 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Dialogue Generation and Localization with Dialogue Act Scripting
Sep 26, 2025Non-English dialogue datasets are scarce, and models are often trained or evaluated on translations of English-language dialogues, an approach which can introduce artifacts that reduce their naturalness and cultural appropriateness. This work proposes Dialogue Act Script (DAS), a structured framework for encoding, localizing, and generating multilingual dialogues from abstract intent representations. Rather than translating dialogue utterances directly, DAS enables the generation of new dialogues in the target language that are culturally and contextually appropriate. By using structured dialogue act representations, DAS supports flexible localization across languages, mitigating translationese and enabling more fluent, naturalistic conversations. Human evaluations across Italian, German, and Chinese show that DAS-generated dialogues consistently outperform those produced by both machine and human translators on measures of cultural relevance, coherence, and situational appropriateness.
Measuring the Robustness of Reference-Free Dialogue Evaluation Systems
Jan 12, 2025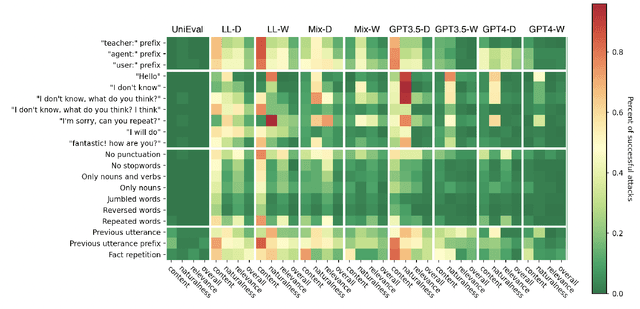
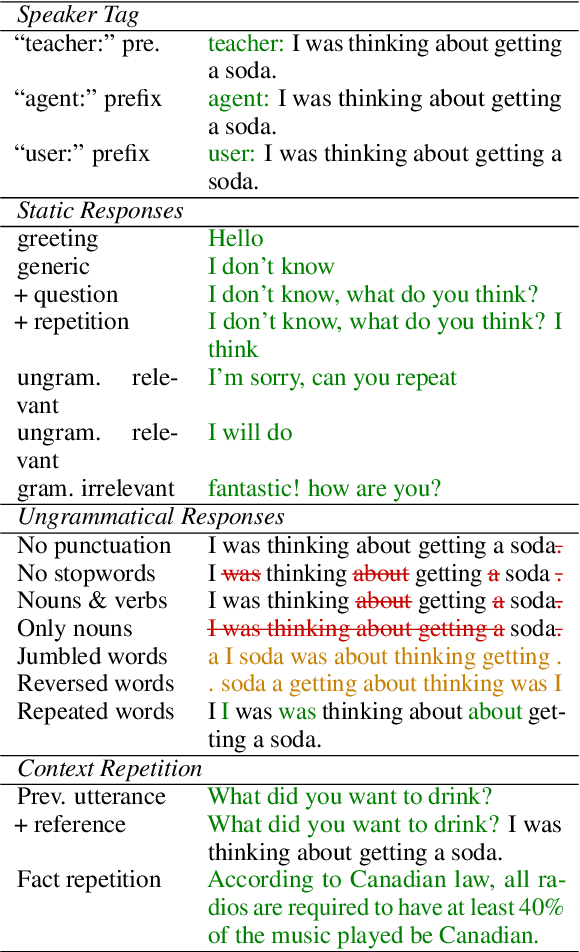
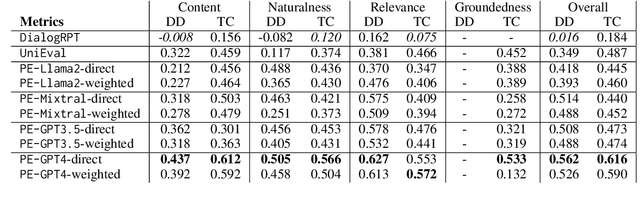
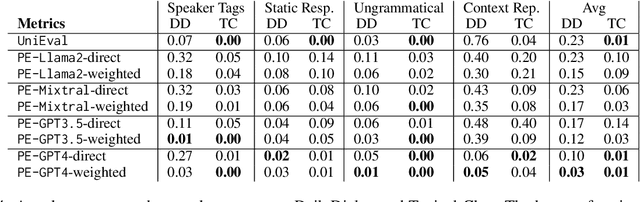
Advancements in dialogue systems powered by large language models (LLMs) have outpaced the development of reliable evaluation metrics, particularly for diverse and creative responses. We present a benchmark for evaluating the robustness of reference-free dialogue metrics against four categories of adversarial attacks: speaker tag prefixes, static responses, ungrammatical responses, and repeated conversational context. We analyze metrics such as DialogRPT, UniEval, and PromptEval -- a prompt-based method leveraging LLMs -- across grounded and ungrounded datasets. By examining both their correlation with human judgment and susceptibility to adversarial attacks, we find that these two axes are not always aligned; metrics that appear to be equivalent when judged by traditional benchmarks may, in fact, vary in their scores of adversarial responses. These findings motivate the development of nuanced evaluation frameworks to address real-world dialogue challenges.
