 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Principled Design of Mixture-of-Experts Language Models under Memory and Inference Constraints
Jan 13, 2026Modern Mixture-of-Experts (MoE) language models are designed based on total parameters (memory footprint) and active parameters (inference cost). However, we find these two factors alone are insufficient to describe an optimal architecture. Through a systematic study, we demonstrate that MoE performance is primarily determined by total parameters ($N_{total}$) and expert sparsity ($s:=n_{exp}/n_{topk}$). Moreover, $n_{exp}$ and $n_{topk}$ do not "cancel out" within the sparsity ratio; instead, a larger total number of experts slightly penalizes performance by forcing a reduction in core model dimensions (depth and width) to meet memory constraints. This motivates a simple principle for MoE design which maximizes $N_{total}$ while minimizing $s$ (maximizing $n_{topk}$) and $n_{exp}$ under the given constraints. Our findings provide a robust framework for resolving architectural ambiguity and guiding MoE design.
Adaptive Layer Selection for Layer-Wise Token Pruning in LLM Inference
Jan 12, 2026Due to the prevalence of large language models (LLMs), key-value (KV) cache reduction for LLM inference has received remarkable attention. Among numerous works that have been proposed in recent years, layer-wise token pruning approaches, which select a subset of tokens at particular layers to retain in KV cache and prune others, are one of the most popular schemes. They primarily adopt a set of pre-defined layers, at which tokens are selected. Such design is inflexible in the sense that the accuracy significantly varies across tasks and deteriorates in harder tasks such as KV retrieval. In this paper, we propose ASL, a training-free method that adaptively chooses the selection layer for KV cache reduction, exploiting the variance of token ranks ordered by attention score. The proposed method balances the performance across different tasks while meeting the user-specified KV budget requirement. ASL operates during the prefilling stage and can be jointly used with existing KV cache reduction methods such as SnapKV to optimize the decoding stage. By evaluations on the InfiniteBench, RULER, and NIAH benchmarks, we show that equipped with one-shot token selection, where tokens are selected at a layer and propagated to deeper layers, ASL outperforms state-of-the-art layer-wise token selection methods in accuracy while maintaining decoding speed and KV cache reduction.
Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
Jul 09, 2025Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model's acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.
SCAN: Semantic Document Layout Analysis for Textual and Visual Retrieval-Augmented Generation
May 20, 2025With the increasing adoption of Large Language Models (LLMs) and Vision-Language Models (VLMs), rich document analysis technologies for applications like Retrieval-Augmented Generation (RAG) and visual RAG are gaining significant attention. Recent research indicates that using VLMs can achieve better RAG performance, but processing rich documents still remains a challenge since a single page contains large amounts of information. In this paper, we present SCAN (\textbf{S}emanti\textbf{C} Document Layout \textbf{AN}alysis), a novel approach enhancing both textual and visual Retrieval-Augmented Generation (RAG) systems working with visually rich documents. It is a VLM-friendly approach that identifies document components with appropriate semantic granularity, balancing context preservation with processing efficiency. SCAN uses a coarse-grained semantic approach that divides documents into coherent regions covering continuous components. We trained the SCAN model by fine-tuning object detection models with sophisticated annotation datasets. Our experimental results across English and Japanese datasets demonstrate that applying SCAN improves end-to-end textual RAG performance by up to 9.0\% and visual RAG performance by up to 6.4\%, outperforming conventional approaches and even commercial document processing solutions.
Jellyfish: A Large Language Model for Data Preprocessing
Dec 05, 2023In this paper, we present Jellyfish, an open-source LLM as a universal task solver for DP. Built on the Llama 2 13B model, Jellyfish is instruction-tuned with the datasets of several typical DP tasks including error detection, data imputation, schema matching, and entity matching, and delivers generalizability to other tasks. Remarkably, Jellyfish can operate on a local, single, and low-priced GPU with its 13 billion parameters, ensuring data security and enabling further tuning. Its proficiency in understanding natural language allows users to manually craft instructions for DP tasks. Unlike many existing methods that heavily rely on prior knowledge, Jellyfish acquires domain knowledge during its tuning process and integrates optional knowledge injection during inference. A distinctive feature of Jellyfish is its interpreter, which elucidates its output decisions. To construct Jellyfish, we develop a series of pre-tuning and DP-tuning techniques. Jellyfish is equipped with an instance serializer, which automatically translates raw data into model prompts, and a knowledge injector, which optionally introduces task- and dataset-specific knowledge to enhance DP performance. Our evaluation of Jellyfish, using a range of real datasets, shows its competitiveness compared to state-of-the-art methods and its strong generalizability to unseen tasks. Jellyfish's performance rivals that of GPT series models, and its interpreter offers enhanced reasoning capabilities compared to GPT-3.5. Furthermore, our evaluation highlights the effectiveness of the techniques employed in constructing Jellyfish. Our model is available at Hugging Face: https://huggingface.co/NECOUDBFM/Jellyfish .
