 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Language Models Acquire Character-Level Information?
Feb 05, 2026Language models (LMs) have been reported to implicitly encode character-level information, despite not being explicitly provided during training. However, the mechanisms underlying this phenomenon remain largely unexplored. To reveal the mechanisms, we analyze how models acquire character-level knowledge by comparing LMs trained under controlled settings, such as specifying the pre-training dataset or tokenizer, with those trained under standard settings. We categorize the contributing factors into those independent of tokenization. Our analysis reveals that merge rules and orthographic constraints constitute primary factors arising from tokenization, whereas semantic associations of substrings and syntactic information function as key factors independent of tokenization.
Do LLMs and Humans Find the Same Questions Difficult? A Case Study on Japanese Quiz Answering
Nov 15, 2025LLMs have achieved performance that surpasses humans in many NLP tasks. However, it remains unclear whether problems that are difficult for humans are also difficult for LLMs. This study investigates how the difficulty of quizzes in a buzzer setting differs between LLMs and humans. Specifically, we first collect Japanese quiz data including questions, answers, and correct response rate of humans, then prompted LLMs to answer the quizzes under several settings, and compare their correct answer rate to that of humans from two analytical perspectives. The experimental results showed that, compared to humans, LLMs struggle more with quizzes whose correct answers are not covered by Wikipedia entries, and also have difficulty with questions that require numerical answers.
On Representational Dissociation of Language and Arithmetic in Large Language Models
Feb 17, 2025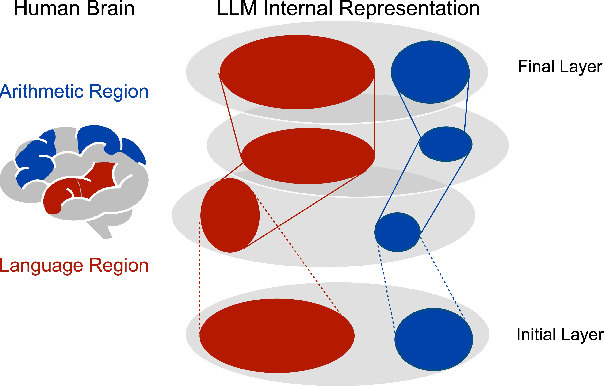
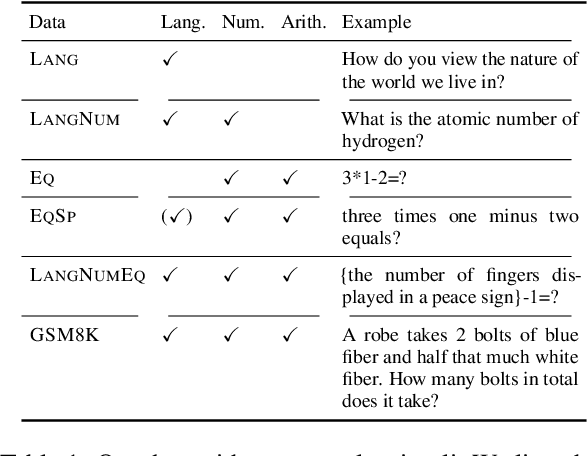
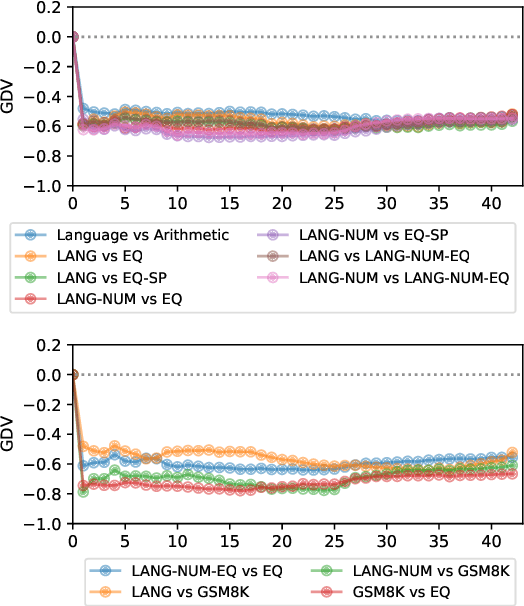

