using LLM. Llama-VITS integrates semantic embeddings from Llama2 with the VITS model, a leading end-to-end TTS framework. By leveraging Llama2 for the primary speech synthesis process, our experiments demonstrate that Llama-VITS matches the naturalness of the original VITS (ORI-VITS) and those incorporate BERT (BERT-VITS), on the LJSpeech dataset, a substantial collection of neutral, clear speech. Moreover, our method significantly enhances emotive expressiveness on the EmoV_DB_bea_sem dataset, a curated selection of emotionally consistent speech from the EmoV_DB dataset, highlighting its potential to generate emotive speech.
Model-based Subsampling for Knowledge Graph Completion
Sep 17, 2023

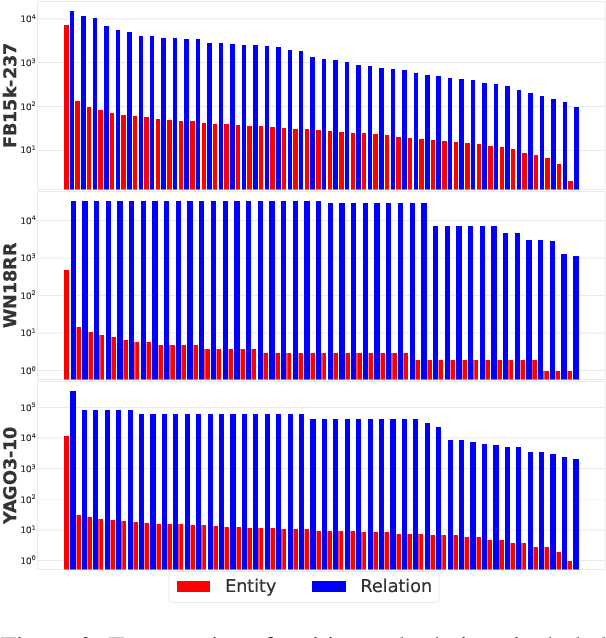

Subsampling is effective in Knowledge Graph Embedding (KGE) for reducing overfitting caused by the sparsity in Knowledge Graph (KG) datasets. However, current subsampling approaches consider only frequencies of queries that consist of entities and their relations. Thus, the existing subsampling potentially underestimates the appearance probabilities of infrequent queries even if the frequencies of their entities or relations are high. To address this problem, we propose Model-based Subsampling (MBS) and Mixed Subsampling (MIX) to estimate their appearance probabilities through predictions of KGE models. Evaluation results on datasets FB15k-237, WN18RR, and YAGO3-10 showed that our proposed subsampling methods actually improved the KG completion performances for popular KGE models, RotatE, TransE, HAKE, ComplEx, and DistMult.