 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA: Unifying Parametric Human Body Models
Mar 17, 2026Parametric human body models are foundational to human reconstruction, animation, and simulation, yet they remain mutually incompatible: SMPL, SMPL-X, MHR, Anny, and related models each diverge in mesh topology, skeletal structure, shape parameterization, and unit convention, making it impractical to exploit their complementary strengths within a single pipeline. We present SOMA, a unified body layer that bridges these heterogeneous representations through three abstraction layers. Mesh topology abstraction maps any source model's identity to a shared canonical mesh in constant time per vertex. Skeletal abstraction recovers a full set of identity-adapted joint transforms from any body shape, whether in rest pose or an arbitrary posed configuration, in a single closed-form pass, with no iterative optimization or per-model training. Pose abstraction inverts the skinning pipeline to recover unified skeleton rotations directly from posed vertices of any supported model, enabling heterogeneous motion datasets to be consumed without custom retargeting. Together, these layers reduce the $O(M^2)$ per-pair adapter problem to $O(M)$ single-backend connectors, letting practitioners freely mix identity sources and pose data at inference time. The entire pipeline is fully differentiable end-to-end and GPU-accelerated via NVIDIA-Warp.
Neural Face Rigging for Animating and Retargeting Facial Meshes in the Wild
May 15, 2023We propose an end-to-end deep-learning approach for automatic rigging and retargeting of 3D models of human faces in the wild. Our approach, called Neural Face Rigging (NFR), holds three key properties: (i) NFR's expression space maintains human-interpretable editing parameters for artistic controls; (ii) NFR is readily applicable to arbitrary facial meshes with different connectivity and expressions; (iii) NFR can encode and produce fine-grained details of complex expressions performed by arbitrary subjects. To the best of our knowledge, NFR is the first approach to provide realistic and controllable deformations of in-the-wild facial meshes, without the manual creation of blendshapes or correspondence. We design a deformation autoencoder and train it through a multi-dataset training scheme, which benefits from the unique advantages of two data sources: a linear 3DMM with interpretable control parameters as in FACS, and 4D captures of real faces with fine-grained details. Through various experiments, we show NFR's ability to automatically produce realistic and accurate facial deformations across a wide range of existing datasets as well as noisy facial scans in-the-wild, while providing artist-controlled, editable parameters.
Skeleton-free Pose Transfer for Stylized 3D Characters
Jul 28, 2022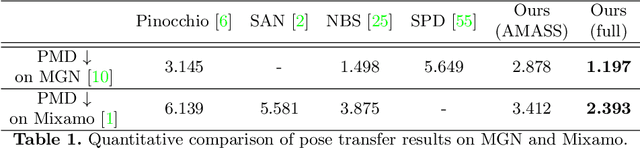
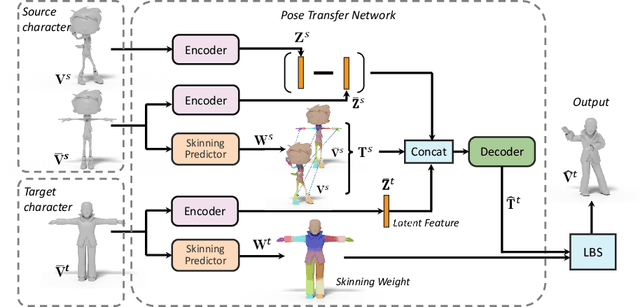
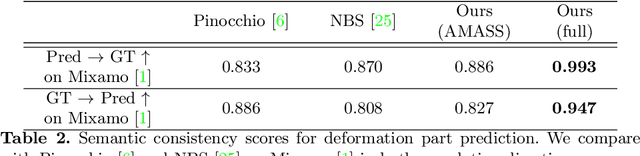

We present the first method that automatically transfers poses between stylized 3D characters without skeletal rigging. In contrast to previous attempts to learn pose transformations on fixed or topology-equivalent skeleton templates, our method focuses on a novel scenario to handle skeleton-free characters with diverse shapes, topologies, and mesh connectivities. The key idea of our method is to represent the characters in a unified articulation model so that the pose can be transferred through the correspondent parts. To achieve this, we propose a novel pose transfer network that predicts the character skinning weights and deformation transformations jointly to articulate the target character to match the desired pose. Our method is trained in a semi-supervised manner absorbing all existing character data with paired/unpaired poses and stylized shapes. It generalizes well to unseen stylized characters and inanimate objects. We conduct extensive experiments and demonstrate the effectiveness of our method on this novel task.
