 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Diverse Recommendations via Propensity-Weighted Linear Autoencoders
Dec 24, 2025In real-world recommender systems, user-item interactions are Missing Not At Random (MNAR), as interactions with popular items are more frequently observed than those with less popular ones. Missing observations shift recommendations toward frequently interacted items, which reduces the diversity of the recommendation list. To alleviate this problem, Inverse Propensity Scoring (IPS) is widely used and commonly models propensities based on a power-law function of item interaction frequency. However, we found that such power-law-based correction overly penalizes popular items and harms their recommendation performance. We address this issue by redefining the propensity score to allow broader item recommendation without excessively penalizing popular items. The proposed score is formulated by applying a sigmoid function to the logarithm of the item observation frequency, maintaining the simplicity of power-law scoring while allowing for more flexible adjustment. Furthermore, we incorporate the redefined propensity score into a linear autoencoder model, which tends to favor popular items, and evaluate its effectiveness. Experimental results revealed that our method substantially improves the diversity of items in the recommendation list without sacrificing recommendation accuracy.
* Published in the proceedings of SIGIR-AP'25
From Formal Language Theory to Statistical Learning: Finite Observability of Subregular Languages
Sep 26, 2025We prove that all standard subregular language classes are linearly separable when represented by their deciding predicates. This establishes finite observability and guarantees learnability with simple linear models. Synthetic experiments confirm perfect separability under noise-free conditions, while real-data experiments on English morphology show that learned features align with well-known linguistic constraints. These results demonstrate that the subregular hierarchy provides a rigorous and interpretable foundation for modeling natural language structure. Our code used in real-data experiments is available at https://github.com/UTokyo-HayashiLab/subregular.
Diversity of Transformer Layers: One Aspect of Parameter Scaling Laws
May 29, 2025
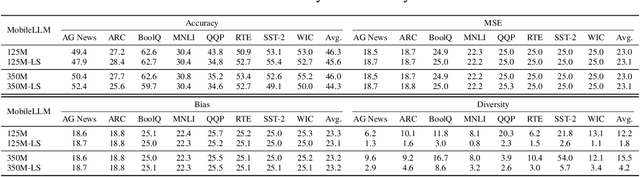


Transformers deliver outstanding performance across a wide range of tasks and are now a dominant backbone architecture for large language models (LLMs). Their task-solving performance is improved by increasing parameter size, as shown in the recent studies on parameter scaling laws. Although recent mechanistic-interpretability studies have deepened our understanding of the internal behavior of Transformers by analyzing their residual stream, the relationship between these internal mechanisms and the parameter scaling laws remains unclear. To bridge this gap, we focus on layers and their size, which mainly decide the parameter size of Transformers. For this purpose, we first theoretically investigate the layers within the residual stream through a bias-diversity decomposition. The decomposition separates (i) bias, the error of each layer's output from the ground truth, and (ii) diversity, which indicates how much the outputs of each layer differ from each other. Analyzing Transformers under this theory reveals that performance improves when individual layers make predictions close to the correct answer and remain mutually diverse. We show that diversity becomes especially critical when individual layers' outputs are far from the ground truth. Finally, we introduce an information-theoretic diversity and show our main findings that adding layers enhances performance only when those layers behave differently, i.e., are diverse. We also reveal the performance gains from increasing the number of layers exhibit submodularity: marginal improvements diminish as additional layers increase, mirroring the logarithmic convergence predicted by the parameter scaling laws. Experiments on multiple semantic-understanding tasks with various LLMs empirically confirm the theoretical properties derived in this study.
TextTIGER: Text-based Intelligent Generation with Entity Prompt Refinement for Text-to-Image Generation
Apr 25, 2025



