 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
Motion2Motion: Cross-topology Motion Transfer with Sparse Correspondence
Aug 18, 2025

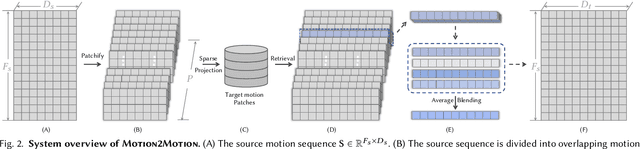

This work studies the challenge of transfer animations between characters whose skeletal topologies differ substantially. While many techniques have advanced retargeting techniques in decades, transfer motions across diverse topologies remains less-explored. The primary obstacle lies in the inherent topological inconsistency between source and target skeletons, which restricts the establishment of straightforward one-to-one bone correspondences. Besides, the current lack of large-scale paired motion datasets spanning different topological structures severely constrains the development of data-driven approaches. To address these limitations, we introduce Motion2Motion, a novel, training-free framework. Simply yet effectively, Motion2Motion works with only one or a few example motions on the target skeleton, by accessing a sparse set of bone correspondences between the source and target skeletons. Through comprehensive qualitative and quantitative evaluations, we demonstrate that Motion2Motion achieves efficient and reliable performance in both similar-skeleton and cross-species skeleton transfer scenarios. The practical utility of our approach is further evidenced by its successful integration in downstream applications and user interfaces, highlighting its potential for industrial applications. Code and data are available at https://lhchen.top/Motion2Motion.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025

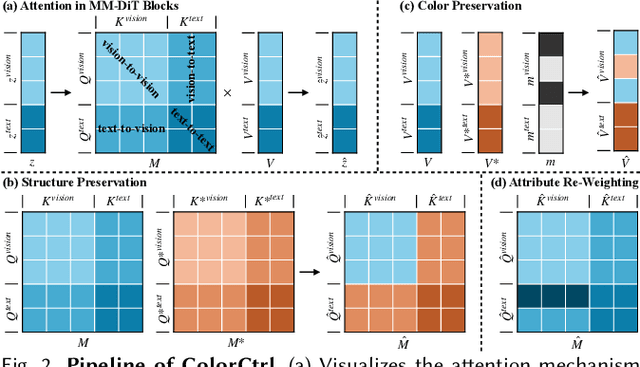
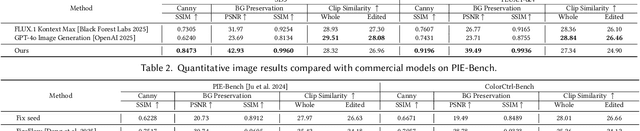
Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors
Dec 07, 2022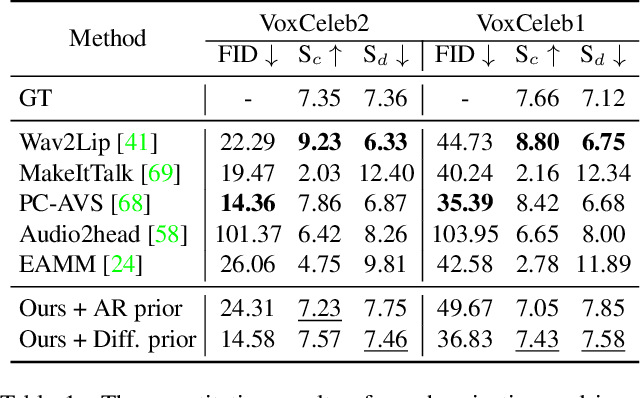
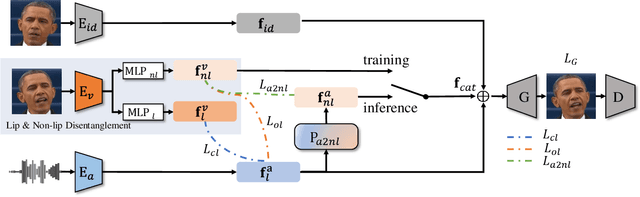
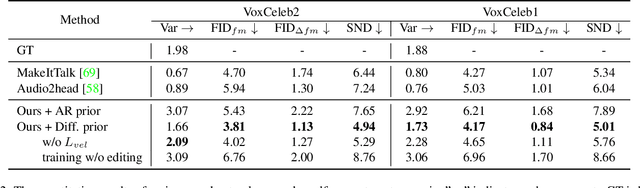
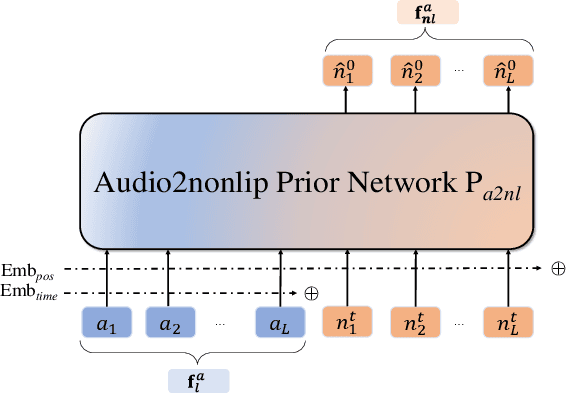
