 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTryOn: Video Try-On Anything at Once!
Jun 07, 2026Although video virtual try-on (VVT) has achieved significant progress, existing methods still exhibit two fundamental limitations: first, they are restricted to single-garment transfer, rendering simultaneous multi-object try-on highly impractical; second, their heavy reliance on explicit external priors (e.g., garment masks) inevitably destroys crucial physical dynamics and degrades visual quality. To bridge this gap, this paper proposes the novel Try-On Anything task, which aims to simultaneously transfer diverse wearable objects onto a person in a video in a single inference pass. To support and standardize this paradigm, we introduce TryAny-Bench, a comprehensive benchmark encompassing a paired video dataset alongside a tailored evaluation protocol. Furthermore, we present OmniTryOn, an external-prior-free generative framework designed to tackle this task. Specifically, OmniTryOn employs a First Frame Wearable Cache strategy, which directly provides diverse wearable objects for the generation process through the initial video frame. To maintain consistency, we propose the Spatiotemporally Consistent RoPE (STC-RoPE), which inherently establishes robust spatiotemporal anchors to strictly preserve complex human motions and background dynamics. Optimized by the proposed Gradual Try-On (GTO) training strategy, our model progressively masters robust multi-object synthesis. Extensive experiments on TryAny-Bench demonstrate that OmniTryOn significantly outperforms existing specialized video virtual try-on models and general video editing baselines, establishing a powerful new standard for the Try-On Anything task. Our dataset, code, and models are available at https://github.com/xcltql666/OminTryOn.
Echo: Learning from Experience Data via User-Driven Refinement
May 21, 2026Static "human data" faces inherent limitations: it is expensive to scale and bounded by the knowledge of its creators. Continuous learning from "experience data" - interactions between agents and their environments - promises to transcend these barriers. Today, the widespread deployment of AI agents grants us low-cost access to massive streams of such real-world experience. However, raw interaction logs are inherently noisy, filled with trial-and-error and low information density, rendering them inefficient for direct model training. We introduce Echo, a generalized framework designed to operationalize the transition from raw experience to learnable knowledge, effectively "echoing" environmental feedback back into the training loop for model optimization. In today's agent ecosystem, user refinement serves as a primary source of such feedback: driven by responsibility for the outcome, users rigorously transform flawed agent proposals into verified solutions. These user-driven refinement sequences inherently distill agents' crude attempts into high-quality training signals. Echo systematically harvests these signals to continuously align the agent with real-world needs. Large-scale validation in a production code completion environment confirms that Echo effectively harnesses this pipeline, breaking the static performance ceiling by increasing the acceptance rate from 25.7% to 35.7%.
Break the Brake, Not the Wheel: Untargeted Jailbreak via Entropy Maximization
May 11, 2026Recent studies show that gradient-based universal image jailbreaks on vision-language models (VLMs) exhibit little or no cross-model transferability, casting doubt on the feasibility of transferable multimodal jailbreaks. We revisit this conclusion under a strictly untargeted threat model without enforcing a fixed prefix or response pattern. Our preliminary experiment reveals that refusal behavior concentrates at high-entropy tokens during autoregressive decoding, and non-refusal tokens already carry substantial probability mass among the top-ranked candidates before attack. Motivated by this finding, we propose Untargeted Jailbreak via Entropy Maximization(UJEM)-KL, a lightweight attack that maximizes entropy at these decision tokens to flip refusal outcomes, while stabilizing the remaining low-entropy positions to preserve output quality. Across three VLMs and two safety benchmarks, UJEM-KL achieves competitive white-box attack success rates and consistently improves transferability, while remaining effective under representative defenses. Our experimental results indicate that the limited transferability primarily stems from overly constrained optimization objectives.
