 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
Investigating Cost-Efficiency of LLM-Generated Training Data for Conversational Semantic Frame Analysis
Oct 09, 2024



Recent studies have demonstrated that few-shot learning allows LLMs to generate training data for supervised models at a low cost. However, the quality of LLM-generated data may not entirely match that of human-labeled data. This raises a crucial question: how should one balance the trade-off between the higher quality but more expensive human data and the lower quality yet substantially cheaper LLM-generated data? In this paper, we synthesized training data for conversational semantic frame analysis using GPT-4 and examined how to allocate budgets optimally to achieve the best performance. Our experiments, conducted across various budget levels, reveal that optimal cost-efficiency is achieved by combining both human and LLM-generated data across a wide range of budget levels. Notably, as the budget decreases, a higher proportion of LLM-generated data becomes more preferable.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
RecMind: Japanese Movie Recommendation Dialogue with Seeker's Internal State
Feb 21, 2024



Humans pay careful attention to the interlocutor's internal state in dialogues. For example, in recommendation dialogues, we make recommendations while estimating the seeker's internal state, such as his/her level of knowledge and interest. Since there are no existing annotated resources for the analysis, we constructed RecMind, a Japanese movie recommendation dialogue dataset with annotations of the seeker's internal state at the entity level. Each entity has a subjective label annotated by the seeker and an objective label annotated by the recommender. RecMind also features engaging dialogues with long seeker's utterances, enabling a detailed analysis of the seeker's internal state. Our analysis based on RecMind reveals that entities that the seeker has no knowledge about but has an interest in contribute to recommendation success. We also propose a response generation framework that explicitly considers the seeker's internal state, utilizing the chain-of-thought prompting. The human evaluation results show that our proposed method outperforms the baseline method in both consistency and the success of recommendations.
MultiTool-CoT: GPT-3 Can Use Multiple External Tools with Chain of Thought Prompting
May 26, 2023



Large language models (LLMs) have achieved impressive performance on various reasoning tasks. To further improve the performance, we propose MultiTool-CoT, a novel framework that leverages chain-of-thought (CoT) prompting to incorporate multiple external tools, such as a calculator and a knowledge retriever, during the reasoning process. We apply MultiTool-CoT to the Task 2 dataset of NumGLUE, which requires both numerical reasoning and domain-specific knowledge. The experiments show that our method significantly outperforms strong baselines and achieves state-of-the-art performance.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020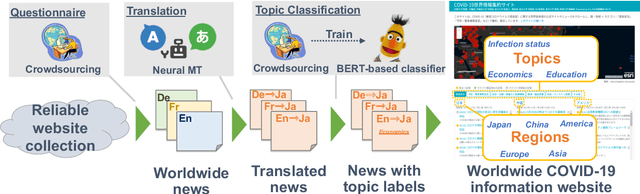

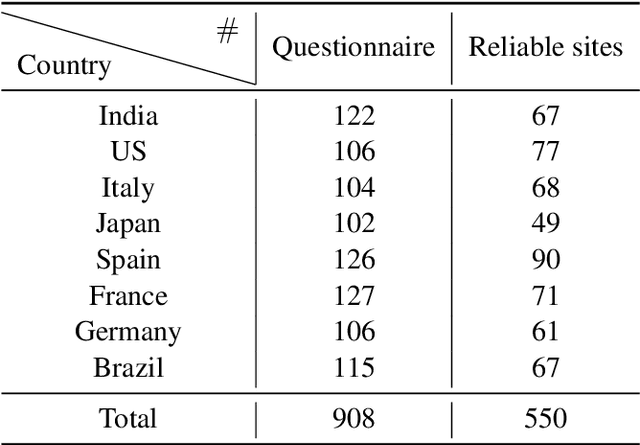
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.