In this paper, we introduce a simple and novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead probabilistically sample all the holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and the overall naturalness. This is achieved by our newly proposed audio-to-visual diffusion prior trained on top of the mapping between audio and disentangled non-lip facial representations. Thanks to the probabilistic nature of the diffusion prior, one big advantage of our framework is it can synthesize diverse facial motion sequences given the same audio clip, which is quite user-friendly for many real applications. Through comprehensive evaluations on public benchmarks, we conclude that (1) our diffusion prior outperforms auto-regressive prior significantly on almost all the concerned metrics; (2) our overall system is competitive with prior works in terms of audio-lip synchronization but can effectively sample rich and natural-looking lip-irrelevant facial motions while still semantically harmonized with the audio input.
Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis
Nov 26, 2022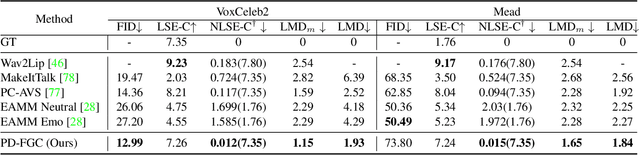
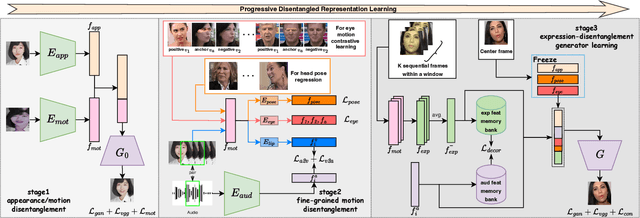
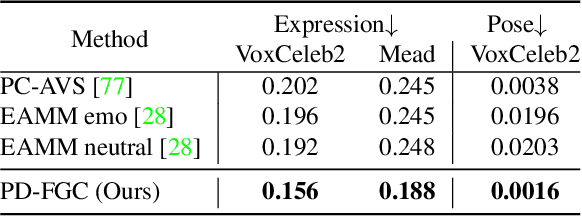

We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. To effectively disentangle each motion factor, we propose a progressive disentangled representation learning strategy by separating the factors in a coarse-to-fine manner, where we first extract unified motion feature from the driving signal, and then isolate each fine-grained motion from the unified feature. We introduce motion-specific contrastive learning and regressing for non-emotional motions, and feature-level decorrelation and self-reconstruction for emotional expression, to fully utilize the inherent properties of each motion factor in unstructured video data to achieve disentanglement. Experiments show that our method provides high quality speech&lip-motion synchronization along with precise and disentangled control over multiple extra facial motions, which can hardly be achieved by previous methods.
