 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Translations for Children: Iterative Simplification Considering Age of Acquisition with LLMs
Aug 08, 2024



In recent years, neural machine translation (NMT) has been widely used in everyday life. However, the current NMT lacks a mechanism to adjust the difficulty level of translations to match the user's language level. Additionally, due to the bias in the training data for NMT, translations of simple source sentences are often produced with complex words. In particular, this could pose a problem for children, who may not be able to understand the meaning of the translations correctly. In this study, we propose a method that replaces words with high Age of Acquisitions (AoA) in translations with simpler words to match the translations to the user's level. We achieve this by using large language models (LLMs), providing a triple of a source sentence, a translation, and a target word to be replaced. We create a benchmark dataset using back-translation on Simple English Wikipedia. The experimental results obtained from the dataset show that our method effectively replaces high-AoA words with lower-AoA words and, moreover, can iteratively replace most of the high-AoA words while still maintaining high BLEU and COMET scores.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
Can we obtain significant success in RST discourse parsing by using Large Language Models?
Mar 08, 2024Recently, decoder-only pre-trained large language models (LLMs), with several tens of billion parameters, have significantly impacted a wide range of natural language processing (NLP) tasks. While encoder-only or encoder-decoder pre-trained language models have already proved to be effective in discourse parsing, the extent to which LLMs can perform this task remains an open research question. Therefore, this paper explores how beneficial such LLMs are for Rhetorical Structure Theory (RST) discourse parsing. Here, the parsing process for both fundamental top-down and bottom-up strategies is converted into prompts, which LLMs can work with. We employ Llama 2 and fine-tune it with QLoRA, which has fewer parameters that can be tuned. Experimental results on three benchmark datasets, RST-DT, Instr-DT, and the GUM corpus, demonstrate that Llama 2 with 70 billion parameters in the bottom-up strategy obtained state-of-the-art (SOTA) results with significant differences. Furthermore, our parsers demonstrated generalizability when evaluated on RST-DT, showing that, in spite of being trained with the GUM corpus, it obtained similar performances to those of existing parsers trained with RST-DT.
A Simple and Strong Baseline for End-to-End Neural RST-style Discourse Parsing
Oct 15, 2022

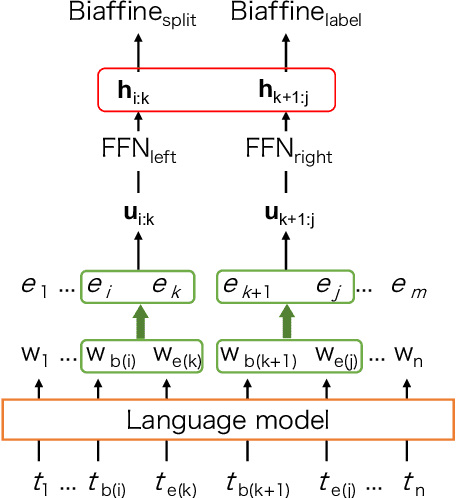
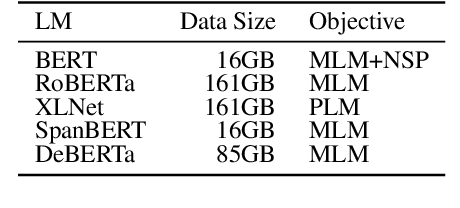
To promote and further develop RST-style discourse parsing models, we need a strong baseline that can be regarded as a reference for reporting reliable experimental results. This paper explores a strong baseline by integrating existing simple parsing strategies, top-down and bottom-up, with various transformer-based pre-trained language models. The experimental results obtained from two benchmark datasets demonstrate that the parsing performance strongly relies on the pretrained language models rather than the parsing strategies. In particular, the bottom-up parser achieves large performance gains compared to the current best parser when employing DeBERTa. We further reveal that language models with a span-masking scheme especially boost the parsing performance through our analysis within intra- and multi-sentential parsing, and nuclearity prediction.
Recovery command generation towards automatic recovery in ICT systems by Seq2Seq learning
Mar 24, 2020

