 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Jailbreaking in Large Language Models
Jan 23, 2026Large Language Models (LLMs) are increasingly deployed in domains such as education, mental health and customer support, where stable and consistent personas are critical for reliability. Yet, existing studies focus on narrative or role-playing tasks and overlook how adversarial conversational history alone can reshape induced personas. Black-box persona manipulation remains unexplored, raising concerns for robustness in realistic interactions. In response, we introduce the task of persona editing, which adversarially steers LLM traits through user-side inputs under a black-box, inference-only setting. To this end, we propose PHISH (Persona Hijacking via Implicit Steering in History), the first framework to expose a new vulnerability in LLM safety that embeds semantically loaded cues into user queries to gradually induce reverse personas. We also define a metric to quantify attack success. Across 3 benchmarks and 8 LLMs, PHISH predictably shifts personas, triggers collateral changes in correlated traits, and exhibits stronger effects in multi-turn settings. In high-risk domains mental health, tutoring, and customer support, PHISH reliably manipulates personas, validated by both human and LLM-as-Judge evaluations. Importantly, PHISH causes only a small reduction in reasoning benchmark performance, leaving overall utility largely intact while still enabling significant persona manipulation. While current guardrails offer partial protection, they remain brittle under sustained attack. Our findings expose new vulnerabilities in personas and highlight the need for context-resilient persona in LLMs. Our codebase and dataset is available at: https://github.com/Jivnesh/PHISH
Language Lives in Sparse Dimensions: Toward Interpretable and Efficient Multilingual Control for Large Language Models
Oct 08, 2025Large language models exhibit strong multilingual capabilities despite limited exposure to non-English data. Prior studies show that English-centric large language models map multilingual content into English-aligned representations at intermediate layers and then project them back into target-language token spaces in the final layer. From this observation, we hypothesize that this cross-lingual transition is governed by a small and sparse set of dimensions, which occur at consistent indices across the intermediate to final layers. Building on this insight, we introduce a simple, training-free method to identify and manipulate these dimensions, requiring only as few as 50 sentences of either parallel or monolingual data. Experiments on a multilingual generation control task reveal the interpretability of these dimensions, demonstrating that the interventions in these dimensions can switch the output language while preserving semantic content, and that it surpasses the performance of prior neuron-based approaches at a substantially lower cost.
Addressing Tokenization Inconsistency in Steganography and Watermarking Based on Large Language Models
Aug 28, 2025Large language models have significantly enhanced the capacities and efficiency of text generation. On the one hand, they have improved the quality of text-based steganography. On the other hand, they have also underscored the importance of watermarking as a safeguard against malicious misuse. In this study, we focus on tokenization inconsistency (TI) between Alice and Bob in steganography and watermarking, where TI can undermine robustness. Our investigation reveals that the problematic tokens responsible for TI exhibit two key characteristics: infrequency and temporariness. Based on these findings, we propose two tailored solutions for TI elimination: a stepwise verification method for steganography and a post-hoc rollback method for watermarking. Experiments show that (1) compared to traditional disambiguation methods in steganography, directly addressing TI leads to improvements in fluency, imperceptibility, and anti-steganalysis capacity; (2) for watermarking, addressing TI enhances detectability and robustness against attacks.
How Does Cognitive Bias Affect Large Language Models? A Case Study on the Anchoring Effect in Price Negotiation Simulations
Aug 28, 2025Cognitive biases, well-studied in humans, can also be observed in LLMs, affecting their reliability in real-world applications. This paper investigates the anchoring effect in LLM-driven price negotiations. To this end, we instructed seller LLM agents to apply the anchoring effect and evaluated negotiations using not only an objective metric but also a subjective metric. Experimental results show that LLMs are influenced by the anchoring effect like humans. Additionally, we investigated the relationship between the anchoring effect and factors such as reasoning and personality. It was shown that reasoning models are less prone to the anchoring effect, suggesting that the long chain of thought mitigates the effect. However, we found no significant correlation between personality traits and susceptibility to the anchoring effect. These findings contribute to a deeper understanding of cognitive biases in LLMs and to the realization of safe and responsible application of LLMs in society.
Investigating Cost-Efficiency of LLM-Generated Training Data for Conversational Semantic Frame Analysis
Oct 09, 2024



Recent studies have demonstrated that few-shot learning allows LLMs to generate training data for supervised models at a low cost. However, the quality of LLM-generated data may not entirely match that of human-labeled data. This raises a crucial question: how should one balance the trade-off between the higher quality but more expensive human data and the lower quality yet substantially cheaper LLM-generated data? In this paper, we synthesized training data for conversational semantic frame analysis using GPT-4 and examined how to allocate budgets optimally to achieve the best performance. Our experiments, conducted across various budget levels, reveal that optimal cost-efficiency is achieved by combining both human and LLM-generated data across a wide range of budget levels. Notably, as the budget decreases, a higher proportion of LLM-generated data becomes more preferable.
Beyond English-Centric LLMs: What Language Do Multilingual Language Models Think in?
Aug 20, 2024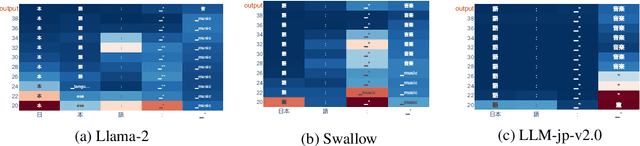