Generating images from prompts containing specific entities requires models to retain as much entity-specific knowledge as possible. However, fully memorizing such knowledge is impractical due to the vast number of entities and their continuous emergence. To address this, we propose Text-based Intelligent Generation with Entity prompt Refinement (TextTIGER), which augments knowledge on entities included in the prompts and then summarizes the augmented descriptions using Large Language Models (LLMs) to mitigate performance degradation from longer inputs. To evaluate our method, we introduce WiT-Cub (WiT with Captions and Uncomplicated Background-explanations), a dataset comprising captions, images, and an entity list. Experiments on four image generation models and five LLMs show that TextTIGER improves image generation performance in standard metrics (IS, FID, and CLIPScore) compared to caption-only prompts. Additionally, multiple annotators' evaluation confirms that the summarized descriptions are more informative, validating LLMs' ability to generate concise yet rich descriptions. These findings demonstrate that refining prompts with augmented and summarized entity-related descriptions enhances image generation capabilities. The code and dataset will be available upon acceptance.
The Role of Background Information in Reducing Object Hallucination in Vision-Language Models: Insights from Cutoff API Prompting
Feb 21, 2025Vision-Language Models (VLMs) occasionally generate outputs that contradict input images, constraining their reliability in real-world applications. While visual prompting is reported to suppress hallucinations by augmenting prompts with relevant area inside an image, the effectiveness in terms of the area remains uncertain. This study analyzes success and failure cases of Attention-driven visual prompting in object hallucination, revealing that preserving background context is crucial for mitigating object hallucination.
A Simple but Effective Closed-form Solution for Extreme Multi-label Learning
Jan 17, 2025
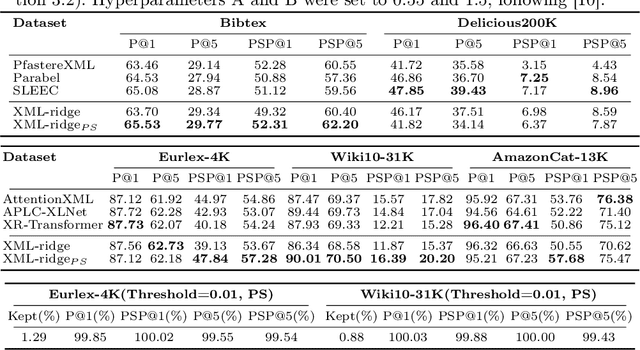
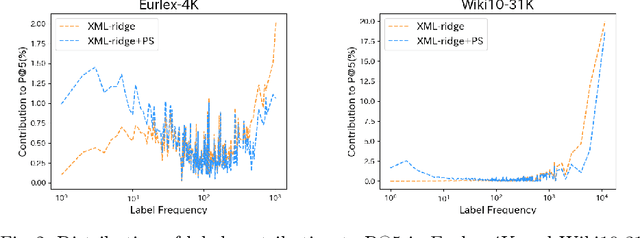
Extreme multi-label learning (XML) is a task of assigning multiple labels from an extremely large set of labels to each data instance. Many current high-performance XML models are composed of a lot of hyperparameters, which complicates the tuning process. Additionally, the models themselves are adapted specifically to XML, which complicates their reimplementation. To remedy this problem, we propose a simple method based on ridge regression for XML. The proposed method not only has a closed-form solution but also is composed of a single hyperparameter. Since there are no precedents on applying ridge regression to XML, this paper verified the performance of the method by using various XML benchmark datasets. Furthermore, we enhanced the prediction of low-frequency labels in XML, which hold informative content. This prediction is essential yet challenging because of the limited amount of data. Here, we employed a simple frequency-based weighting. This approach greatly simplifies the process compared with existing techniques. Experimental results revealed that it can achieve levels of performance comparable to, or even exceeding, those of models with numerous hyperparameters. Additionally, we found that the frequency-based weighting significantly improved the predictive performance for low-frequency labels, while requiring almost no changes in implementation. The source code for the proposed method is available on github at https://github.com/cars1015/XML-ridge.
Can Impressions of Music be Extracted from Thumbnail Images?
Jan 05, 2025



In recent years, there has been a notable increase in research on machine learning models for music retrieval and generation systems that are capable of taking natural language sentences as inputs. However, there is a scarcity of large-scale publicly available datasets, consisting of music data and their corresponding natural language descriptions known as music captions. In particular, non-musical information such as suitable situations for listening to a track and the emotions elicited upon listening is crucial for describing music. This type of information is underrepresented in existing music caption datasets due to the challenges associated with extracting it directly from music data. To address this issue, we propose a method for generating music caption data that incorporates non-musical aspects inferred from music thumbnail images, and validated the effectiveness of our approach through human evaluations. Additionally, we created a dataset with approximately 360,000 captions containing non-musical aspects. Leveraging this dataset, we trained a music retrieval model and demonstrated its effectiveness in music retrieval tasks through evaluation.
Understanding the Impact of Confidence in Retrieval Augmented Generation: A Case Study in the Medical Domain
Dec 29, 2024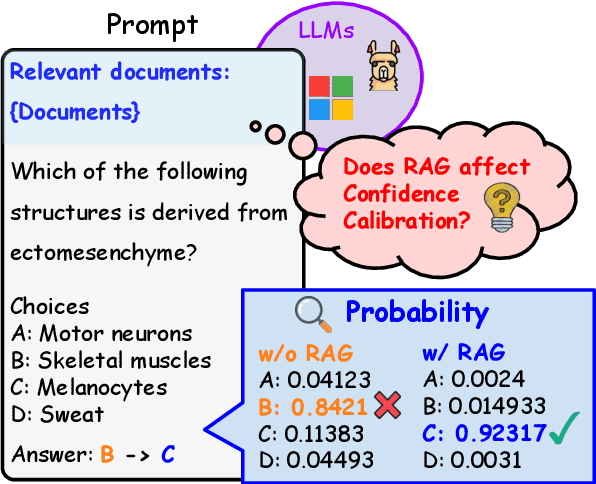



