 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeMachine-bench: A Benchmark for Evaluating Model Capabilities in Repository-Level Migration Tasks
Jan 30, 2026With the advancement of automated software engineering, research focus is increasingly shifting toward practical tasks reflecting the day-to-day work of software engineers. Among these tasks, software migration, a critical process of adapting code to evolving environments, has been largely overlooked. In this study, we introduce TimeMachine-bench, a benchmark designed to evaluate software migration in real-world Python projects. Our benchmark consists of GitHub repositories whose tests begin to fail in response to dependency updates. The construction process is fully automated, enabling live updates of the benchmark. Furthermore, we curated a human-verified subset to ensure problem solvability. We evaluated agent-based baselines built on top of 11 models, including both strong open-weight and state-of-the-art LLMs on this verified subset. Our results indicated that, while LLMs show some promise for migration tasks, they continue to face substantial reliability challenges, including spurious solutions that exploit low test coverage and unnecessary edits stemming from suboptimal tool-use strategies. Our dataset and implementation are available at https://github.com/tohoku-nlp/timemachine-bench.
Long-Tail Crisis in Nearest Neighbor Language Models
Mar 28, 2025



The $k$-nearest-neighbor language model ($k$NN-LM), one of the retrieval-augmented language models, improves the perplexity for given text by directly accessing a large datastore built from any text data during inference. A widely held hypothesis for the success of $k$NN-LM is that its explicit memory, i.e., the datastore, enhances predictions for long-tail phenomena. However, prior works have primarily shown its ability to retrieve long-tail contexts, leaving the model's performance remain underexplored in estimating the probabilities of long-tail target tokens during inference. In this paper, we investigate the behavior of $k$NN-LM on low-frequency tokens, examining prediction probability, retrieval accuracy, token distribution in the datastore, and approximation error of the product quantization. Our experimental results reveal that $k$NN-LM does not improve prediction performance for low-frequency tokens but mainly benefits high-frequency tokens regardless of long-tail contexts in the datastore.
MQM-Chat: Multidimensional Quality Metrics for Chat Translation
Aug 29, 2024The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
An Investigation of Warning Erroneous Chat Translations in Cross-lingual Communication
Aug 28, 2024



The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
Simplifying Translations for Children: Iterative Simplification Considering Age of Acquisition with LLMs
Aug 08, 2024



In recent years, neural machine translation (NMT) has been widely used in everyday life. However, the current NMT lacks a mechanism to adjust the difficulty level of translations to match the user's language level. Additionally, due to the bias in the training data for NMT, translations of simple source sentences are often produced with complex words. In particular, this could pose a problem for children, who may not be able to understand the meaning of the translations correctly. In this study, we propose a method that replaces words with high Age of Acquisitions (AoA) in translations with simpler words to match the translations to the user's level. We achieve this by using large language models (LLMs), providing a triple of a source sentence, a translation, and a target word to be replaced. We create a benchmark dataset using back-translation on Simple English Wikipedia. The experimental results obtained from the dataset show that our method effectively replaces high-AoA words with lower-AoA words and, moreover, can iteratively replace most of the high-AoA words while still maintaining high BLEU and COMET scores.
A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
May 15, 2024



Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
Generating Diverse Translation with Perturbed kNN-MT
Feb 14, 2024
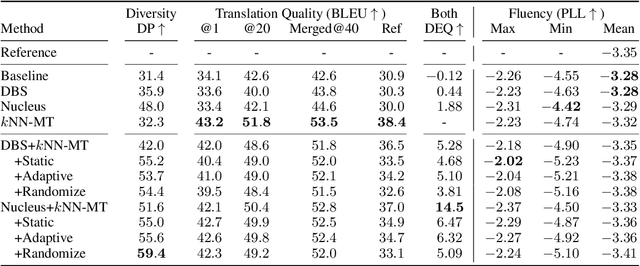


Generating multiple translation candidates would enable users to choose the one that satisfies their needs. Although there has been work on diversified generation, there exists room for improving the diversity mainly because the previous methods do not address the overcorrection problem -- the model underestimates a prediction that is largely different from the training data, even if that prediction is likely. This paper proposes methods that generate more diverse translations by introducing perturbed k-nearest neighbor machine translation (kNN-MT). Our methods expand the search space of kNN-MT and help incorporate diverse words into candidates by addressing the overcorrection problem. Our experiments show that the proposed methods drastically improve candidate diversity and control the degree of diversity by tuning the perturbation's magnitude.
Refactoring Programs Using Large Language Models with Few-Shot Examples
Nov 20, 2023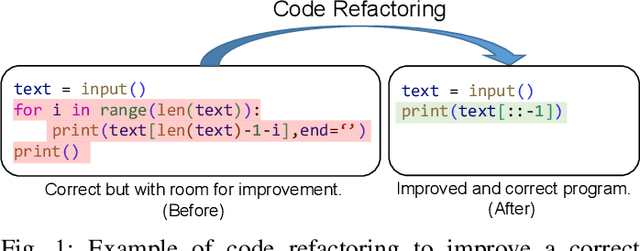
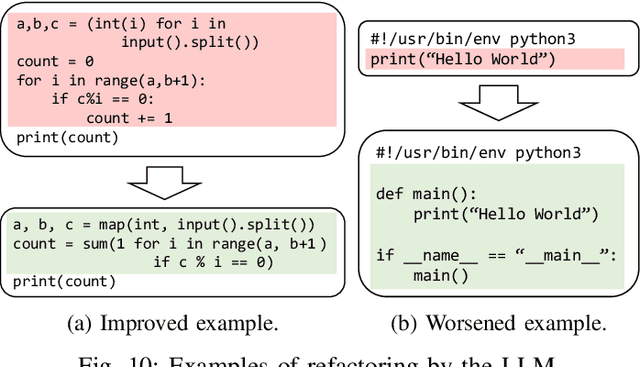

A less complex and more straightforward program is a crucial factor that enhances its maintainability and makes writing secure and bug-free programs easier. However, due to its heavy workload and the risks of breaking the working programs, programmers are reluctant to do code refactoring, and thus, it also causes the loss of potential learning experiences. To mitigate this, we demonstrate the application of using a large language model (LLM), GPT-3.5, to suggest less complex versions of the user-written Python program, aiming to encourage users to learn how to write better programs. We propose a method to leverage the prompting with few-shot examples of the LLM by selecting the best-suited code refactoring examples for each target programming problem based on the prior evaluation of prompting with the one-shot example. The quantitative evaluation shows that 95.68% of programs can be refactored by generating 10 candidates each, resulting in a 17.35% reduction in the average cyclomatic complexity and a 25.84% decrease in the average number of lines after filtering only generated programs that are semantically correct. Furthermore, the qualitative evaluation shows outstanding capability in code formatting, while unnecessary behaviors such as deleting or translating comments are also observed.
Chat Translation Error Detection for Assisting Cross-lingual Communications
Aug 02, 2023In this paper, we describe the development of a communication support system that detects erroneous translations to facilitate crosslingual communications due to the limitations of current machine chat translation methods. We trained an error detector as the baseline of the system and constructed a new Japanese-English bilingual chat corpus, BPersona-chat, which comprises multiturn colloquial chats augmented with crowdsourced quality ratings. The error detector can serve as an encouraging foundation for more advanced erroneous translation detection systems.