 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyLM Challenge: Exploring the Effect of Variation Sets on Language Model Training Efficiency
Nov 14, 2024
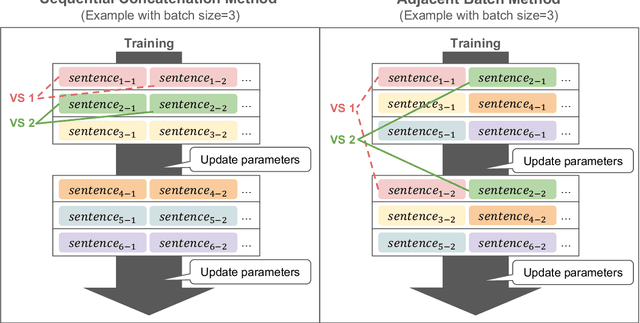


While current large language models have achieved a remarkable success, their data efficiency remains a challenge to overcome. Recently it has been suggested that child-directed speech (CDS) can improve training data efficiency of modern language models based on Transformer neural networks. However, it is not yet understood which specific properties of CDS are effective for training these models. In the context of the BabyLM Challenge, we focus on Variation Sets (VSs), sets of consecutive utterances expressing a similar intent with slightly different words and structures, which are ubiquitous in CDS. To assess the impact of VSs on training data efficiency, we augment CDS data with different proportions of artificial VSs and use these datasets to train an auto-regressive model, GPT-2. We find that the best proportion of VSs depends on the evaluation benchmark: BLiMP and GLUE scores benefit from the presence of VSs, but EWOK scores do not. Additionally, the results vary depending on multiple factors such as the number of epochs and the order of utterance presentation. Taken together, these findings suggest that VSs can have a beneficial influence on language models, while leaving room for further investigation.
BQA: Body Language Question Answering Dataset for Video Large Language Models
Oct 17, 2024



A large part of human communication relies on nonverbal cues such as facial expressions, eye contact, and body language. Unlike language or sign language, such nonverbal communication lacks formal rules, requiring complex reasoning based on commonsense understanding. Enabling current Video Large Language Models (VideoLLMs) to accurately interpret body language is a crucial challenge, as human unconscious actions can easily cause the model to misinterpret their intent. To address this, we propose a dataset, BQA, a body language question answering dataset, to validate whether the model can correctly interpret emotions from short clips of body language comprising 26 emotion labels of videos of body language. We evaluated various VideoLLMs on BQA and revealed that understanding body language is challenging, and our analyses of the wrong answers by VideoLLMs show that certain VideoLLMs made significantly biased answers depending on the age group and ethnicity of the individuals in the video. The dataset is available.
Can Language Models Induce Grammatical Knowledge from Indirect Evidence?
Oct 08, 2024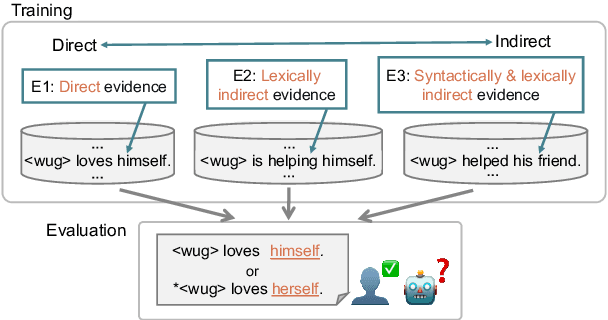
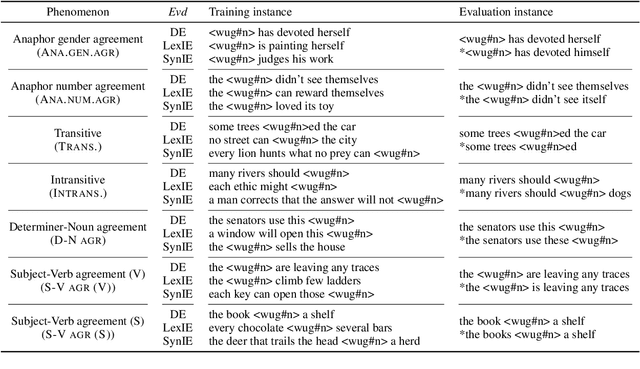

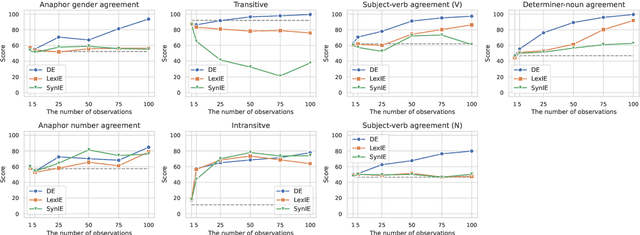
What kinds of and how much data is necessary for language models to induce grammatical knowledge to judge sentence acceptability? Recent language models still have much room for improvement in their data efficiency compared to humans. This paper investigates whether language models efficiently use indirect data (indirect evidence), from which they infer sentence acceptability. In contrast, humans use indirect evidence efficiently, which is considered one of the inductive biases contributing to efficient language acquisition. To explore this question, we introduce the Wug InDirect Evidence Test (WIDET), a dataset consisting of training instances inserted into the pre-training data and evaluation instances. We inject synthetic instances with newly coined wug words into pretraining data and explore the model's behavior on evaluation data that assesses grammatical acceptability regarding those words. We prepare the injected instances by varying their levels of indirectness and quantity. Our experiments surprisingly show that language models do not induce grammatical knowledge even after repeated exposure to instances with the same structure but differing only in lexical items from evaluation instances in certain language phenomena. Our findings suggest a potential direction for future research: developing models that use latent indirect evidence to induce grammatical knowledge.
How to Make the Most of LLMs' Grammatical Knowledge for Acceptability Judgments
Aug 19, 2024