Large Language Models as Data Preprocessors
Aug 30, 2023Large Language Models (LLMs), typified by OpenAI's GPT series and Meta's LLaMA variants, have marked a significant advancement in artificial intelligence. Trained on vast amounts of text data, LLMs are capable of understanding and generating human-like text across a diverse range of topics. This study expands on the applications of LLMs, exploring their potential in data preprocessing, a critical stage in data mining and analytics applications. We delve into the applicability of state-of-the-art LLMs such as GPT-3.5, GPT-4, and Vicuna-13B for error detection, data imputation, schema matching, and entity matching tasks. Alongside showcasing the inherent capabilities of LLMs, we highlight their limitations, particularly in terms of computational expense and inefficiency. We propose an LLM-based framework for data preprocessing, which integrates cutting-edge prompt engineering techniques, coupled with traditional methods like contextualization and feature selection, to improve the performance and efficiency of these models. The effectiveness of LLMs in data preprocessing is evaluated through an experimental study spanning 12 datasets. GPT-4 emerged as a standout, achieving 100\% accuracy or F1 score on 4 datasets, suggesting LLMs' immense potential in these tasks. Despite certain limitations, our study underscores the promise of LLMs in this domain and anticipates future developments to overcome current hurdles.
DeepJoin: Joinable Table Discovery with Pre-trained Language Models
Dec 15, 2022Due to the usefulness in data enrichment for data analysis tasks, joinable table discovery has become an important operation in data lake management. Existing approaches target equi-joins, the most common way of combining tables for creating a unified view, or semantic joins, which tolerate misspellings and different formats to deliver more join results. They are either exact solutions whose running time is linear in the sizes of query column and target table repository or approximate solutions lacking precision. In this paper, we propose Deepjoin, a deep learning model for accurate and efficient joinable table discovery. Our solution is an embedding-based retrieval, which employs a pre-trained language model (PLM) and is designed as one framework serving both equi- and semantic joins. We propose a set of contextualization options to transform column contents to a text sequence. The PLM reads the sequence and is fine-tuned to embed columns to vectors such that columns are expected to be joinable if they are close to each other in the vector space. Since the output of the PLM is fixed in length, the subsequent search procedure becomes independent of the column size. With a state-of-the-art approximate nearest neighbor search algorithm, the search time is logarithmic in the repository size. To train the model, we devise the techniques for preparing training data as well as data augmentation. The experiments on real datasets demonstrate that by training on a small subset of a corpus, Deepjoin generalizes to large datasets and its precision consistently outperforms other approximate solutions'. Deepjoin is even more accurate than an exact solution to semantic joins when evaluated with labels from experts. Moreover, when equipped with a GPU, Deepjoin is up to two orders of magnitude faster than existing solutions.
Table Enrichment System for Machine Learning
Apr 18, 2022
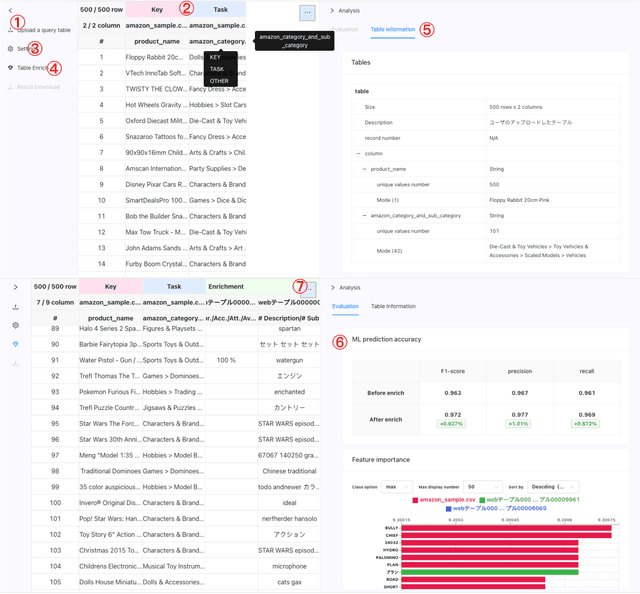

Data scientists are constantly facing the problem of how to improve prediction accuracy with insufficient tabular data. We propose a table enrichment system that enriches a query table by adding external attributes (columns) from data lakes and improves the accuracy of machine learning predictive models. Our system has four stages, join row search, task-related table selection, row and column alignment, and feature selection and evaluation, to efficiently create an enriched table for a given query table and a specified machine learning task. We demonstrate our system with a web UI to show the use cases of table enrichment.