Phonemic Adversarial Attack against Audio Recognition in Real World
Nov 19, 2022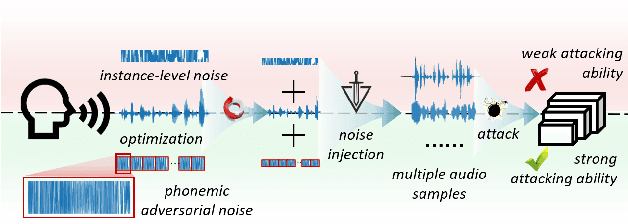
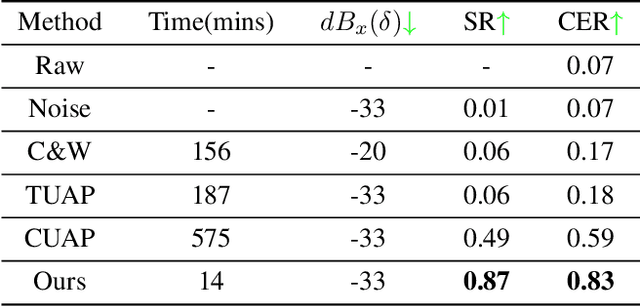
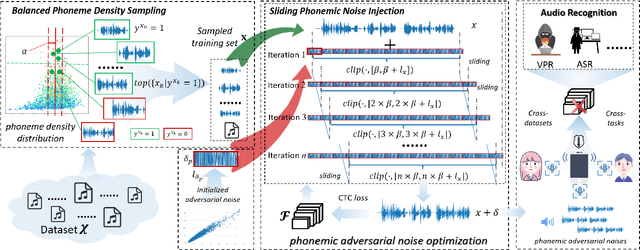

Recently, adversarial attacks for audio recognition have attracted much attention. However, most of the existing studies mainly rely on the coarse-grain audio features at the instance level to generate adversarial noises, which leads to expensive generation time costs and weak universal attacking ability. Motivated by the observations that all audio speech consists of fundamental phonemes, this paper proposes a phonemic adversarial tack (PAT) paradigm, which attacks the fine-grain audio features at the phoneme level commonly shared across audio instances, to generate phonemic adversarial noises, enjoying the more general attacking ability with fast generation speed. Specifically, for accelerating the generation, a phoneme density balanced sampling strategy is introduced to sample quantity less but phonemic features abundant audio instances as the training data via estimating the phoneme density, which substantially alleviates the heavy dependency on the large training dataset. Moreover, for promoting universal attacking ability, the phonemic noise is optimized in an asynchronous way with a sliding window, which enhances the phoneme diversity and thus well captures the critical fundamental phonemic patterns. By conducting extensive experiments, we comprehensively investigate the proposed PAT framework and demonstrate that it outperforms the SOTA baselines by large margins (i.e., at least 11X speed up and 78% attacking ability improvement).
Towards Comprehensive Testing on the Robustness of Cooperative Multi-agent Reinforcement Learning
Apr 17, 2022
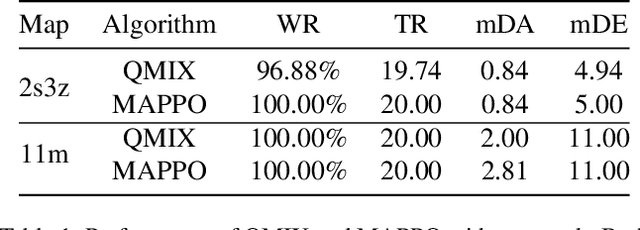

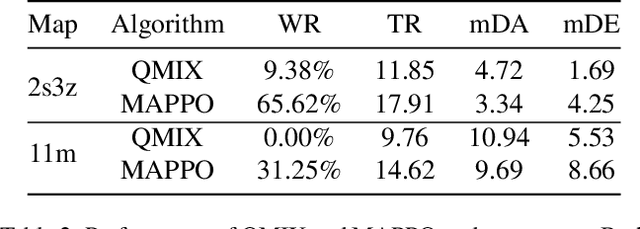
While deep neural networks (DNNs) have strengthened the performance of cooperative multi-agent reinforcement learning (c-MARL), the agent policy can be easily perturbed by adversarial examples. Considering the safety critical applications of c-MARL, such as traffic management, power management and unmanned aerial vehicle control, it is crucial to test the robustness of c-MARL algorithm before it was deployed in reality. Existing adversarial attacks for MARL could be used for testing, but is limited to one robustness aspects (e.g., reward, state, action), while c-MARL model could be attacked from any aspect. To overcome the challenge, we propose MARLSafe, the first robustness testing framework for c-MARL algorithms. First, motivated by Markov Decision Process (MDP), MARLSafe consider the robustness of c-MARL algorithms comprehensively from three aspects, namely state robustness, action robustness and reward robustness. Any c-MARL algorithm must simultaneously satisfy these robustness aspects to be considered secure. Second, due to the scarceness of c-MARL attack, we propose c-MARL attacks as robustness testing algorithms from multiple aspects. Experiments on \textit{SMAC} environment reveals that many state-of-the-art c-MARL algorithms are of low robustness in all aspect, pointing out the urgent need to test and enhance robustness of c-MARL algorithms.
