 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
Jul 09, 2025Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model's acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.
An Empirical Study of LLM-as-a-Judge: How Design Choices Impact Evaluation Reliability
Jun 16, 2025As large language models (LLMs) continue to advance, reliable evaluation methods are essential particularly for open-ended, instruction-following tasks. LLM-as-a-Judge enables automatic evaluation using LLMs as evaluators, but its reliability remains uncertain. In this work, we analyze key factors affecting its trustworthiness, focusing on alignment with human judgments and evaluation consistency. Using BIGGENBench and EvalBiasBench, we study the effects of evaluation design, decoding strategies, and Chain-of-Tought (CoT) reasoning in evaluation. Our results show that evaluation criteria are critical for reliability, non-deterministic sampling improves alignment with human preferences over deterministic evaluation, and CoT reasoning offers minimal gains when clear evaluation criteria are present.
LaMDAgent: An Autonomous Framework for Post-Training Pipeline Optimization via LLM Agents
May 28, 2025Large Language Models (LLMs) have demonstrated exceptional performance across a wide range of tasks. To further tailor LLMs to specific domains or applications, post-training techniques such as Supervised Fine-Tuning (SFT), Preference Learning, and model merging are commonly employed. While each of these methods has been extensively studied in isolation, the automated construction of complete post-training pipelines remains an underexplored area. Existing approaches typically rely on manual design or focus narrowly on optimizing individual components, such as data ordering or merging strategies. In this work, we introduce LaMDAgent (short for Language Model Developing Agent), a novel framework that autonomously constructs and optimizes full post-training pipelines through the use of LLM-based agents. LaMDAgent systematically explores diverse model generation techniques, datasets, and hyperparameter configurations, leveraging task-based feedback to discover high-performing pipelines with minimal human intervention. Our experiments show that LaMDAgent improves tool-use accuracy by 9.0 points while preserving instruction-following capabilities. Moreover, it uncovers effective post-training strategies that are often overlooked by conventional human-driven exploration. We further analyze the impact of data and model size scaling to reduce computational costs on the exploration, finding that model size scalings introduces new challenges, whereas scaling data size enables cost-effective pipeline discovery.
SCAN: Semantic Document Layout Analysis for Textual and Visual Retrieval-Augmented Generation
May 20, 2025With the increasing adoption of Large Language Models (LLMs) and Vision-Language Models (VLMs), rich document analysis technologies for applications like Retrieval-Augmented Generation (RAG) and visual RAG are gaining significant attention. Recent research indicates that using VLMs can achieve better RAG performance, but processing rich documents still remains a challenge since a single page contains large amounts of information. In this paper, we present SCAN (\textbf{S}emanti\textbf{C} Document Layout \textbf{AN}alysis), a novel approach enhancing both textual and visual Retrieval-Augmented Generation (RAG) systems working with visually rich documents. It is a VLM-friendly approach that identifies document components with appropriate semantic granularity, balancing context preservation with processing efficiency. SCAN uses a coarse-grained semantic approach that divides documents into coherent regions covering continuous components. We trained the SCAN model by fine-tuning object detection models with sophisticated annotation datasets. Our experimental results across English and Japanese datasets demonstrate that applying SCAN improves end-to-end textual RAG performance by up to 9.0\% and visual RAG performance by up to 6.4\%, outperforming conventional approaches and even commercial document processing solutions.
LLM-based Query Expansion Fails for Unfamiliar and Ambiguous Queries
May 19, 2025Query expansion (QE) enhances retrieval by incorporating relevant terms, with large language models (LLMs) offering an effective alternative to traditional rule-based and statistical methods. However, LLM-based QE suffers from a fundamental limitation: it often fails to generate relevant knowledge, degrading search performance. Prior studies have focused on hallucination, yet its underlying cause--LLM knowledge deficiencies--remains underexplored. This paper systematically examines two failure cases in LLM-based QE: (1) when the LLM lacks query knowledge, leading to incorrect expansions, and (2) when the query is ambiguous, causing biased refinements that narrow search coverage. We conduct controlled experiments across multiple datasets, evaluating the effects of knowledge and query ambiguity on retrieval performance using sparse and dense retrieval models. Our results reveal that LLM-based QE can significantly degrade the retrieval effectiveness when knowledge in the LLM is insufficient or query ambiguity is high. We introduce a framework for evaluating QE under these conditions, providing insights into the limitations of LLM-based retrieval augmentation.