The association between language and (non-linguistic) thinking ability in humans has long been debated, and recently, neuroscientific evidence of brain activity patterns has been considered. Such a scientific context naturally raises an interdisciplinary question -- what about such a language-thought dissociation in large language models (LLMs)? In this paper, as an initial foray, we explore this question by focusing on simple arithmetic skills (e.g., $1+2=$ ?) as a thinking ability and analyzing the geometry of their encoding in LLMs' representation space. Our experiments with linear classifiers and cluster separability tests demonstrate that simple arithmetic equations and general language input are encoded in completely separated regions in LLMs' internal representation space across all the layers, which is also supported with more controlled stimuli (e.g., spelled-out equations). These tentatively suggest that arithmetic reasoning is mapped into a distinct region from general language input, which is in line with the neuroscientific observations of human brain activations, while we also point out their somewhat cognitively implausible geometric properties.
CiMaTe: Citation Count Prediction Effectively Leveraging the Main Text
Oct 06, 2024

Prediction of the future citation counts of papers is increasingly important to find interesting papers among an ever-growing number of papers. Although a paper's main text is an important factor for citation count prediction, it is difficult to handle in machine learning models because the main text is typically very long; thus previous studies have not fully explored how to leverage it. In this paper, we propose a BERT-based citation count prediction model, called CiMaTe, that leverages the main text by explicitly capturing a paper's sectional structure. Through experiments with papers from computational linguistics and biology domains, we demonstrate the CiMaTe's effectiveness, outperforming the previous methods in Spearman's rank correlation coefficient; 5.1 points in the computational linguistics domain and 1.8 points in the biology domain.
Ruri: Japanese General Text Embeddings
Sep 12, 2024We report the development of Ruri, a series of Japanese general text embedding models. While the development of general-purpose text embedding models in English and multilingual contexts has been active in recent years, model development in Japanese remains insufficient. The primary reasons for this are the lack of datasets and the absence of necessary expertise. In this report, we provide a detailed account of the development process of Ruri. Specifically, we discuss the training of embedding models using synthesized datasets generated by LLMs, the construction of the reranker for dataset filtering and knowledge distillation, and the performance evaluation of the resulting general-purpose text embedding models.
Are Social Sentiments Inherent in LLMs? An Empirical Study on Extraction of Inter-demographic Sentiments
Aug 08, 2024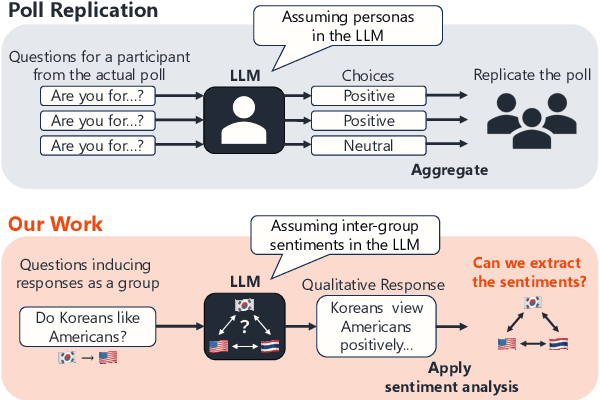
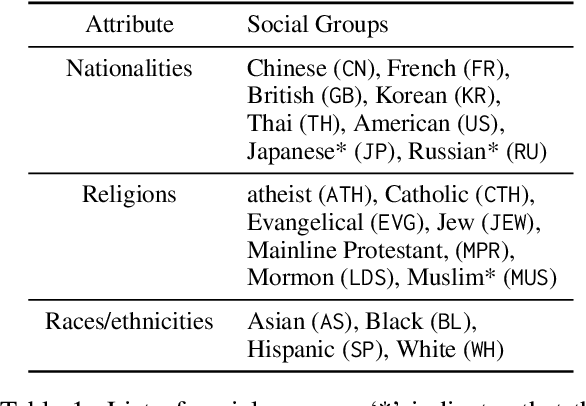