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022
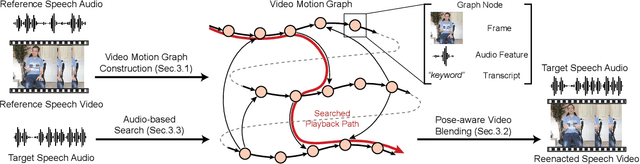
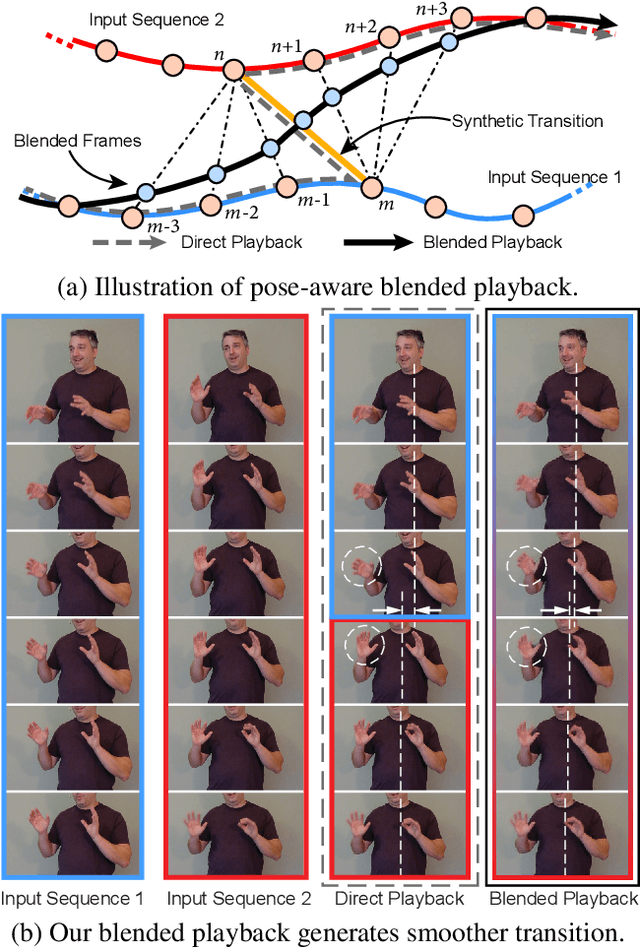
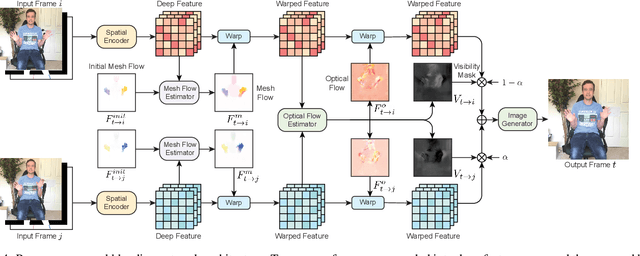
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.
NeMF: Neural Motion Fields for Kinematic Animation
Jun 04, 2022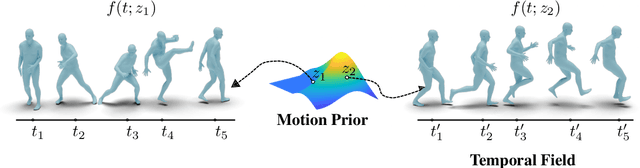
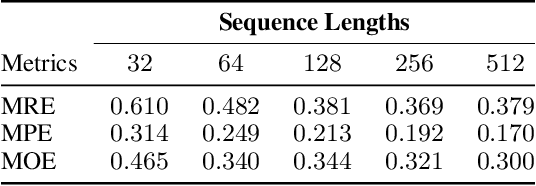

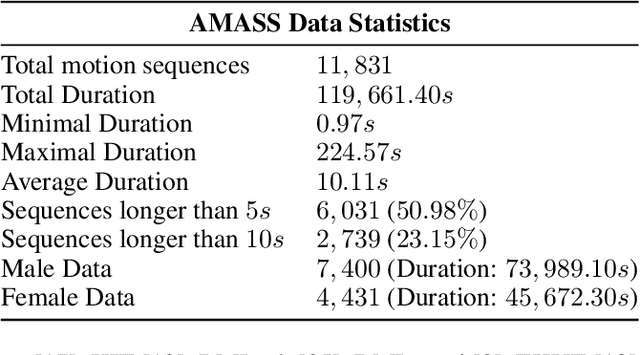
We present an implicit neural representation to learn the spatio-temporal space of kinematic motions. Unlike previous work that represents motion as discrete sequential samples, we propose to express the vast motion space as a continuous function over time, hence the name Neural Motion Fields (NeMF). Specifically, we use a neural network to learn this function for miscellaneous sets of motions, which is designed to be a generative model conditioned on a temporal coordinate $t$ and a random vector $z$ for controlling the style. The model is then trained as a Variational Autoencoder (VAE) with motion encoders to sample the latent space. We train our model with diverse human motion dataset and quadruped dataset to prove its versatility, and finally deploy it as a generic motion prior to solve task-agnostic problems and show its superiority in different motion generation and editing applications, such as motion interpolation, in-betweening, and re-navigating.