The grammatical knowledge of language models (LMs) is often measured using a benchmark of linguistic minimal pairs, where LMs are presented with a pair of acceptable and unacceptable sentences and required to judge which is acceptable. The existing dominant approach, however, naively calculates and compares the probabilities of paired sentences using LMs. Additionally, large language models (LLMs) have yet to be thoroughly examined in this field. We thus investigate how to make the most of LLMs' grammatical knowledge to comprehensively evaluate it. Through extensive experiments of nine judgment methods in English and Chinese, we demonstrate that a probability readout method, in-template LP, and a prompting-based method, Yes/No probability computing, achieve particularly high performance, surpassing the conventional approach. Our analysis reveals their different strengths, e.g., Yes/No probability computing is robust against token-length bias, suggesting that they harness different aspects of LLMs' grammatical knowledge. Consequently, we recommend using diverse judgment methods to evaluate LLMs comprehensively.
Second Language Acquisition of Neural Language Models
Jun 05, 2023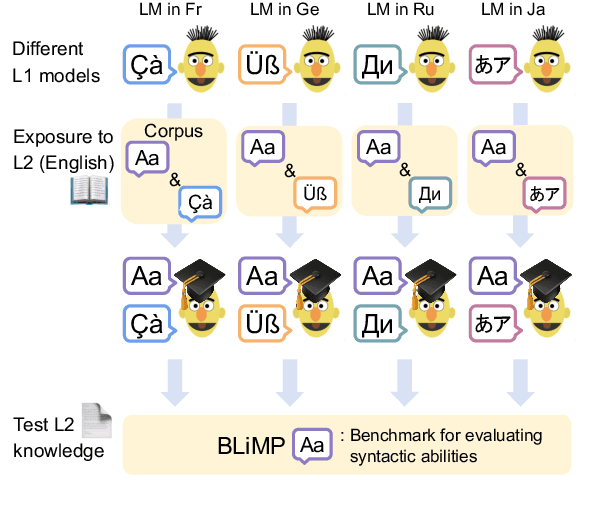
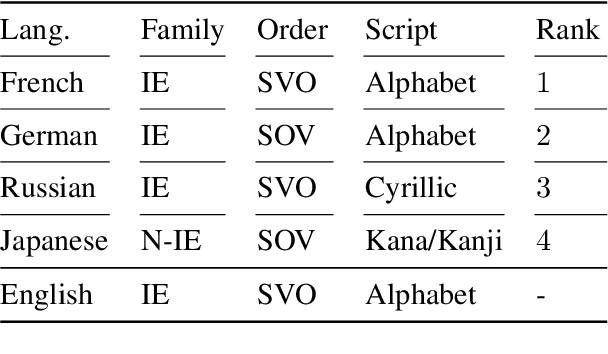
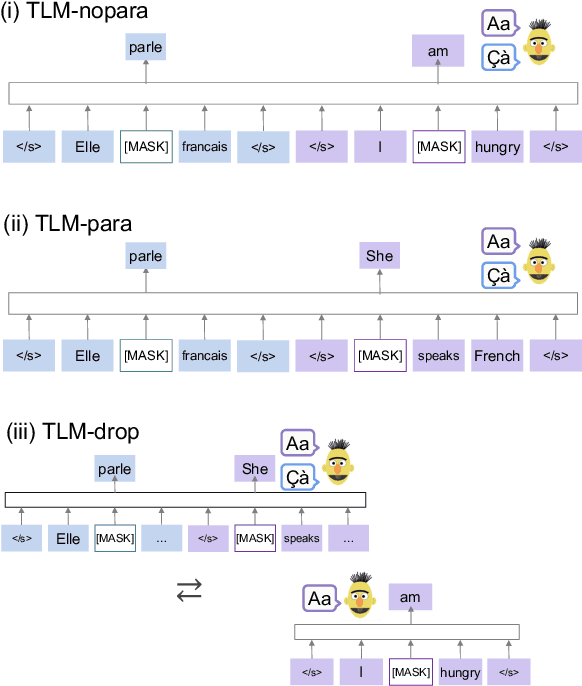
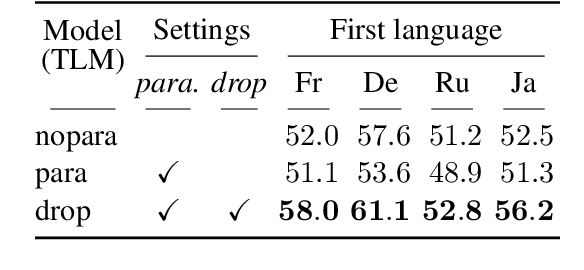
With the success of neural language models (LMs), their language acquisition has gained much attention. This work sheds light on the second language (L2) acquisition of LMs, while previous work has typically explored their first language (L1) acquisition. Specifically, we trained bilingual LMs with a scenario similar to human L2 acquisition and analyzed their cross-lingual transfer from linguistic perspectives. Our exploratory experiments demonstrated that the L1 pretraining accelerated their linguistic generalization in L2, and language transfer configurations (e.g., the L1 choice, and presence of parallel texts) substantially affected their generalizations. These clarify their (non-)human-like L2 acquisition in particular aspects.