 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Paper and Code
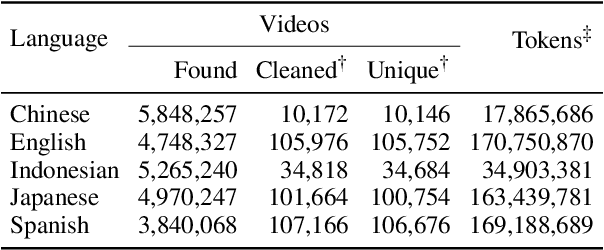
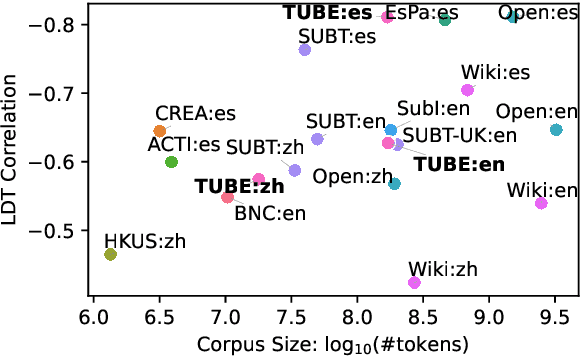
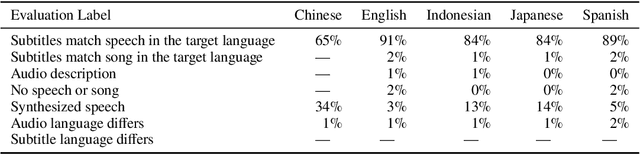
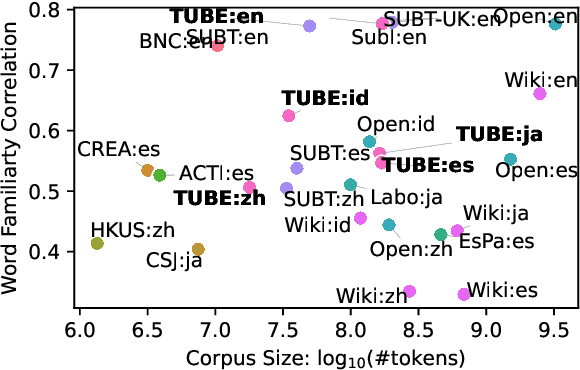
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.