 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic MILP Model Construction for Multi-Robot Task Allocation and Scheduling Based on Large Language Models
Mar 18, 2025With the accelerated development of Industry 4.0, intelligent manufacturing systems increasingly require efficient task allocation and scheduling in multi-robot systems. However, existing methods rely on domain expertise and face challenges in adapting to dynamic production constraints. Additionally, enterprises have high privacy requirements for production scheduling data, which prevents the use of cloud-based large language models (LLMs) for solution development. To address these challenges, there is an urgent need for an automated modeling solution that meets data privacy requirements. This study proposes a knowledge-augmented mixed integer linear programming (MILP) automated formulation framework, integrating local LLMs with domain-specific knowledge bases to generate executable code from natural language descriptions automatically. The framework employs a knowledge-guided DeepSeek-R1-Distill-Qwen-32B model to extract complex spatiotemporal constraints (82% average accuracy) and leverages a supervised fine-tuned Qwen2.5-Coder-7B-Instruct model for efficient MILP code generation (90% average accuracy). Experimental results demonstrate that the framework successfully achieves automatic modeling in the aircraft skin manufacturing case while ensuring data privacy and computational efficiency. This research provides a low-barrier and highly reliable technical path for modeling in complex industrial scenarios.
MNER-QG: An End-to-End MRC framework for Multimodal Named Entity Recognition with Query Grounding
Nov 27, 2022

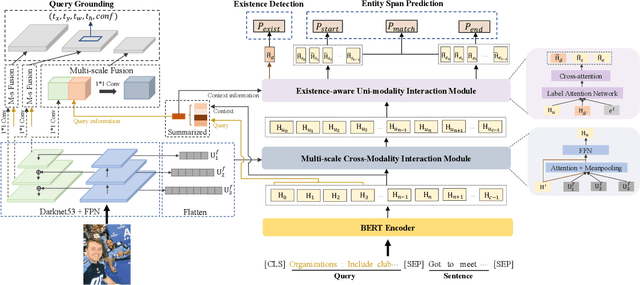
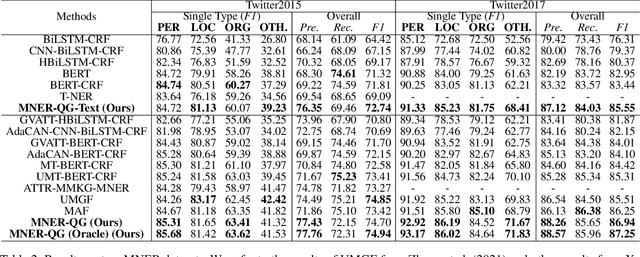
Multimodal named entity recognition (MNER) is a critical step in information extraction, which aims to detect entity spans and classify them to corresponding entity types given a sentence-image pair. Existing methods either (1) obtain named entities with coarse-grained visual clues from attention mechanisms, or (2) first detect fine-grained visual regions with toolkits and then recognize named entities. However, they suffer from improper alignment between entity types and visual regions or error propagation in the two-stage manner, which finally imports irrelevant visual information into texts. In this paper, we propose a novel end-to-end framework named MNER-QG that can simultaneously perform MRC-based multimodal named entity recognition and query grounding. Specifically, with the assistance of queries, MNER-QG can provide prior knowledge of entity types and visual regions, and further enhance representations of both texts and images. To conduct the query grounding task, we provide manual annotations and weak supervisions that are obtained via training a highly flexible visual grounding model with transfer learning. We conduct extensive experiments on two public MNER datasets, Twitter2015 and Twitter2017. Experimental results show that MNER-QG outperforms the current state-of-the-art models on the MNER task, and also improves the query grounding performance.
Phonemic Adversarial Attack against Audio Recognition in Real World
Nov 19, 2022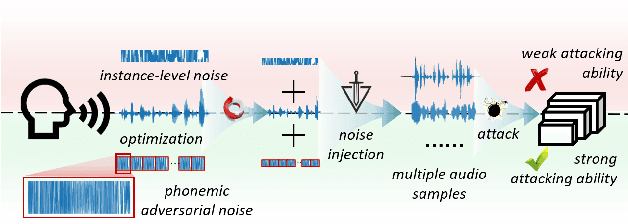
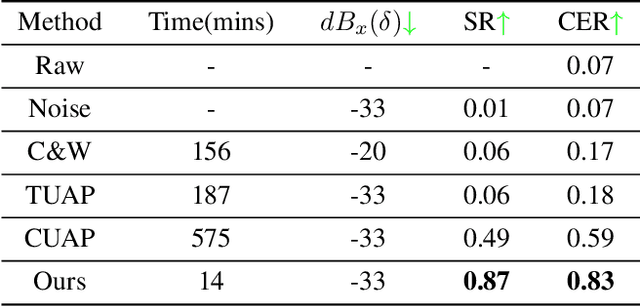
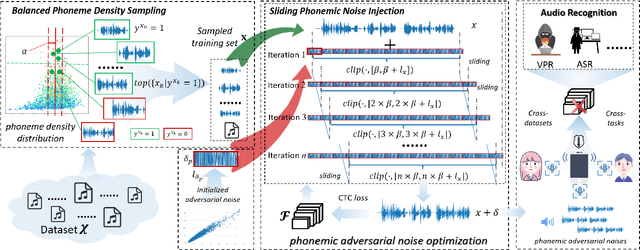

Recently, adversarial attacks for audio recognition have attracted much attention. However, most of the existing studies mainly rely on the coarse-grain audio features at the instance level to generate adversarial noises, which leads to expensive generation time costs and weak universal attacking ability. Motivated by the observations that all audio speech consists of fundamental phonemes, this paper proposes a phonemic adversarial tack (PAT) paradigm, which attacks the fine-grain audio features at the phoneme level commonly shared across audio instances, to generate phonemic adversarial noises, enjoying the more general attacking ability with fast generation speed. Specifically, for accelerating the generation, a phoneme density balanced sampling strategy is introduced to sample quantity less but phonemic features abundant audio instances as the training data via estimating the phoneme density, which substantially alleviates the heavy dependency on the large training dataset. Moreover, for promoting universal attacking ability, the phonemic noise is optimized in an asynchronous way with a sliding window, which enhances the phoneme diversity and thus well captures the critical fundamental phonemic patterns. By conducting extensive experiments, we comprehensively investigate the proposed PAT framework and demonstrate that it outperforms the SOTA baselines by large margins (i.e., at least 11X speed up and 78% attacking ability improvement).