Neural Jacobian Fields: Learning Intrinsic Mappings of Arbitrary Meshes
May 05, 2022
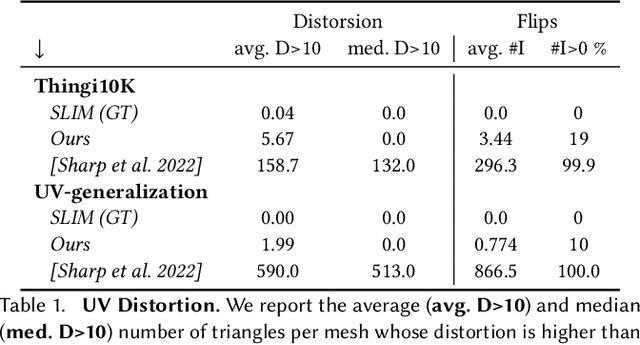

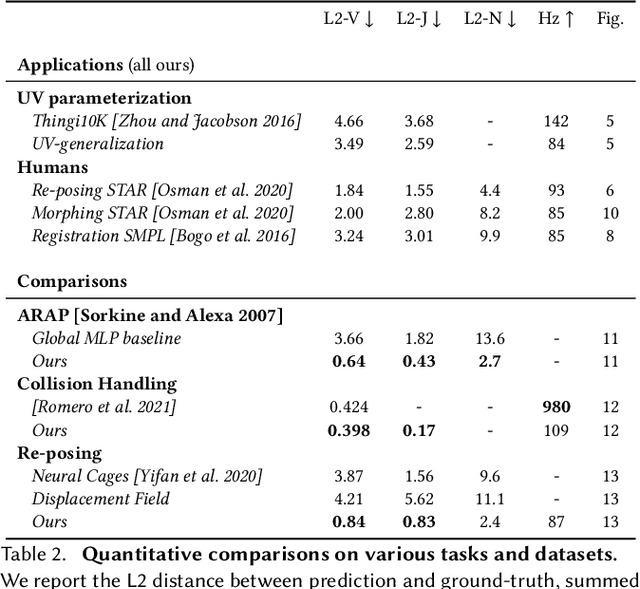
This paper introduces a framework designed to accurately predict piecewise linear mappings of arbitrary meshes via a neural network, enabling training and evaluating over heterogeneous collections of meshes that do not share a triangulation, as well as producing highly detail-preserving maps whose accuracy exceeds current state of the art. The framework is based on reducing the neural aspect to a prediction of a matrix for a single given point, conditioned on a global shape descriptor. The field of matrices is then projected onto the tangent bundle of the given mesh, and used as candidate jacobians for the predicted map. The map is computed by a standard Poisson solve, implemented as a differentiable layer with cached pre-factorization for efficient training. This construction is agnostic to the triangulation of the input, thereby enabling applications on datasets with varying triangulations. At the same time, by operating in the intrinsic gradient domain of each individual mesh, it allows the framework to predict highly-accurate mappings. We validate these properties by conducting experiments over a broad range of scenarios, from semantic