 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Need to Think in One Language? Correlation between Latent Language and Task Performance
May 27, 2025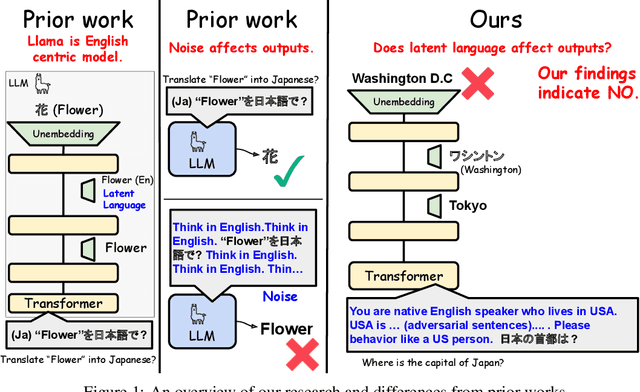
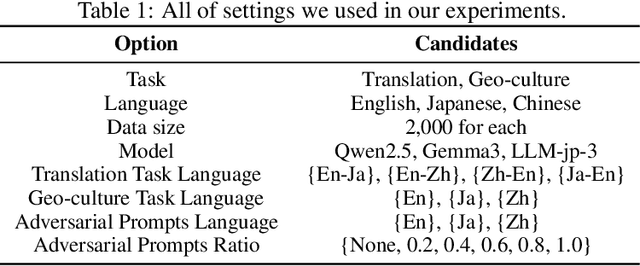
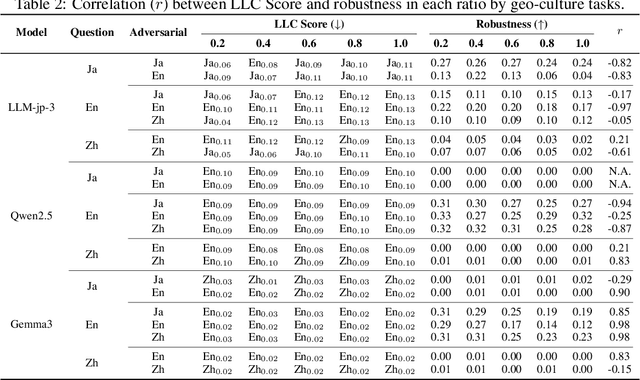
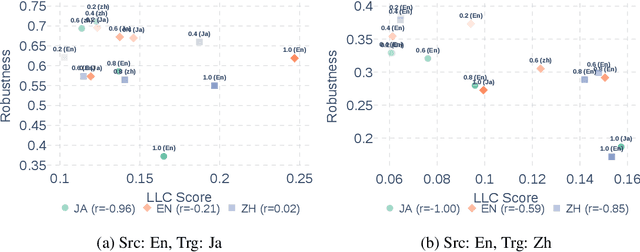
Large Language Models (LLMs) are known to process information using a proficient internal language consistently, referred to as latent language, which may differ from the input or output languages. However, how the discrepancy between the latent language and the input and output language affects downstream task performance remains largely unexplored. While many studies research the latent language of LLMs, few address its importance in influencing task performance. In our study, we hypothesize that thinking in latent language consistently enhances downstream task performance. To validate this, our work varies the input prompt languages across multiple downstream tasks and analyzes the correlation between consistency in latent language and task performance. We create datasets consisting of questions from diverse domains such as translation and geo-culture, which are influenced by the choice of latent language. Experimental results across multiple LLMs on translation and geo-culture tasks, which are sensitive to the choice of language, indicate that maintaining consistency in latent language is not always necessary for optimal downstream task performance. This is because these models adapt their internal representations near the final layers to match the target language, reducing the impact of consistency on overall performance.
Diagnosing Vision Language Models' Perception by Leveraging Human Methods for Color Vision Deficiencies
May 23, 2025Large-scale Vision Language Models (LVLMs) are increasingly being applied to a wide range of real-world multimodal applications, involving complex visual and linguistic reasoning. As these models become more integrated into practical use, they are expected to handle complex aspects of human interaction. Among these, color perception is a fundamental yet highly variable aspect of visual understanding. It differs across individuals due to biological factors such as Color Vision Deficiencies (CVDs), as well as differences in culture and language. Despite its importance, perceptual diversity has received limited attention. In our study, we evaluate LVLMs' ability to account for individual level perceptual variation using the Ishihara Test, a widely used method for detecting CVDs. Our results show that LVLMs can explain CVDs in natural language, but they cannot simulate how people with CVDs perceive color in image based tasks. These findings highlight the need for multimodal systems that can account for color perceptual diversity and support broader discussions on perceptual inclusiveness and fairness in multimodal AI.