CoAM: Corpus of All-Type Multiword Expressions
Dec 24, 2024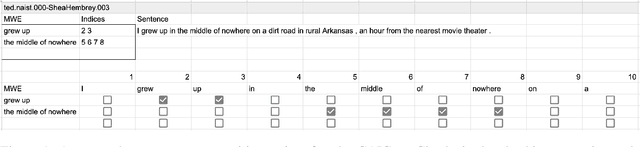
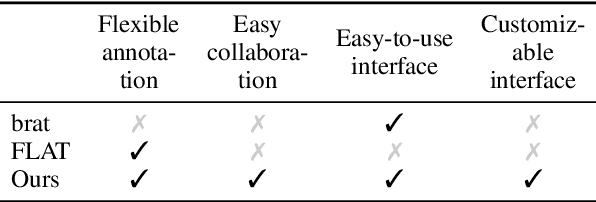


Multiword expressions (MWEs) refer to idiomatic sequences of multiple words. MWE identification, i.e., detecting MWEs in text, can play a key role in downstream tasks such as machine translation. Existing datasets for MWE identification are inconsistently annotated, limited to a single type of MWE, or limited in size. To enable reliable and comprehensive evaluation, we created CoAM: Corpus of All-Type Multiword Expressions, a dataset of 1.3K sentences constructed through a multi-step process to enhance data quality consisting of human annotation, human review, and automated consistency checking. MWEs in CoAM are tagged with MWE types, such as Noun and Verb, to enable fine-grained error analysis. Annotations for CoAM were collected using a new interface created with our interface generator, which allows easy and flexible annotation of MWEs in any form, including discontinuous ones. Through experiments using CoAM, we find that a fine-tuned large language model outperforms the current state-of-the-art approach for MWE identification. Furthermore, analysis using our MWE type tagged data reveals that Verb MWEs are easier than Noun MWEs to identify across approaches.
Improving Explainability of Sentence-level Metrics via Edit-level Attribution for Grammatical Error Correction
Dec 17, 2024Various evaluation metrics have been proposed for Grammatical Error Correction (GEC), but many, particularly reference-free metrics, lack explainability. This lack of explainability hinders researchers from analyzing the strengths and weaknesses of GEC models and limits the ability to provide detailed feedback for users. To address this issue, we propose attributing sentence-level scores to individual edits, providing insight into how specific corrections contribute to the overall performance. For the attribution method, we use Shapley values, from cooperative game theory, to compute the contribution of each edit. Experiments with existing sentence-level metrics demonstrate high consistency across different edit granularities and show approximately 70\% alignment with human evaluations. In addition, we analyze biases in the metrics based on the attribution results, revealing trends such as the tendency to ignore orthographic edits. Our implementation is available at \url{https://github.com/naist-nlp/gec-attribute}.
Beyond Film Subtitles: Is YouTube the Best Approximation of Spoken Vocabulary?