ones such as morphing, registration, and deformation transfer, to optimization-based ones, such as emulating elastic deformations and contact correction, as well as being the first work, to our knowledge, to tackle the task of learning to compute UV parameterizations of arbitrary meshes. The results exhibit the high accuracy of the method as well as its versatility, as it is readily applied to the above scenarios without any changes to the framework.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 28, 2021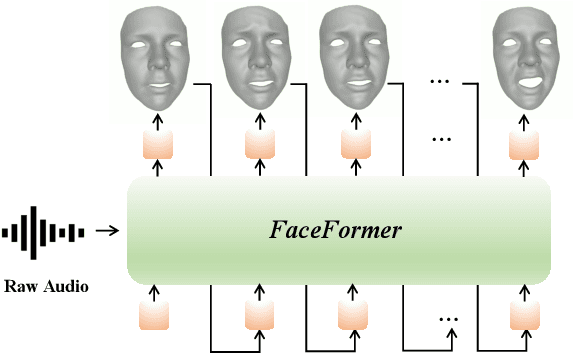
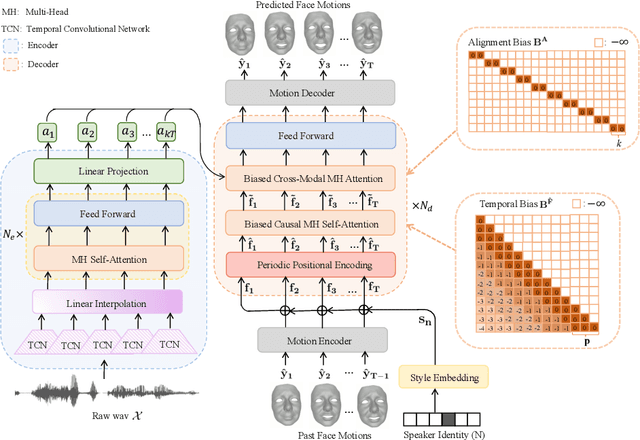

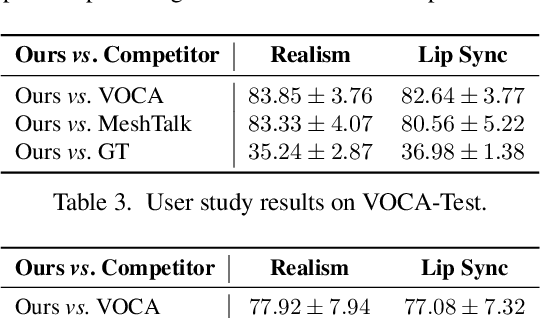
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. We encourage watching the video. The code will be made available.
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021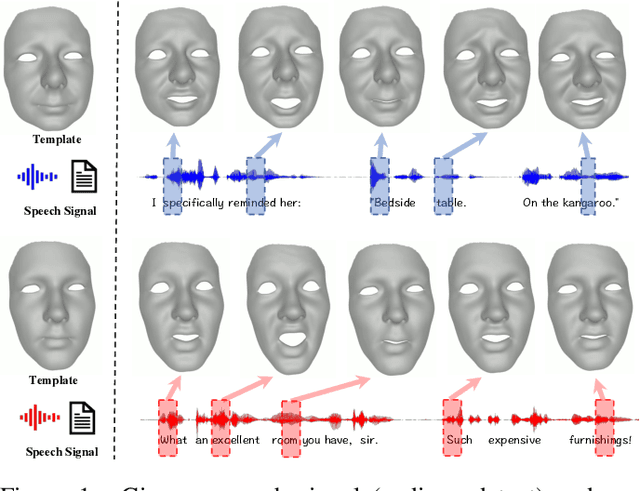
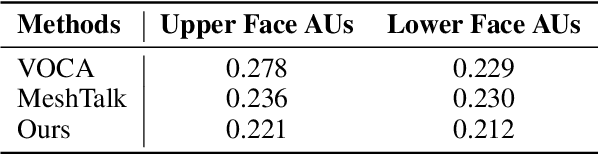
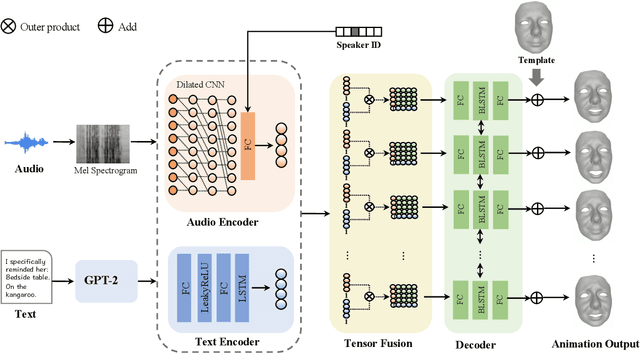
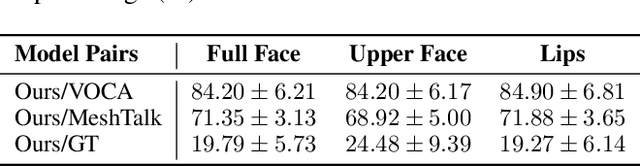
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
Contact-Aware Retargeting of Skinned Motion
Sep 15, 2021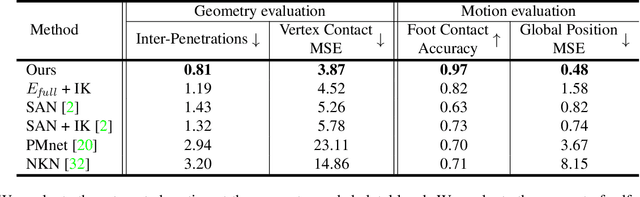
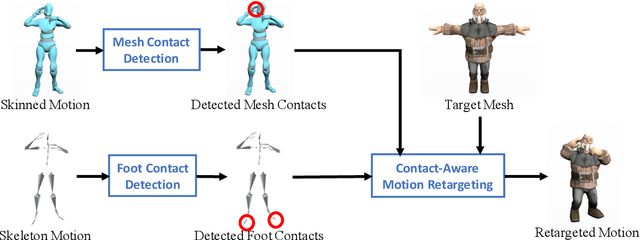

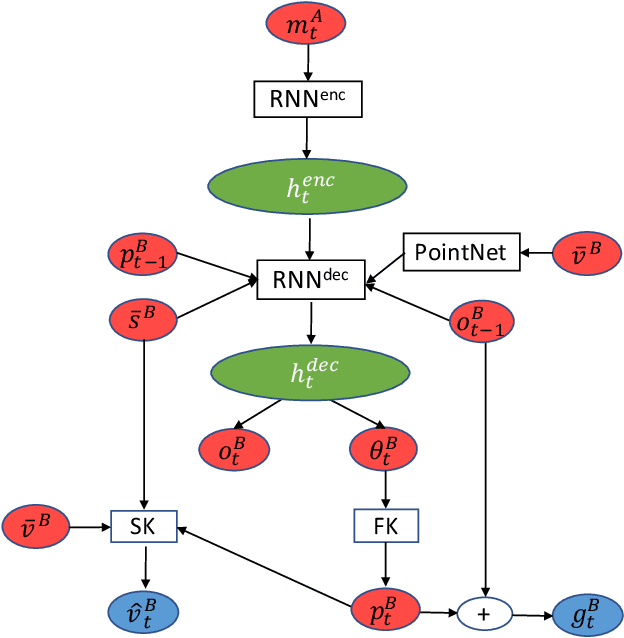