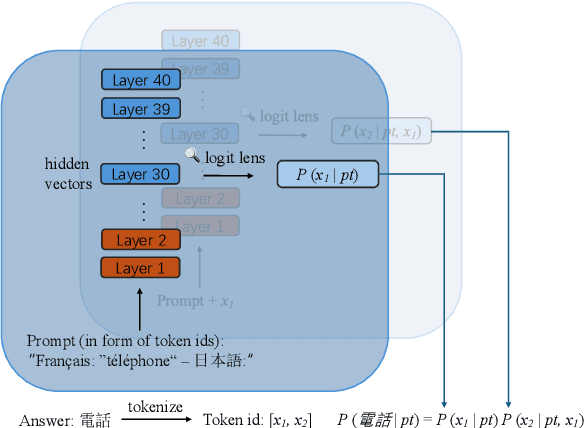
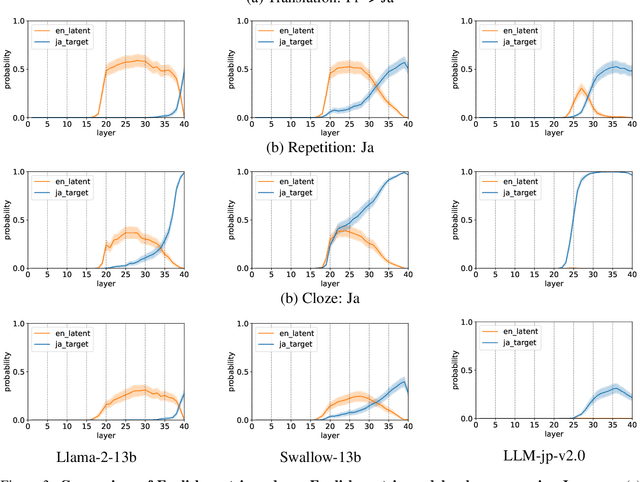
In this study, we investigate whether non-English-centric LLMs, despite their strong performance, `think' in their respective dominant language: more precisely, `think' refers to how the representations of intermediate layers, when un-embedded into the vocabulary space, exhibit higher probabilities for certain dominant languages during generation. We term such languages as internal $\textbf{latent languages}$. We examine the latent language of three typical categories of models for Japanese processing: Llama2, an English-centric model; Swallow, an English-centric model with continued pre-training in Japanese; and LLM-jp, a model pre-trained on balanced English and Japanese corpora. Our empirical findings reveal that, unlike Llama2 which relies exclusively on English as the internal latent language, Japanese-specific Swallow and LLM-jp employ both Japanese and English, exhibiting dual internal latent languages. For any given target language, the model preferentially activates the latent language most closely related to it. In addition, we explore how intermediate layers respond to questions involving cultural conflicts between latent internal and target output languages. We further explore how the language identity shifts across layers while keeping consistent semantic meaning reflected in the intermediate layer representations. This study deepens the understanding of non-English-centric large language models, highlighting the intricate dynamics of language representation within their intermediate layers.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Principal Component Analysis as a Sanity Check for Bayesian Phylolinguistic Reconstruction
Feb 29, 2024



Bayesian approaches to reconstructing the evolutionary history of languages rely on the tree model, which assumes that these languages descended from a common ancestor and underwent modifications over time. However, this assumption can be violated to different extents due to contact and other factors. Understanding the degree to which this assumption is violated is crucial for validating the accuracy of phylolinguistic inference. In this paper, we propose a simple sanity check: projecting a reconstructed tree onto a space generated by principal component analysis. By using both synthetic and real data, we demonstrate that our method effectively visualizes anomalies, particularly in the form of jogging.
Addressing Segmentation Ambiguity in Neural Linguistic Steganography
Nov 12, 2022



Previous studies on neural linguistic steganography, except Ueoka et al. (2021), overlook the fact that the sender must detokenize cover texts to avoid arousing the eavesdropper's suspicion. In this paper, we demonstrate that segmentation ambiguity indeed causes occasional decoding failures at the receiver's side. With the near-ubiquity of subwords, this problem now affects any language. We propose simple tricks to overcome this problem, which are even applicable to languages without explicit word boundaries.
Frustratingly Easy Edit-based Linguistic Steganography with a Masked Language Model
Apr 20, 2021

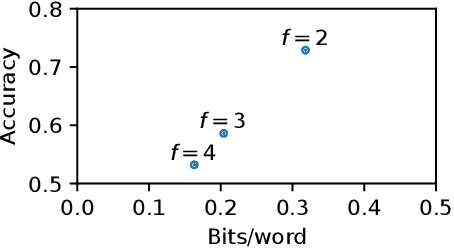

With advances in neural language models, the focus of linguistic steganography has shifted from edit-based approaches to generation-based ones. While the latter's payload capacity is impressive, generating genuine-looking texts remains challenging. In this paper, we revisit edit-based linguistic steganography, with the idea that a masked language model offers an off-the-shelf solution. The proposed method eliminates painstaking rule construction and has a high payload capacity for an edit-based model. It is also shown to be more secure against automatic detection than a generation-based method while offering better control of the security/payload capacity trade-off.