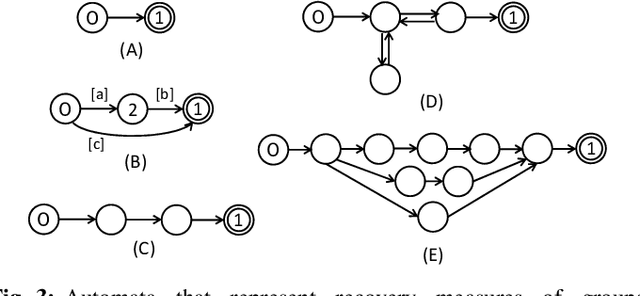
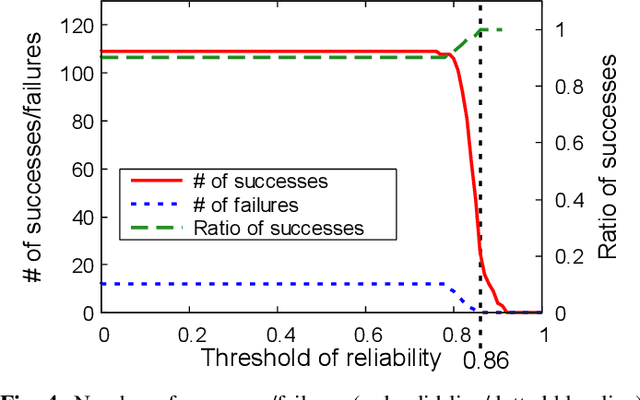
With the increase in scale and complexity of ICT systems, their operation increasingly requires automatic recovery from failures. Although it has become possible to automatically detect anomalies and analyze root causes of failures with current methods, making decisions on what commands should be executed to recover from failures still depends on manual operation, which is quite time-consuming. Toward automatic recovery, we propose a method of estimating recovery commands by using Seq2Seq, a neural network model. This model learns complex relationships between logs obtained from equipment and recovery commands that operators executed in the past. When a new failure occurs, our method estimates plausible commands that recover from the failure on the basis of collected logs. We conducted experiments using a synthetic dataset and realistic OpenStack dataset, demonstrating that our method can estimate recovery commands with high accuracy.
NTT's Machine Translation Systems for WMT19 Robustness Task
Jul 09, 2019


This paper describes NTT's submission to the WMT19 robustness task. This task mainly focuses on translating noisy text (e.g., posts on Twitter), which presents different difficulties from typical translation tasks such as news. Our submission combined techniques including utilization of a synthetic corpus, domain adaptation, and a placeholder mechanism, which significantly improved over the previous baseline. Experimental results revealed the placeholder mechanism, which temporarily replaces the non-standard tokens including emojis and emoticons with special placeholder tokens during translation, improves translation accuracy even with noisy texts.
Enumeration of Extractive Oracle Summaries
Jan 06, 2017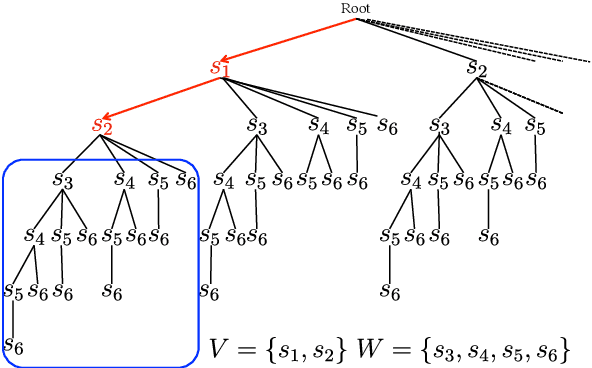
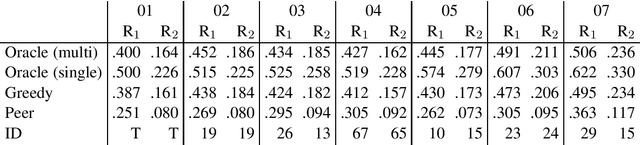
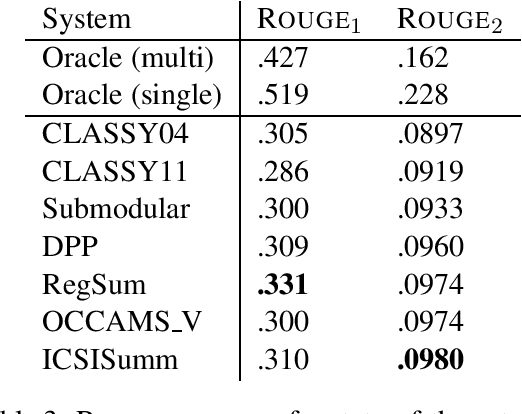
To analyze the limitations and the future directions of the extractive summarization paradigm, this paper proposes an Integer Linear Programming (ILP) formulation to obtain extractive oracle summaries in terms of ROUGE-N. We also propose an algorithm that enumerates all of the oracle summaries for a set of reference summaries to exploit F-measures that evaluate which system summaries contain how many sentences that are extracted as an oracle summary. Our experimental results obtained from Document Understanding Conference (DUC) corpora demonstrated the following: (1) room still exists to improve the performance of extractive summarization; (2) the F-measures derived from the enumerated oracle summaries have significantly stronger correlations with human judgment than those derived from single oracle summaries.