Cutscene Agent: An LLM Agent Framework for Automated 3D Cutscene Generation
Apr 28, 2026Cutscenes are carefully choreographed cinematic sequences embedded in video games and interactive media, serving as the primary vehicle for narrative delivery, character development, and emotional engagement. Producing cutscenes is inherently complex: it demands seamless coordination across screenwriting, cinematography, character animation, voice acting, and technical direction, often requiring days to weeks of collaborative effort from multidisciplinary teams to produce minutes of polished content. In this work, we present Cutscene Agent, an LLM agent framework for automated end-to-end cutscene generation. The framework makes three contributions: (1)~a Cutscene Toolkit built on the Model Context Protocol (MCP) that establishes \emph{bidirectional} integration between LLM agents and the game engine -- agents not only invoke engine operations but continuously observe real-time scene state, enabling closed-loop generation of editable engine-native cinematic assets; (2)~a multi-agent system where a director agent orchestrates specialist subagents for animation, cinematography, and sound design, augmented by a visual reasoning feedback loop for perception-driven refinement; and (3)~CutsceneBench, a hierarchical evaluation benchmark for cutscene generation. Unlike typical tool-use benchmarks that evaluate short, isolated function calls, cutscene generation requires long-horizon, multi-step orchestration of dozens of interdependent tool invocations with strict ordering constraints -- a capability dimension that existing benchmarks do not cover. We evaluate a range of LLMs on CutsceneBench and analyze their performance across this challenging task.
EOS-Bench: A Comprehensive Benchmark for Earth Observation Satellite Scheduling
Apr 28, 2026Earth observation satellite imaging scheduling is a challenging NP-hard combinatorial optimisation problem central to space mission operations. While next-generation agile Earth observation satellites (EOS) increase operational flexibility, they also significantly raise scheduling complexity. The lack of a unified, open-source benchmark makes it difficult to compare algorithms across studies. This paper introduces EOS-Bench, a comprehensive framework for systematic and reproducible evaluation of scheduling methods. By integrating high-fidelity orbital dynamics and platform constraints, EOS-Bench generates 1,390 scenarios and 13,900 benchmark instances, spanning from small-scale validation cases to large coordination problems with up to 1,000 satellites and 10,000 requests. We further propose a scenario characterisation scheme to quantify structural difficulty based on factors such as opportunity density, task flexibility, conflict intensity, and satellite congestion. A multidimensional evaluation protocol is introduced, assessing performance across five metrics: task profit, completion rate, workload balance, timeliness, and runtime. The framework is evaluated using mixed-integer programming, heuristics, meta-heuristics, and deep reinforcement learning across both agile and non-agile settings. Results show that EOS-Bench effectively distinguishes solver performance across scales and conditions, revealing trade-offs between solution quality and computational efficiency, and providing deeper insight into scenario complexity. EOS-Bench offers a unified and extensible open testbed for advancing research in Earth observation satellite scheduling. The code and data are available at https://github.com/Ethan19YQ/EOS-Bench.
Blind Bitstream-corrupted Video Recovery via Metadata-guided Diffusion Model
Apr 15, 2026Bitstream-corrupted video recovery aims to restore realistic content degraded during video storage or transmission. Existing methods typically assume that predefined masks of corrupted regions are available, but manually annotating these masks is labor-intensive and impractical in real-world scenarios. To address this limitation, we introduce a new blind video recovery setting that removes the reliance on predefined masks. This setting presents two major challenges: accurately identifying corrupted regions and recovering content from extensive and irregular degradations. We propose a Metadata-Guided Diffusion Model (M-GDM) to tackle these challenges. Specifically, intrinsic video metadata are leveraged as corruption indicators through a dual-stream metadata encoder that separately embeds motion vectors and frame types before fusing them into a unified representation. This representation interacts with corrupted latent features via cross-attention at each diffusion step. To preserve intact regions, we design a prior-driven mask predictor that generates pseudo masks using both metadata and diffusion priors, enabling the separation and recombination of intact and recovered regions through hard masking. To mitigate boundary artifacts caused by imperfect masks, a post-refinement module enhances consistency between intact and recovered regions. Extensive experiments demonstrate the effectiveness of our method and its superiority in blind video recovery. Code is available at: https://github.com/Shuyun-Wang/M-GDM.