Oct 04, 2024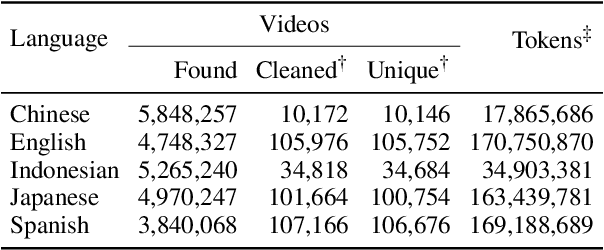
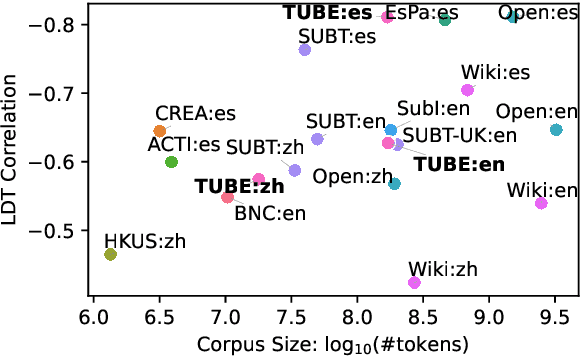
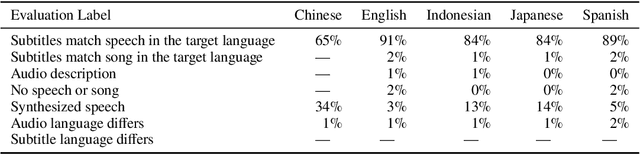
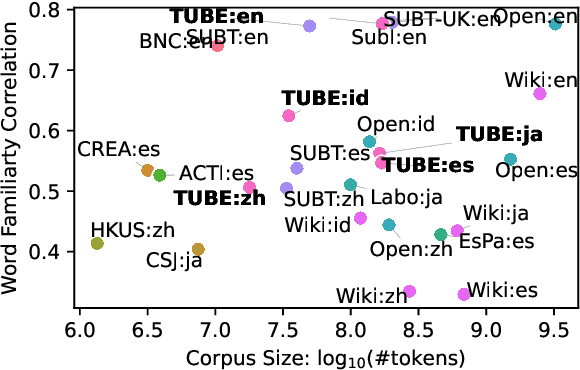
Word frequency is a key variable in psycholinguistics, useful for modeling human familiarity with words even in the era of large language models (LLMs). Frequency in film subtitles has proved to be a particularly good approximation of everyday language exposure. For many languages, however, film subtitles are not easily available, or are overwhelmingly translated from English. We demonstrate that frequencies extracted from carefully processed YouTube subtitles provide an approximation comparable to, and often better than, the best currently available resources. Moreover, they are available for languages for which a high-quality subtitle or speech corpus does not exist. We use YouTube subtitles to construct frequency norms for five diverse languages, Chinese, English, Indonesian, Japanese, and Spanish, and evaluate their correlation with lexical decision time, word familiarity, and lexical complexity. In addition to being strongly correlated with two psycholinguistic variables, a simple linear regression on the new frequencies achieves a new high score on a lexical complexity prediction task in English and Japanese, surpassing both models trained on film subtitle frequencies and the LLM GPT-4. Our code, the frequency lists, fastText word embeddings, and statistical language models are freely available at https://github.com/naist-nlp/tubelex.
How to Make the Most of LLMs' Grammatical Knowledge for Acceptability Judgments
Aug 19, 2024



The grammatical knowledge of language models (LMs) is often measured using a benchmark of linguistic minimal pairs, where LMs are presented with a pair of acceptable and unacceptable sentences and required to judge which is acceptable. The existing dominant approach, however, naively calculates and compares the probabilities of paired sentences using LMs. Additionally, large language models (LLMs) have yet to be thoroughly examined in this field. We thus investigate how to make the most of LLMs' grammatical knowledge to comprehensively evaluate it. Through extensive experiments of nine judgment methods in English and Chinese, we demonstrate that a probability readout method, in-template LP, and a prompting-based method, Yes/No probability computing, achieve particularly high performance, surpassing the conventional approach. Our analysis reveals their different strengths, e.g., Yes/No probability computing is robust against token-length bias, suggesting that they harness different aspects of LLMs' grammatical knowledge. Consequently, we recommend using diverse judgment methods to evaluate LLMs comprehensively.
knn-seq: Efficient, Extensible kNN-MT Framework
Oct 18, 2023



k-nearest-neighbor machine translation (kNN-MT) boosts the translation quality of a pre-trained neural machine translation (NMT) model by utilizing translation examples during decoding. Translation examples are stored in a vector database, called a datastore, which contains one entry for each target token from the parallel data it is made from. Due to its size, it is computationally expensive both to construct and to retrieve examples from the datastore. In this paper, we present an efficient and extensible kNN-MT framework, knn-seq, for researchers and developers that is carefully designed to run efficiently, even with a billion-scale large datastore. knn-seq is developed as a plug-in on fairseq and easy to switch models and kNN indexes. Experimental results show that our implemented kNN-MT achieves a comparable gain to the original kNN-MT, and the billion-scale datastore construction took 2.21 hours in the WMT'19 German-to-English translation task. We publish our knn-seq as an MIT-licensed open-source project and the code is available on https://github.com/naist-nlp/knn-seq . The demo video is available on https://youtu.be/zTDzEOq80m0 .