Large language models (LLMs) are supposed to acquire unconscious human knowledge and feelings, such as social common sense and biases, by training models from large amounts of text. However, it is not clear how much the sentiments of specific social groups can be captured in various LLMs. In this study, we focus on social groups defined in terms of nationality, religion, and race/ethnicity, and validate the extent to which sentiments between social groups can be captured in and extracted from LLMs. Specifically, we input questions regarding sentiments from one group to another into LLMs, apply sentiment analysis to the responses, and compare the results with social surveys. The validation results using five representative LLMs showed higher correlations with relatively small p-values for nationalities and religions, whose number of data points were relatively large. This result indicates that the LLM responses including the inter-group sentiments align well with actual social survey results.
Simplifying Translations for Children: Iterative Simplification Considering Age of Acquisition with LLMs
Aug 08, 2024



In recent years, neural machine translation (NMT) has been widely used in everyday life. However, the current NMT lacks a mechanism to adjust the difficulty level of translations to match the user's language level. Additionally, due to the bias in the training data for NMT, translations of simple source sentences are often produced with complex words. In particular, this could pose a problem for children, who may not be able to understand the meaning of the translations correctly. In this study, we propose a method that replaces words with high Age of Acquisitions (AoA) in translations with simpler words to match the translations to the user's level. We achieve this by using large language models (LLMs), providing a triple of a source sentence, a translation, and a target word to be replaced. We create a benchmark dataset using back-translation on Simple English Wikipedia. The experimental results obtained from the dataset show that our method effectively replaces high-AoA words with lower-AoA words and, moreover, can iteratively replace most of the high-AoA words while still maintaining high BLEU and COMET scores.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
Verifying Claims About Metaphors with Large-Scale Automatic Metaphor Identification
Apr 01, 2024
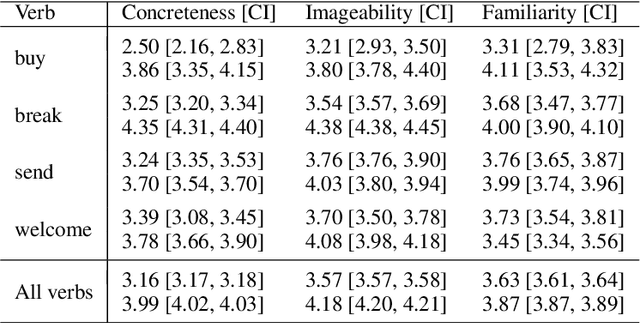
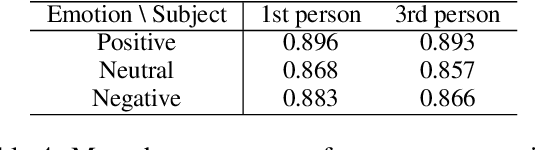
There are several linguistic claims about situations where words are more likely to be used as metaphors. However, few studies have sought to verify such claims with large corpora. This study entails a large-scale, corpus-based analysis of certain existing claims about verb metaphors, by applying metaphor detection to sentences extracted from Common Crawl and using the statistics obtained from the results. The verification results indicate that the direct objects of verbs used as metaphors tend to have lower degrees of concreteness, imageability, and familiarity, and that metaphors are more likely to be used in emotional and subjective sentences.
Improving Sentence Embeddings with an Automatically Generated NLI Dataset
Feb 23, 2024



Decoder-based large language models (LLMs) have shown high performance on many tasks in natural language processing. This is also true for sentence embedding learning, where a decoder-based model, PromptEOL, has achieved the best performance on semantic textual similarity (STS) tasks. However, PromptEOL makes great use of fine-tuning with a manually annotated natural language inference (NLI) dataset. We aim to improve sentence embeddings learned in an unsupervised setting by automatically generating an NLI dataset with an LLM and using it to fine-tune PromptEOL. In experiments on STS tasks, the proposed method achieved an average Spearman's rank correlation coefficient of 82.21 with respect to human evaluation, thus outperforming existing methods without using large, manually annotated datasets.