Mining Hidden Thoughts from Texts: Evaluating Continual Pretraining with Synthetic Data for LLM Reasoning
May 15, 2025Large Language Models (LLMs) have demonstrated significant improvements in reasoning capabilities through supervised fine-tuning and reinforcement learning. However, when training reasoning models, these approaches are primarily applicable to specific domains such as mathematics and programming, which imposes fundamental constraints on the breadth and scalability of training data. In contrast, continual pretraining (CPT) offers the advantage of not requiring task-specific signals. Nevertheless, how to effectively synthesize training data for reasoning and how such data affect a wide range of domains remain largely unexplored. This study provides a detailed evaluation of Reasoning CPT, a form of CPT that uses synthetic data to reconstruct the hidden thought processes underlying texts, based on the premise that texts are the result of the author's thinking process. Specifically, we apply Reasoning CPT to Gemma2-9B using synthetic data with hidden thoughts derived from STEM and Law corpora, and compare it to standard CPT on the MMLU benchmark. Our analysis reveals that Reasoning CPT consistently improves performance across all evaluated domains. Notably, reasoning skills acquired in one domain transfer effectively to others; the performance gap with conventional methods widens as problem difficulty increases, with gains of up to 8 points on the most challenging problems. Furthermore, models trained with hidden thoughts learn to adjust the depth of their reasoning according to problem difficulty.
Can a Crow Hatch a Falcon? Lineage Matters in Predicting Large Language Model Performance
Apr 28, 2025Accurately forecasting the performance of Large Language Models (LLMs) before extensive fine-tuning or merging can substantially reduce both computational expense and development time. Although prior approaches like scaling laws account for global factors such as parameter size or training tokens, they often overlook explicit lineage relationships - i.e., which models are derived or merged from which parents. In this work, we propose a novel Lineage-Regularized Matrix Factorization (LRMF) framework that encodes ancestral ties among LLMs via a graph Laplacian regularizer. By leveraging multi-hop parent-child connections, LRMF consistently outperforms conventional matrix factorization and collaborative filtering methods in both instance-level and benchmark-level performance prediction. Our large-scale study includes 2,934 publicly available Hugging Face models and 21,000+ instances across 6 major benchmarks, showing that lineage constraints yield up to 7-10 percentage points higher correlation with actual performance compared to baselines. Moreover, LRMF effectively addresses the cold-start problem, providing accurate estimates for newly derived or merged models even with minimal data. This lineage-guided strategy thus offers a resource-efficient way to inform hyperparameter tuning, data selection, and model combination in modern LLM development.
DISC: Dynamic Decomposition Improves LLM Inference Scaling
Feb 23, 2025Many inference scaling methods work by breaking a problem into smaller steps (or groups of tokens), then sampling and choosing the best next step. However, these steps and their sizes are usually predetermined based on human intuition or domain knowledge. This paper introduces dynamic decomposition, a method that automatically and adaptively splits solution and reasoning traces into steps during inference. This approach improves computational efficiency by focusing more resources on difficult steps, breaking them down further and prioritizing their sampling. Experiments on coding and math benchmarks (APPS, MATH, and LiveCodeBench) show that dynamic decomposition performs better than static methods, which rely on fixed steps like token-level, sentence-level, or single-step decompositions. These results suggest that dynamic decomposition can enhance many inference scaling techniques.
Understanding the Impact of Confidence in Retrieval Augmented Generation: A Case Study in the Medical Domain
Dec 29, 2024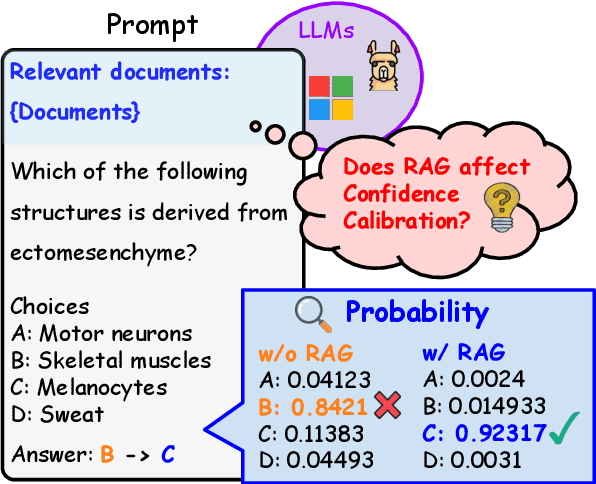



Retrieval Augmented Generation (RAG) complements the knowledge of Large Language Models (LLMs) by leveraging external information to enhance response accuracy for queries. This approach is widely applied in several fields by taking its advantage of injecting the most up-to-date information, and researchers are focusing on understanding and improving this aspect to unlock the full potential of RAG in such high-stakes applications. However, despite the potential of RAG to address these needs, the mechanisms behind the confidence levels of its outputs remain underexplored, although the confidence of information is very critical in some domains, such as finance, healthcare, and medicine. Our study focuses the impact of RAG on confidence within the medical domain under various configurations and models. We evaluate confidence by treating the model's predicted probability as its output and calculating Expected Calibration Error (ECE) and Adaptive Calibration Error (ACE) scores based on the probabilities and accuracy. In addition, we analyze whether the order of retrieved documents within prompts calibrates the confidence. Our findings reveal large variation in confidence and accuracy depending on the model, settings, and the format of input prompts. These results underscore the necessity of optimizing configurations based on the specific model and conditions.
