 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrips as Tokens: Artist Mesh Generation with Native UV Segmentation
Apr 10, 2026Recent advancements in autoregressive transformers have demonstrated remarkable potential for generating artist-quality meshes. However, the token ordering strategies employed by existing methods typically fail to meet professional artist standards, where coordinate-based sorting yields inefficiently long sequences, and patch-based heuristics disrupt the continuous edge flow and structural regularity essential for high-quality modeling. To address these limitations, we propose Strips as Tokens (SATO), a novel framework with a token ordering strategy inspired by triangle strips. By constructing the sequence as a connected chain of faces that explicitly encodes UV boundaries, our method naturally preserves the organized edge flow and semantic layout characteristic of artist-created meshes. A key advantage of this formulation is its unified representation, enabling the same token sequence to be decoded into either a triangle or quadrilateral mesh. This flexibility facilitates joint training on both data types: large-scale triangle data provides fundamental structural priors, while high-quality quad data enhances the geometric regularity of the outputs. Extensive experiments demonstrate that SATO consistently outperforms prior methods in terms of geometric quality, structural coherence, and UV segmentation.
UNIC: Neural Garment Deformation Field for Real-time Clothed Character Animation
Mar 26, 2026Simulating physically realistic garment deformations is an essential task for virtual immersive experience, which is often achieved by physics simulation methods. However, these methods are typically time-consuming, computationally demanding, and require costly hardware, which is not suitable for real-time applications. Recent learning-based methods tried to resolve this problem by training graph neural networks to learn the garment deformation on vertices, which, however, fail to capture the intricate deformation of complex garment meshes with complex topologies. In this paper, we introduce a novel neural deformation field-based method, named UNIC, to animate the garments of an avatar in real time, given the motion sequences. Our key idea is to learn the instance-specific neural deformation field to animate the garment meshes. Such an instance-specific learning scheme does not require UNIC to generalize to new garments but only to new motion sequences, which greatly reduces the difficulty in training and improves the deformation quality. Moreover, neural deformation fields map the 3D points to their deformation offsets, which not only avoids handling topologies of the complex garments but also injects a natural smoothness constraint in the deformation learning. Extensive experiments have been conducted on various kinds of garment meshes to demonstrate the effectiveness and efficiency of UNIC over baseline methods, making it potentially practical and useful in real-world interactive applications like video games.
UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Mar 16, 2026Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
EmbodMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents
Feb 26, 2026Human behaviors in the real world naturally encode rich, long-term contextual information that can be leveraged to train embodied agents for perception, understanding, and acting. However, existing capture systems typically rely on costly studio setups and wearable devices, limiting the large-scale collection of scene-conditioned human motion data in the wild. To address this, we propose EmbodMocap, a portable and affordable data collection pipeline using two moving iPhones. Our key idea is to jointly calibrate dual RGB-D sequences to reconstruct both humans and scenes within a unified metric world coordinate frame. The proposed method allows metric-scale and scene-consistent capture in everyday environments without static cameras or markers, bridging human motion and scene geometry seamlessly. Compared with optical capture ground truth, we demonstrate that the dual-view setting exhibits a remarkable ability to mitigate depth ambiguity, achieving superior alignment and reconstruction performance over single iphone or monocular models. Based on the collected data, we empower three embodied AI tasks: monocular human-scene-reconstruction, where we fine-tune on feedforward models that output metric-scale, world-space aligned humans and scenes; physics-based character animation, where we prove our data could be used to scale human-object interaction skills and scene-aware motion tracking; and robot motion control, where we train a humanoid robot via sim-to-real RL to replicate human motions depicted in videos. Experimental results validate the effectiveness of our pipeline and its contributions towards advancing embodied AI research.
SceMoS: Scene-Aware 3D Human Motion Synthesis by Planning with Geometry-Grounded Tokens
Feb 24, 2026Synthesizing text-driven 3D human motion within realistic scenes requires learning both semantic intent ("walk to the couch") and physical feasibility (e.g., avoiding collisions). Current methods use generative frameworks that simultaneously learn high-level planning and low-level contact reasoning, and rely on computationally expensive 3D scene data such as point clouds or voxel occupancy grids. We propose SceMoS, a scene-aware motion synthesis framework that shows that structured 2D scene representations can serve as a powerful alternative to full 3D supervision in physically grounded motion synthesis. SceMoS disentangles global planning from local execution using lightweight 2D cues and relying on (1) a text-conditioned autoregressive global motion planner that operates on a bird's-eye-view (BEV) image rendered from an elevated corner of the scene, encoded with DINOv2 features, as the scene representation, and (2) a geometry-grounded motion tokenizer trained via a conditional VQ-VAE, that uses 2D local scene heightmap, thus embedding surface physics directly into a discrete vocabulary. This 2D factorization reaches an efficiency-fidelity trade-off: BEV semantics capture spatial layout and affordance for global reasoning, while local heightmaps enforce fine-grained physical adherence without full 3D volumetric reasoning. SceMoS achieves state-of-the-art motion realism and contact accuracy on the TRUMANS benchmark, reducing the number of trainable parameters for scene encoding by over 50%, showing that 2D scene cues can effectively ground 3D human-scene interaction.
EgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Dec 28, 2025Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video-reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.
Motion2Motion: Cross-topology Motion Transfer with Sparse Correspondence
Aug 18, 2025

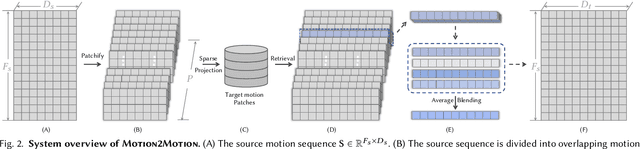

This work studies the challenge of transfer animations between characters whose skeletal topologies differ substantially. While many techniques have advanced retargeting techniques in decades, transfer motions across diverse topologies remains less-explored. The primary obstacle lies in the inherent topological inconsistency between source and target skeletons, which restricts the establishment of straightforward one-to-one bone correspondences. Besides, the current lack of large-scale paired motion datasets spanning different topological structures severely constrains the development of data-driven approaches. To address these limitations, we introduce Motion2Motion, a novel, training-free framework. Simply yet effectively, Motion2Motion works with only one or a few example motions on the target skeleton, by accessing a sparse set of bone correspondences between the source and target skeletons. Through comprehensive qualitative and quantitative evaluations, we demonstrate that Motion2Motion achieves efficient and reliable performance in both similar-skeleton and cross-species skeleton transfer scenarios. The practical utility of our approach is further evidenced by its successful integration in downstream applications and user interfaces, highlighting its potential for industrial applications. Code and data are available at https://lhchen.top/Motion2Motion.
MOSPA: Human Motion Generation Driven by Spatial Audio
Jul 16, 2025Enabling virtual humans to dynamically and realistically respond to diverse auditory stimuli remains a key challenge in character animation, demanding the integration of perceptual modeling and motion synthesis. Despite its significance, this task remains largely unexplored. Most previous works have primarily focused on mapping modalities like speech, audio, and music to generate human motion. As of yet, these models typically overlook the impact of spatial features encoded in spatial audio signals on human motion. To bridge this gap and enable high-quality modeling of human movements in response to spatial audio, we introduce the first comprehensive Spatial Audio-Driven Human Motion (SAM) dataset, which contains diverse and high-quality spatial audio and motion data. For benchmarking, we develop a simple yet effective diffusion-based generative framework for human MOtion generation driven by SPatial Audio, termed MOSPA, which faithfully captures the relationship between body motion and spatial audio through an effective fusion mechanism. Once trained, MOSPA could generate diverse realistic human motions conditioned on varying spatial audio inputs. We perform a thorough investigation of the proposed dataset and conduct extensive experiments for benchmarking, where our method achieves state-of-the-art performance on this task. Our model and dataset will be open-sourced upon acceptance. Please refer to our supplementary video for more details.