Retrieval Augmented Generation (RAG) complements the knowledge of Large Language Models (LLMs) by leveraging external information to enhance response accuracy for queries. This approach is widely applied in several fields by taking its advantage of injecting the most up-to-date information, and researchers are focusing on understanding and improving this aspect to unlock the full potential of RAG in such high-stakes applications. However, despite the potential of RAG to address these needs, the mechanisms behind the confidence levels of its outputs remain underexplored, although the confidence of information is very critical in some domains, such as finance, healthcare, and medicine. Our study focuses the impact of RAG on confidence within the medical domain under various configurations and models. We evaluate confidence by treating the model's predicted probability as its output and calculating Expected Calibration Error (ECE) and Adaptive Calibration Error (ACE) scores based on the probabilities and accuracy. In addition, we analyze whether the order of retrieved documents within prompts calibrates the confidence. Our findings reveal large variation in confidence and accuracy depending on the model, settings, and the format of input prompts. These results underscore the necessity of optimizing configurations based on the specific model and conditions.
How Panel Layouts Define Manga: Insights from Visual Ablation Experiments
Dec 26, 2024



Today, manga has gained worldwide popularity. However, the question of how various elements of manga, such as characters, text, and panel layouts, reflect the uniqueness of a particular work, or even define it, remains an unexplored area. In this paper, we aim to quantitatively and qualitatively analyze the visual characteristics of manga works, with a particular focus on panel layout features. As a research method, we used facing page images of manga as input to train a deep learning model for predicting manga titles, examining classification accuracy to quantitatively analyze these features. Specifically, we conducted ablation studies by limiting page image information to panel frames to analyze the characteristics of panel layouts. Through a series of quantitative experiments using all 104 works, 12 genres, and 10,122 facing page images from the Manga109 dataset, as well as qualitative analysis using Grad-CAM, our study demonstrates that the uniqueness of manga works is strongly reflected in their panel layouts.
Theoretical Aspects of Bias and Diversity in Minimum Bayes Risk Decoding
Oct 19, 2024



Text generation commonly relies on greedy and beam decoding that limit the search space and degrade output quality. Minimum Bayes Risk (MBR) decoding can mitigate this problem by utilizing automatic evaluation metrics and model-generated pseudo-references. Previous studies have conducted empirical analyses to reveal the improvement by MBR decoding, and reported various observations. However, despite these observations, the theoretical relationship between them remains uncertain. To address this, we present a novel theoretical interpretation of MBR decoding from the perspective of bias-diversity decomposition. We decompose errors in the estimated quality of generated hypotheses in MBR decoding into two key factors: bias, which reflects the closeness between utility functions and human evaluations, and diversity, which represents the variation in the estimated quality of utility functions. Our theoretical analysis reveals the difficulty in simultaneously improving both bias and diversity, and highlights the effectiveness of increasing diversity to enhance MBR decoding performance. This analysis verifies the alignment between our theoretical insights and the empirical results reported in previous work. Furthermore, to support our theoretical findings, we propose a new metric, pseudo-bias, which approximates the bias term using gold references. We also introduce a new MBR approach, Metric-augmented MBR (MAMBR), which increases diversity by adjusting the behavior of utility functions without altering the pseudo-references. Experimental results across multiple NLP tasks show that the decomposed terms in the bias-diversity decomposition correlate well with performance, and that MAMBR improves text generation quality by modifying utility function behavior. Our code will be available at https://github.com/naist-nlp/mbr-bias-diversity.