Can Large Language Models Invent Algorithms to Improve Themselves?
Oct 21, 2024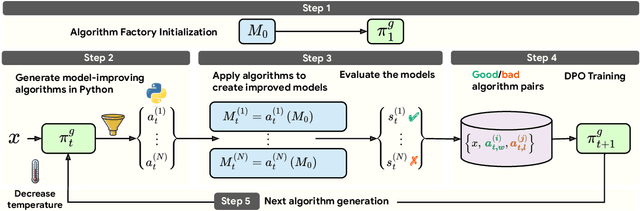
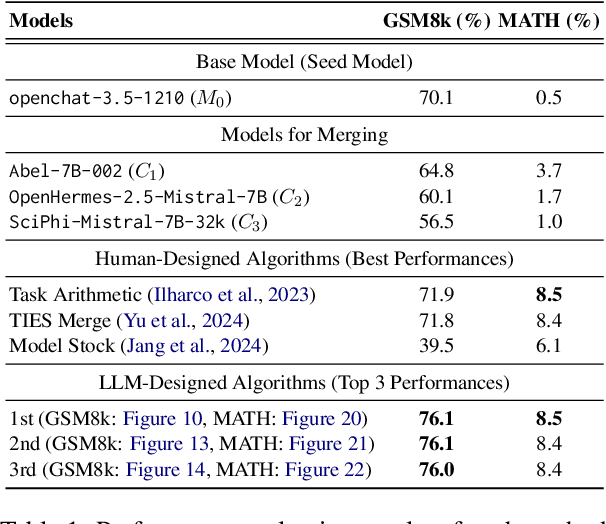
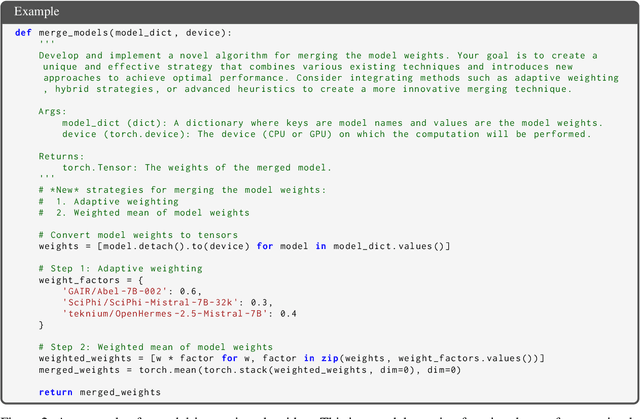
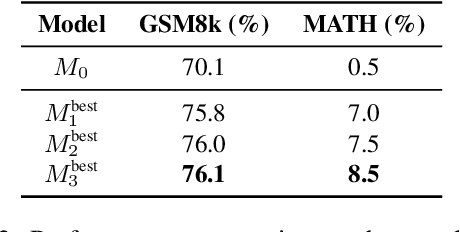
Large Language Models (LLMs) have shown remarkable performance improvements and are rapidly gaining adoption in industry. However, the methods for improving LLMs are still designed by humans, which restricts the invention of new model-improving algorithms to human expertise and imagination. To address this, we propose the Self-Developing framework, which enables LLMs to autonomously generate and learn model-improvement algorithms. In this framework, the seed model generates, applies, and evaluates model-improving algorithms, continuously improving both the seed model and the algorithms themselves. In mathematical reasoning tasks, Self-Developing not only creates models that surpass the seed model but also consistently outperforms models created using human-designed algorithms. Additionally, these LLM-discovered algorithms demonstrate strong effectiveness, including transferability to out-of-domain models.