 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Paper and Code
Dec 07, 2021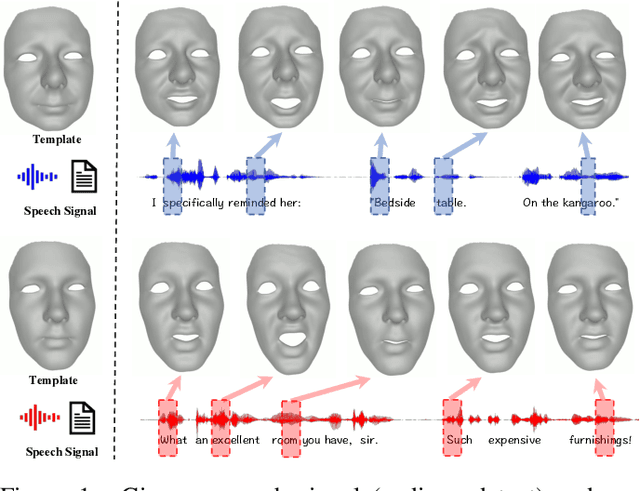
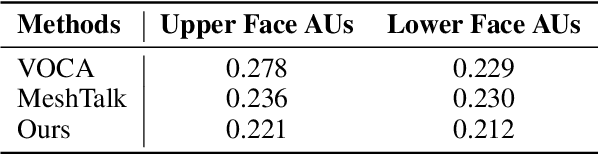
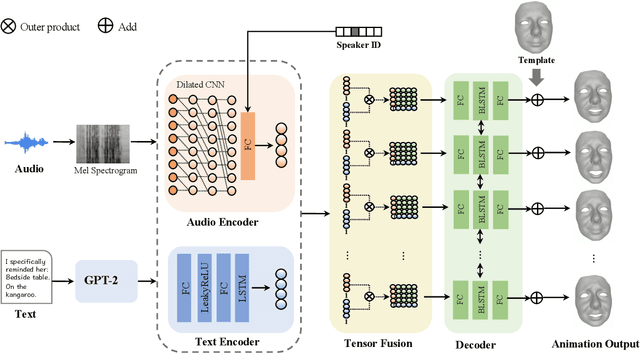
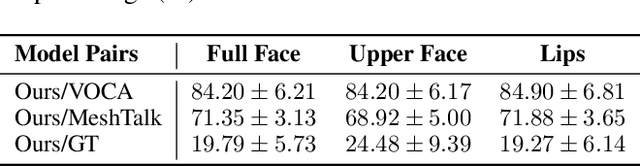
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.