This paper introduces a motion retargeting method that preserves self-contacts and prevents interpenetration. Self-contacts, such as when hands touch each other or the torso or the head, are important attributes of human body language and dynamics, yet existing methods do not model or preserve these contacts. Likewise, interpenetration, such as a hand passing into the torso, are a typical artifact of motion estimation methods. The input to our method is a human motion sequence and a target skeleton and character geometry. The method identifies self-contacts and ground contacts in the input motion, and optimizes the motion to apply to the output skeleton, while preserving these contacts and reducing interpenetration. We introduce a novel geometry-conditioned recurrent network with an encoder-space optimization strategy that achieves efficient retargeting while satisfying contact constraints. In experiments, our results quantitatively outperform previous methods and we conduct a user study where our retargeted motions are rated as higher-quality than those produced by recent works. We also show our method generalizes to motion estimated from human videos where we improve over previous works that produce noticeable interpenetration.
Stochastic Scene-Aware Motion Prediction
Aug 18, 2021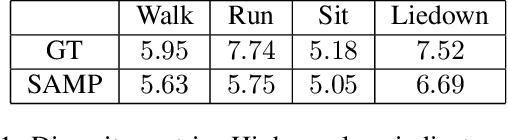

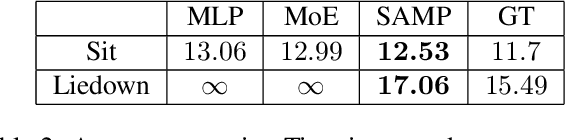

A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.