Defensive Patches for Robust Recognition in the Physical World
Apr 13, 2022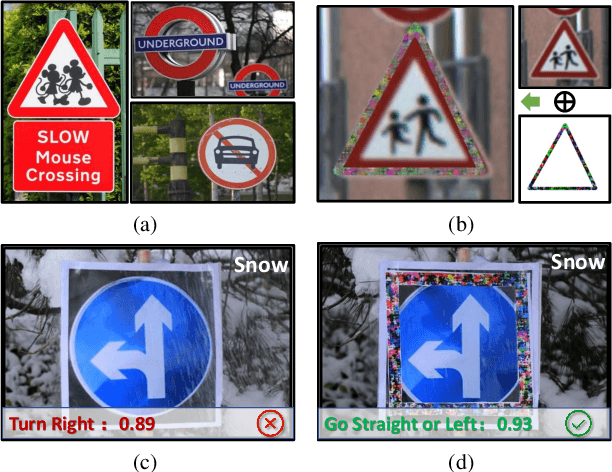
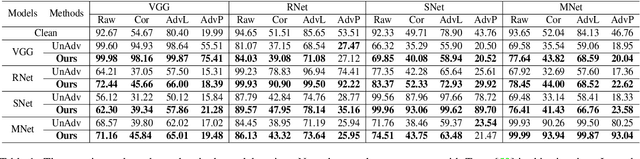
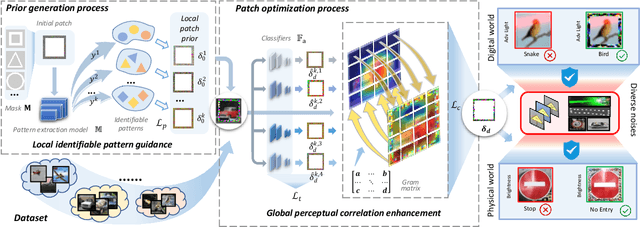
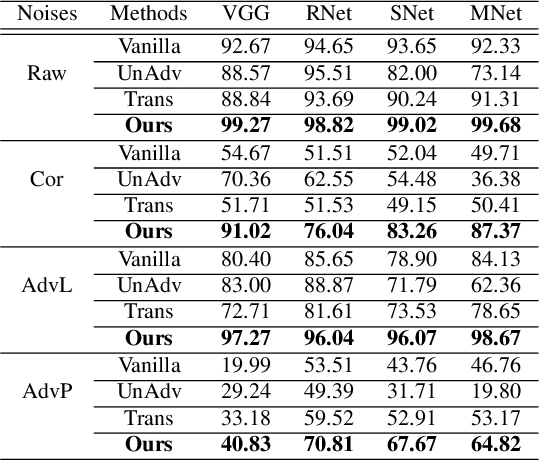
To operate in real-world high-stakes environments, deep learning systems have to endure noises that have been continuously thwarting their robustness. Data-end defense, which improves robustness by operations on input data instead of modifying models, has attracted intensive attention due to its feasibility in practice. However, previous data-end defenses show low generalization against diverse noises and weak transferability across multiple models. Motivated by the fact that robust recognition depends on both local and global features, we propose a defensive patch generation framework to address these problems by helping models better exploit these features. For the generalization against diverse noises, we inject class-specific identifiable patterns into a confined local patch prior, so that defensive patches could preserve more recognizable features towards specific classes, leading models for better recognition under noises. For the transferability across multiple models, we guide the defensive patches to capture more global feature correlations within a class, so that they could activate model-shared global perceptions and transfer better among models. Our defensive patches show great potentials to improve application robustness in practice by simply sticking them around target objects. Extensive experiments show that we outperform others by large margins (improve 20+\% accuracy for both adversarial and corruption robustness on average in the digital and physical world). Our codes are available at https://github.com/nlsde-safety-team/DefensivePatch