CoDA: Coordinated Diffusion Noise Optimization for Whole-Body Manipulation of Articulated Objects
May 27, 2025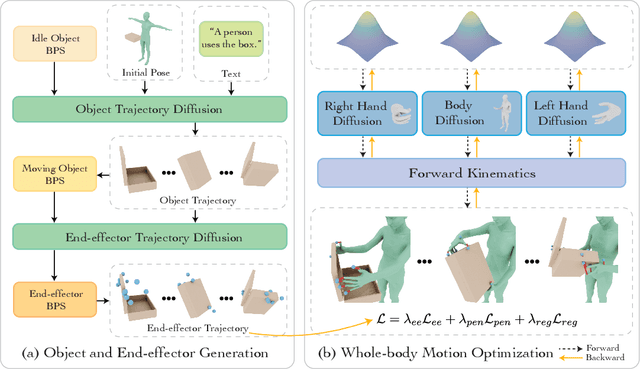
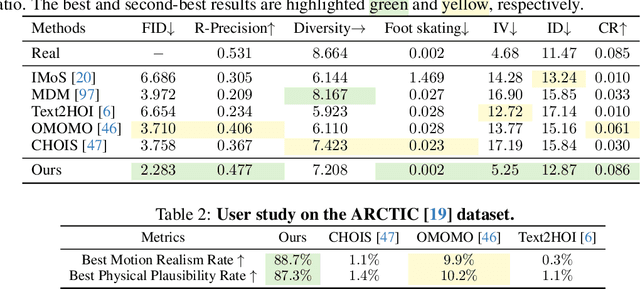
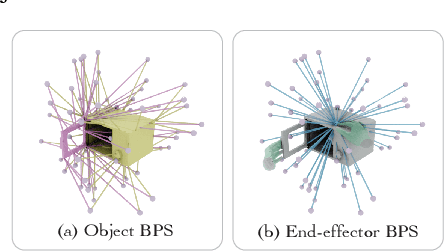
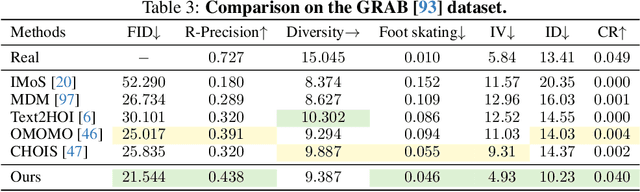
Synthesizing whole-body manipulation of articulated objects, including body motion, hand motion, and object motion, is a critical yet challenging task with broad applications in virtual humans and robotics. The core challenges are twofold. First, achieving realistic whole-body motion requires tight coordination between the hands and the rest of the body, as their movements are interdependent during manipulation. Second, articulated object manipulation typically involves high degrees of freedom and demands higher precision, often requiring the fingers to be placed at specific regions to actuate movable parts. To address these challenges, we propose a novel coordinated diffusion noise optimization framework. Specifically, we perform noise-space optimization over three specialized diffusion models for the body, left hand, and right hand, each trained on its own motion dataset to improve generalization. Coordination naturally emerges through gradient flow along the human kinematic chain, allowing the global body posture to adapt in response to hand motion objectives with high fidelity. To further enhance precision in hand-object interaction, we adopt a unified representation based on basis point sets (BPS), where end-effector positions are encoded as distances to the same BPS used for object geometry. This unified representation captures fine-grained spatial relationships between the hand and articulated object parts, and the resulting trajectories serve as targets to guide the optimization of diffusion noise, producing highly accurate interaction motion. We conduct extensive experiments demonstrating that our method outperforms existing approaches in motion quality and physical plausibility, and enables various capabilities such as object pose control, simultaneous walking and manipulation, and whole-body generation from hand-only data.
CBIL: Collective Behavior Imitation Learning for Fish from Real Videos
Mar 31, 2025
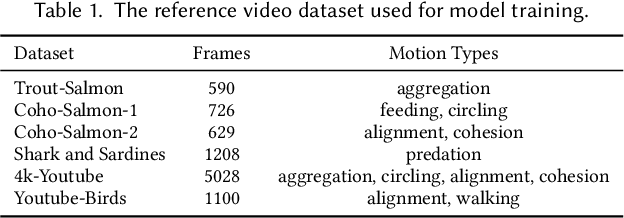

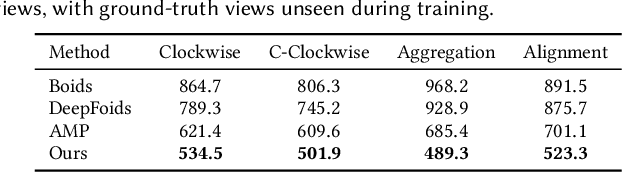
Reproducing realistic collective behaviors presents a captivating yet formidable challenge. Traditional rule-based methods rely on hand-crafted principles, limiting motion diversity and realism in generated collective behaviors. Recent imitation learning methods learn from data but often require ground truth motion trajectories and struggle with authenticity, especially in high-density groups with erratic movements. In this paper, we present a scalable approach, Collective Behavior Imitation Learning (CBIL), for learning fish schooling behavior directly from videos, without relying on captured motion trajectories. Our method first leverages Video Representation Learning, where a Masked Video AutoEncoder (MVAE) extracts implicit states from video inputs in a self-supervised manner. The MVAE effectively maps 2D observations to implicit states that are compact and expressive for following the imitation learning stage. Then, we propose a novel adversarial imitation learning method to effectively capture complex movements of the schools of fish, allowing for efficient imitation of the distribution for motion patterns measured in the latent space. It also incorporates bio-inspired rewards alongside priors to regularize and stabilize training. Once trained, CBIL can be used for various animation tasks with the learned collective motion priors. We further show its effectiveness across different species. Finally, we demonstrate the application of our system in detecting abnormal fish behavior from in-the-wild videos.