 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhonemic Adversarial Attack against Audio Recognition in Real World
Paper and Code
Nov 19, 2022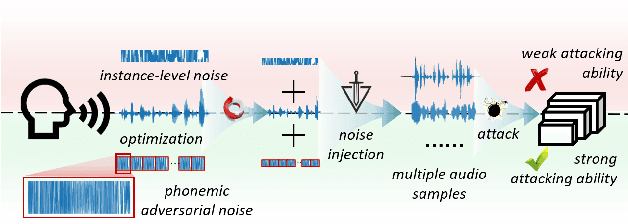
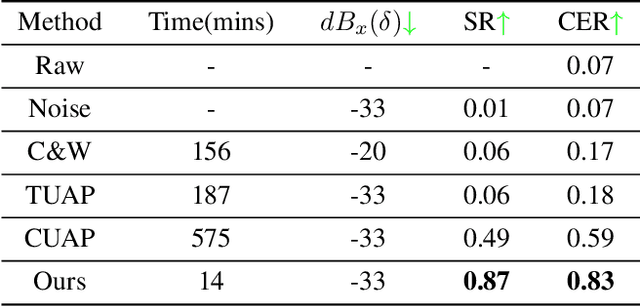
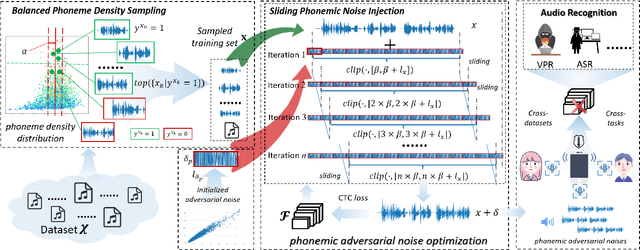

Recently, adversarial attacks for audio recognition have attracted much attention. However, most of the existing studies mainly rely on the coarse-grain audio features at the instance level to generate adversarial noises, which leads to expensive generation time costs and weak universal attacking ability. Motivated by the observations that all audio speech consists of fundamental phonemes, this paper proposes a phonemic adversarial tack (PAT) paradigm, which attacks the fine-grain audio features at the phoneme level commonly shared across audio instances, to generate phonemic adversarial noises, enjoying the more general attacking ability with fast generation speed. Specifically, for accelerating the generation, a phoneme density balanced sampling strategy is introduced to sample quantity less but phonemic features abundant audio instances as the training data via estimating the phoneme density, which substantially alleviates the heavy dependency on the large training dataset. Moreover, for promoting universal attacking ability, the phonemic noise is optimized in an asynchronous way with a sliding window, which enhances the phoneme diversity and thus well captures the critical fundamental phonemic patterns. By conducting extensive experiments, we comprehensively investigate the proposed PAT framework and demonstrate that it outperforms the SOTA baselines by large margins (i.e., at least 11X speed up and 78% attacking ability improvement).