Dual Attention Suppression Attack: Generate Adversarial Camouflage in Physical World
Mar 01, 2021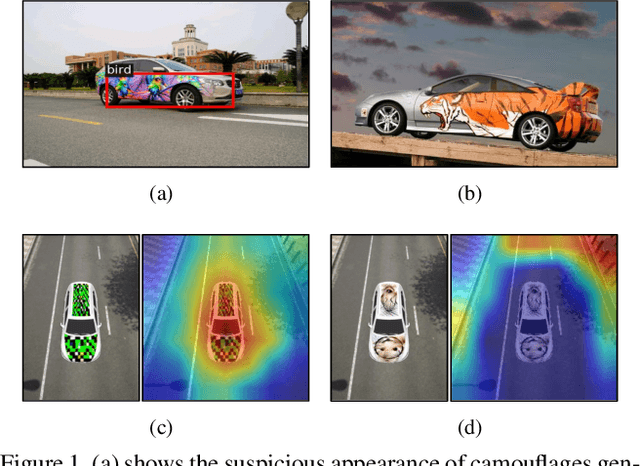
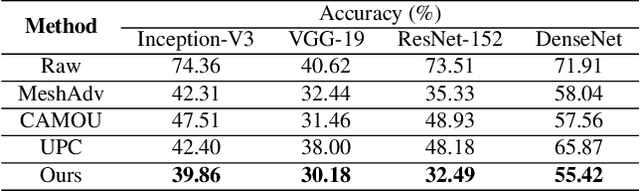
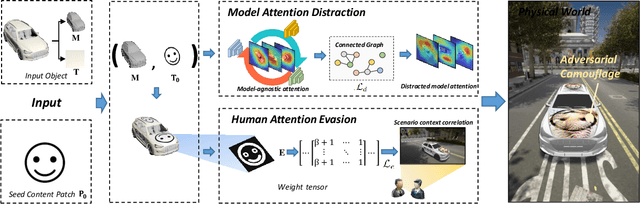
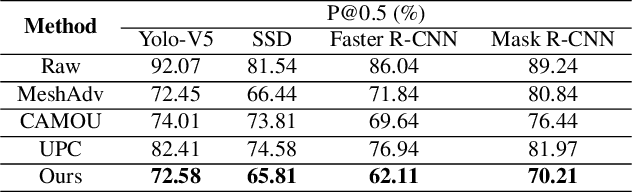
Deep learning models are vulnerable to adversarial examples. As a more threatening type for practical deep learning systems, physical adversarial examples have received extensive research attention in recent years. However, without exploiting the intrinsic characteristics such as model-agnostic and human-specific patterns, existing works generate weak adversarial perturbations in the physical world, which fall short of attacking across different models and show visually suspicious appearance. Motivated by the viewpoint that attention reflects the intrinsic characteristics of the recognition process, this paper proposes the Dual Attention Suppression (DAS) attack to generate visually-natural physical adversarial camouflages with strong transferability by suppressing both model and human attention. As for attacking, we generate transferable adversarial camouflages by distracting the model-shared similar attention patterns from the target to non-target regions. Meanwhile, based on the fact that human visual attention always focuses on salient items (e.g., suspicious distortions), we evade the human-specific bottom-up attention to generate visually-natural camouflages which are correlated to the scenario context. We conduct extensive experiments in both the digital and physical world for classification and detection tasks on up-to-date models (e.g., Yolo-V5) and significantly demonstrate that our method outperforms state-of-the-art methods.