TextTIGER: Text-based Intelligent Generation with Entity Prompt Refinement for Text-to-Image Generation
Apr 25, 2025



Generating images from prompts containing specific entities requires models to retain as much entity-specific knowledge as possible. However, fully memorizing such knowledge is impractical due to the vast number of entities and their continuous emergence. To address this, we propose Text-based Intelligent Generation with Entity prompt Refinement (TextTIGER), which augments knowledge on entities included in the prompts and then summarizes the augmented descriptions using Large Language Models (LLMs) to mitigate performance degradation from longer inputs. To evaluate our method, we introduce WiT-Cub (WiT with Captions and Uncomplicated Background-explanations), a dataset comprising captions, images, and an entity list. Experiments on four image generation models and five LLMs show that TextTIGER improves image generation performance in standard metrics (IS, FID, and CLIPScore) compared to caption-only prompts. Additionally, multiple annotators' evaluation confirms that the summarized descriptions are more informative, validating LLMs' ability to generate concise yet rich descriptions. These findings demonstrate that refining prompts with augmented and summarized entity-related descriptions enhances image generation capabilities. The code and dataset will be available upon acceptance.
Understanding the Impact of Confidence in Retrieval Augmented Generation: A Case Study in the Medical Domain
Dec 29, 2024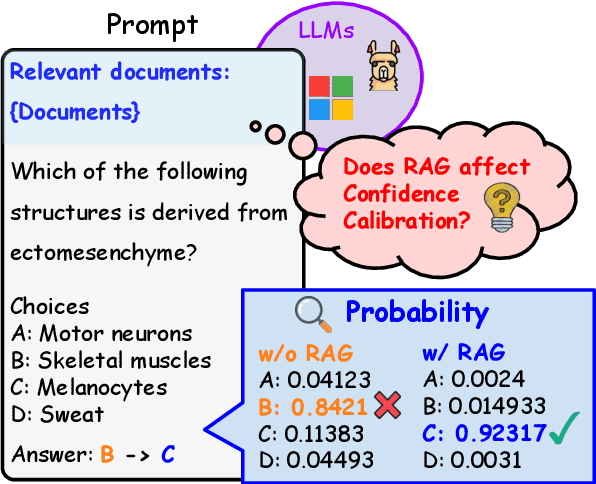



Retrieval Augmented Generation (RAG) complements the knowledge of Large Language Models (LLMs) by leveraging external information to enhance response accuracy for queries. This approach is widely applied in several fields by taking its advantage of injecting the most up-to-date information, and researchers are focusing on understanding and improving this aspect to unlock the full potential of RAG in such high-stakes applications. However, despite the potential of RAG to address these needs, the mechanisms behind the confidence levels of its outputs remain underexplored, although the confidence of information is very critical in some domains, such as finance, healthcare, and medicine. Our study focuses the impact of RAG on confidence within the medical domain under various configurations and models. We evaluate confidence by treating the model's predicted probability as its output and calculating Expected Calibration Error (ECE) and Adaptive Calibration Error (ACE) scores based on the probabilities and accuracy. In addition, we analyze whether the order of retrieved documents within prompts calibrates the confidence. Our findings reveal large variation in confidence and accuracy depending on the model, settings, and the format of input prompts. These results underscore the necessity of optimizing configurations based on the specific model and conditions.
BQA: Body Language Question Answering Dataset for Video Large Language Models
Oct 17, 2024



A large part of human communication relies on nonverbal cues such as facial expressions, eye contact, and body language. Unlike language or sign language, such nonverbal communication lacks formal rules, requiring complex reasoning based on commonsense understanding. Enabling current Video Large Language Models (VideoLLMs) to accurately interpret body language is a crucial challenge, as human unconscious actions can easily cause the model to misinterpret their intent. To address this, we propose a dataset, BQA, a body language question answering dataset, to validate whether the model can correctly interpret emotions from short clips of body language comprising 26 emotion labels of videos of body language. We evaluated various VideoLLMs on BQA and revealed that understanding body language is challenging, and our analyses of the wrong answers by VideoLLMs show that certain VideoLLMs made significantly biased answers depending on the age group and ethnicity of the individuals in the video. The dataset is available.
Beyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Oct 04, 2024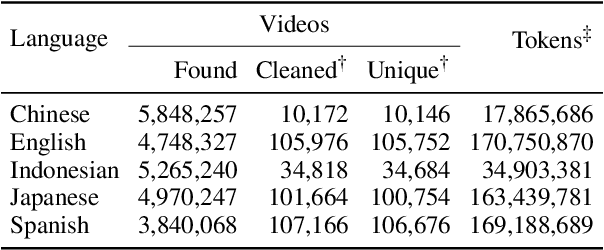
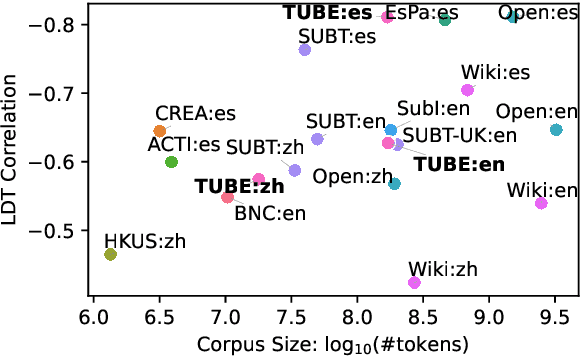
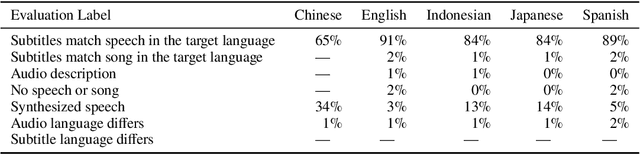
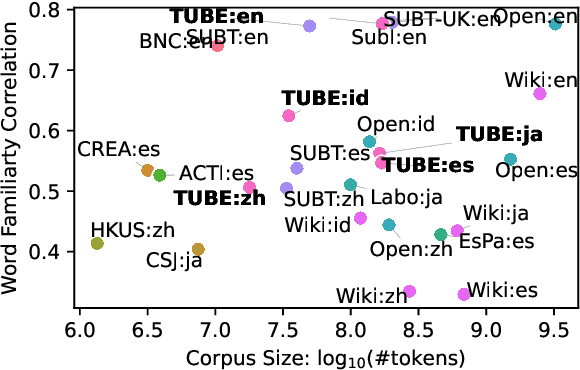
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.
Towards Cross-Lingual Explanation of Artwork in Large-scale Vision Language Models
Sep 03, 2024



As the performance of Large-scale Vision Language Models (LVLMs) improves, they are increasingly capable of responding in multiple languages, and there is an expectation that the demand for explanations generated by LVLMs will grow. However, pre-training of Vision Encoder and the integrated training of LLMs with Vision Encoder are mainly conducted using English training data, leaving it uncertain whether LVLMs can completely handle their potential when generating explanations in languages other than English. In addition, multilingual QA benchmarks that create datasets using machine translation have cultural differences and biases, remaining issues for use as evaluation tasks. To address these challenges, this study created an extended dataset in multiple languages without relying on machine translation. This dataset that takes into account nuances and country-specific phrases was then used to evaluate the generation explanation abilities of LVLMs. Furthermore, this study examined whether Instruction-Tuning in resource-rich English improves performance in other languages. Our findings indicate that LVLMs perform worse in languages other than English compared to English. In addition, it was observed that LVLMs struggle to effectively manage the knowledge learned from English data.
An Implementation of Werewolf Agent That does not Truly Trust LLMs
Sep 03, 2024Werewolf is an incomplete information game, which has several challenges when creating a computer agent as a player given the lack of understanding of the situation and individuality of utterance (e.g., computer agents are not capable of characterful utterance or situational lying). We propose a werewolf agent that solves some of those difficulties by combining a Large Language Model (LLM) and a rule-based algorithm. In particular, our agent uses a rule-based algorithm to select an output either from an LLM or a template prepared beforehand based on the results of analyzing conversation history using an LLM. It allows the agent to refute in specific situations, identify when to end the conversation, and behave with persona. This approach mitigated conversational inconsistencies and facilitated logical utterance as a result. We also conducted a qualitative evaluation, which resulted in our agent being perceived as more human-like compared to an unmodified LLM. The agent is freely available for contributing to advance the research in the field of Werewolf game.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.