 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
CiMaTe: Citation Count Prediction Effectively Leveraging the Main Text
Oct 06, 2024

Prediction of the future citation counts of papers is increasingly important to find interesting papers among an ever-growing number of papers. Although a paper's main text is an important factor for citation count prediction, it is difficult to handle in machine learning models because the main text is typically very long; thus previous studies have not fully explored how to leverage it. In this paper, we propose a BERT-based citation count prediction model, called CiMaTe, that leverages the main text by explicitly capturing a paper's sectional structure. Through experiments with papers from computational linguistics and biology domains, we demonstrate the CiMaTe's effectiveness, outperforming the previous methods in Spearman's rank correlation coefficient; 5.1 points in the computational linguistics domain and 1.8 points in the biology domain.
Are Social Sentiments Inherent in LLMs? An Empirical Study on Extraction of Inter-demographic Sentiments
Aug 08, 2024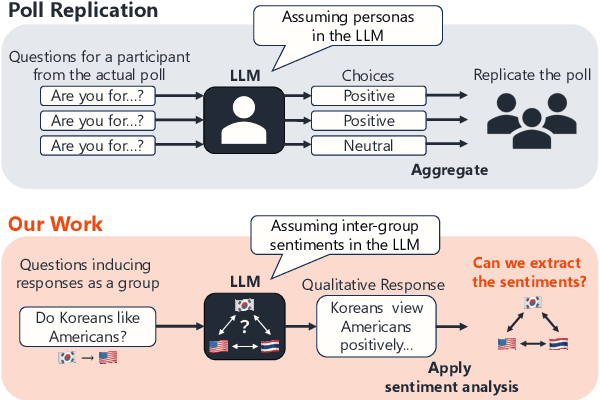
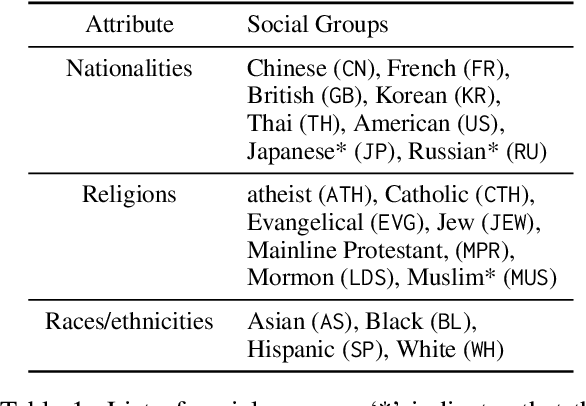


Large language models (LLMs) are supposed to acquire unconscious human knowledge and feelings, such as social common sense and biases, by training models from large amounts of text. However, it is not clear how much the sentiments of specific social groups can be captured in various LLMs. In this study, we focus on social groups defined in terms of nationality, religion, and race/ethnicity, and validate the extent to which sentiments between social groups can be captured in and extracted from LLMs. Specifically, we input questions regarding sentiments from one group to another into LLMs, apply sentiment analysis to the responses, and compare the results with social surveys. The validation results using five representative LLMs showed higher correlations with relatively small p-values for nationalities and religions, whose number of data points were relatively large. This result indicates that the LLM responses including the inter-group sentiments align well with actual social survey results.
Simplifying Translations for Children: Iterative Simplification Considering Age of Acquisition with LLMs
Aug 08, 2024



In recent years, neural machine translation (NMT) has been widely used in everyday life. However, the current NMT lacks a mechanism to adjust the difficulty level of translations to match the user's language level. Additionally, due to the bias in the training data for NMT, translations of simple source sentences are often produced with complex words. In particular, this could pose a problem for children, who may not be able to understand the meaning of the translations correctly. In this study, we propose a method that replaces words with high Age of Acquisitions (AoA) in translations with simpler words to match the translations to the user's level. We achieve this by using large language models (LLMs), providing a triple of a source sentence, a translation, and a target word to be replaced. We create a benchmark dataset using back-translation on Simple English Wikipedia. The experimental results obtained from the dataset show that our method effectively replaces high-AoA words with lower-AoA words and, moreover, can iteratively replace most of the high-AoA words while still maintaining high BLEU and COMET scores.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024



The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
Verifying Claims About Metaphors with Large-Scale Automatic Metaphor Identification
Apr 01, 2024
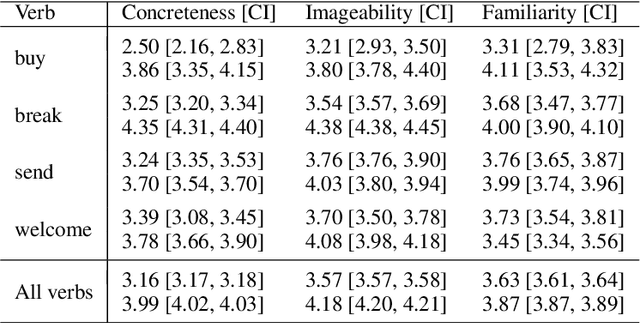
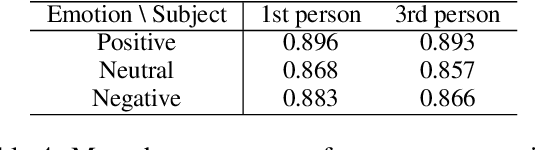
There are several linguistic claims about situations where words are more likely to be used as metaphors. However, few studies have sought to verify such claims with large corpora. This study entails a large-scale, corpus-based analysis of certain existing claims about verb metaphors, by applying metaphor detection to sentences extracted from Common Crawl and using the statistics obtained from the results. The verification results indicate that the direct objects of verbs used as metaphors tend to have lower degrees of concreteness, imageability, and familiarity, and that metaphors are more likely to be used in emotional and subjective sentences.
Improving Sentence Embeddings with an Automatically Generated NLI Dataset
Feb 23, 2024



Decoder-based large language models (LLMs) have shown high performance on many tasks in natural language processing. This is also true for sentence embedding learning, where a decoder-based model, PromptEOL, has achieved the best performance on semantic textual similarity (STS) tasks. However, PromptEOL makes great use of fine-tuning with a manually annotated natural language inference (NLI) dataset. We aim to improve sentence embeddings learned in an unsupervised setting by automatically generating an NLI dataset with an LLM and using it to fine-tune PromptEOL. In experiments on STS tasks, the proposed method achieved an average Spearman's rank correlation coefficient of 82.21 with respect to human evaluation, thus outperforming existing methods without using large, manually annotated datasets.
Japanese SimCSE Technical Report
Oct 30, 2023



We report the development of Japanese SimCSE, Japanese sentence embedding models fine-tuned with SimCSE. Since there is a lack of sentence embedding models for Japanese that can be used as a baseline in sentence embedding research, we conducted extensive experiments on Japanese sentence embeddings involving 24 pre-trained Japanese or multilingual language models, five supervised datasets, and four unsupervised datasets. In this report, we provide the detailed training setup for Japanese SimCSE and their evaluation results.
Transformer-based Live Update Generation for Soccer Matches from Microblog Posts
Oct 25, 2023



It has been known to be difficult to generate adequate sports updates from a sequence of vast amounts of diverse live tweets, although the live sports viewing experience with tweets is gaining the popularity. In this paper, we focus on soccer matches and work on building a system to generate live updates for soccer matches from tweets so that users can instantly grasp a match's progress and enjoy the excitement of the match from raw tweets. Our proposed system is based on a large pre-trained language model and incorporates a mechanism to control the number of updates and a mechanism to reduce the redundancy of duplicate and similar updates.