 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Non-Verbatim Memorization in Large Language Models: The Role of Entity Surface Forms
Apr 23, 2026Understanding what kinds of factual knowledge large language models (LLMs) memorize is essential for evaluating their reliability and limitations. Entity-based QA is a common framework for analyzing non-verbatim memorization, but typical evaluations query each entity using a single canonical surface form, making it difficult to disentangle fact memorization from access through a particular name. We introduce RedirectQA, an entity-based QA dataset that uses Wikipedia redirect information to associate Wikidata factual triples with categorized surface forms for each entity, including alternative names, abbreviations, spelling variants, and common erroneous forms. Across 13 LLMs, we examine surface-conditioned factual memorization and find that prediction outcomes often change when only the entity surface form changes. This inconsistency is category-dependent: models are more robust to minor orthographic variations than to larger lexical variations such as aliases and abbreviations. Frequency analyses further suggest that both entity- and surface-level frequencies are associated with accuracy, and that entity frequency often contributes beyond surface frequency. Overall, factual memorization appears neither purely surface-specific nor fully surface-invariant, highlighting the importance of surface-form diversity in evaluating non-verbatim memorization.
Instability in Downstream Task Performance During LLM Pretraining
Oct 06, 2025When training large language models (LLMs), it is common practice to track downstream task performance throughout the training process and select the checkpoint with the highest validation score. However, downstream metrics often exhibit substantial fluctuations, making it difficult to identify the checkpoint that truly represents the best-performing model. In this study, we empirically analyze the stability of downstream task performance in an LLM trained on diverse web-scale corpora. We find that task scores frequently fluctuate throughout training, both at the aggregate and example levels. To address this instability, we investigate two post-hoc checkpoint integration methods: checkpoint averaging and ensemble, motivated by the hypothesis that aggregating neighboring checkpoints can reduce performance volatility. We demonstrate both empirically and theoretically that these methods improve downstream performance stability without requiring any changes to the training procedure.
Long-Tail Crisis in Nearest Neighbor Language Models
Mar 28, 2025



The $k$-nearest-neighbor language model ($k$NN-LM), one of the retrieval-augmented language models, improves the perplexity for given text by directly accessing a large datastore built from any text data during inference. A widely held hypothesis for the success of $k$NN-LM is that its explicit memory, i.e., the datastore, enhances predictions for long-tail phenomena. However, prior works have primarily shown its ability to retrieve long-tail contexts, leaving the model's performance remain underexplored in estimating the probabilities of long-tail target tokens during inference. In this paper, we investigate the behavior of $k$NN-LM on low-frequency tokens, examining prediction probability, retrieval accuracy, token distribution in the datastore, and approximation error of the product quantization. Our experimental results reveal that $k$NN-LM does not improve prediction performance for low-frequency tokens but mainly benefits high-frequency tokens regardless of long-tail contexts in the datastore.
How to Make the Most of LLMs' Grammatical Knowledge for Acceptability Judgments
Aug 19, 2024



The grammatical knowledge of language models (LMs) is often measured using a benchmark of linguistic minimal pairs, where LMs are presented with a pair of acceptable and unacceptable sentences and required to judge which is acceptable. The existing dominant approach, however, naively calculates and compares the probabilities of paired sentences using LMs. Additionally, large language models (LLMs) have yet to be thoroughly examined in this field. We thus investigate how to make the most of LLMs' grammatical knowledge to comprehensively evaluate it. Through extensive experiments of nine judgment methods in English and Chinese, we demonstrate that a probability readout method, in-template LP, and a prompting-based method, Yes/No probability computing, achieve particularly high performance, surpassing the conventional approach. Our analysis reveals their different strengths, e.g., Yes/No probability computing is robust against token-length bias, suggesting that they harness different aspects of LLMs' grammatical knowledge. Consequently, we recommend using diverse judgment methods to evaluate LLMs comprehensively.
Generating Diverse Translation with Perturbed kNN-MT
Feb 14, 2024
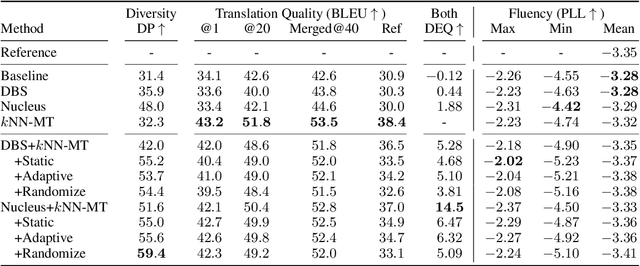


Generating multiple translation candidates would enable users to choose the one that satisfies their needs. Although there has been work on diversified generation, there exists room for improving the diversity mainly because the previous methods do not address the overcorrection problem -- the model underestimates a prediction that is largely different from the training data, even if that prediction is likely. This paper proposes methods that generate more diverse translations by introducing perturbed k-nearest neighbor machine translation (kNN-MT). Our methods expand the search space of kNN-MT and help incorporate diverse words into candidates by addressing the overcorrection problem. Our experiments show that the proposed methods drastically improve candidate diversity and control the degree of diversity by tuning the perturbation's magnitude.
knn-seq: Efficient, Extensible kNN-MT Framework
Oct 18, 2023



k-nearest-neighbor machine translation (kNN-MT) boosts the translation quality of a pre-trained neural machine translation (NMT) model by utilizing translation examples during decoding. Translation examples are stored in a vector database, called a datastore, which contains one entry for each target token from the parallel data it is made from. Due to its size, it is computationally expensive both to construct and to retrieve examples from the datastore. In this paper, we present an efficient and extensible kNN-MT framework, knn-seq, for researchers and developers that is carefully designed to run efficiently, even with a billion-scale large datastore. knn-seq is developed as a plug-in on fairseq and easy to switch models and kNN indexes. Experimental results show that our implemented kNN-MT achieves a comparable gain to the original kNN-MT, and the billion-scale datastore construction took 2.21 hours in the WMT'19 German-to-English translation task. We publish our knn-seq as an MIT-licensed open-source project and the code is available on https://github.com/naist-nlp/knn-seq . The demo video is available on https://youtu.be/zTDzEOq80m0 .