Video-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs
Jan 14, 2026Spatial reasoning has emerged as a critical capability for Multimodal Large Language Models (MLLMs), drawing increasing attention and rapid advancement. However, existing benchmarks primarily focus on single-step perception-to-judgment tasks, leaving scenarios requiring complex visual-spatial logical chains significantly underexplored. To bridge this gap, we introduce Video-MSR, the first benchmark specifically designed to evaluate Multi-hop Spatial Reasoning (MSR) in dynamic video scenarios. Video-MSR systematically probes MSR capabilities through four distinct tasks: Constrained Localization, Chain-based Reference Retrieval, Route Planning, and Counterfactual Physical Deduction. Our benchmark comprises 3,052 high-quality video instances with 4,993 question-answer pairs, constructed via a scalable, visually-grounded pipeline combining advanced model generation with rigorous human verification. Through a comprehensive evaluation of 20 state-of-the-art MLLMs, we uncover significant limitations, revealing that while models demonstrate proficiency in surface-level perception, they exhibit distinct performance drops in MSR tasks, frequently suffering from spatial disorientation and hallucination during multi-step deductions. To mitigate these shortcomings and empower models with stronger MSR capabilities, we further curate MSR-9K, a specialized instruction-tuning dataset, and fine-tune Qwen-VL, achieving a +7.82% absolute improvement on Video-MSR. Our results underscore the efficacy of multi-hop spatial instruction data and establish Video-MSR as a vital foundation for future research. The code and data will be available at https://github.com/ruiz-nju/Video-MSR.
Few Tokens Matter: Entropy Guided Attacks on Vision-Language Models
Dec 26, 2025Vision-language models (VLMs) achieve remarkable performance but remain vulnerable to adversarial attacks. Entropy, a measure of model uncertainty, is strongly correlated with the reliability of VLM. Prior entropy-based attacks maximize uncertainty at all decoding steps, implicitly assuming that every token contributes equally to generation instability. We show instead that a small fraction (about 20%) of high-entropy tokens, i.e., critical decision points in autoregressive generation, disproportionately governs output trajectories. By concentrating adversarial perturbations on these positions, we achieve semantic degradation comparable to global methods while using substantially smaller budgets. More importantly, across multiple representative VLMs, such selective attacks convert 35-49% of benign outputs into harmful ones, exposing a more critical safety risk. Remarkably, these vulnerable high-entropy forks recur across architecturally diverse VLMs, enabling feasible transferability (17-26% harmful rates on unseen targets). Motivated by these findings, we propose Entropy-bank Guided Adversarial attacks (EGA), which achieves competitive attack success rates (93-95%) alongside high harmful conversion, thereby revealing new weaknesses in current VLM safety mechanisms.
Trust-Aware Diversion for Data-Effective Distillation
Feb 07, 2025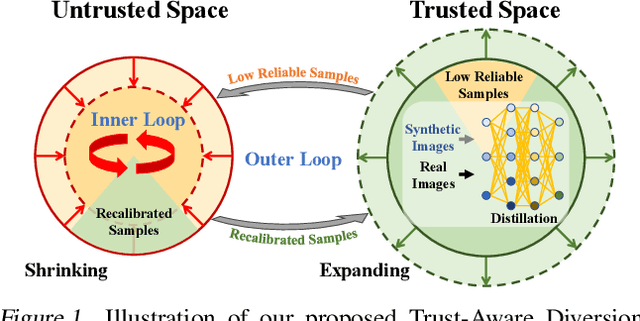
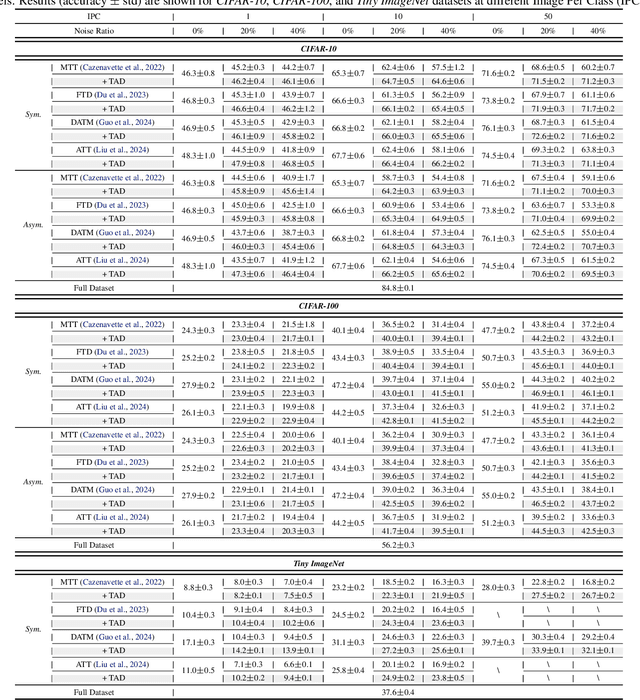
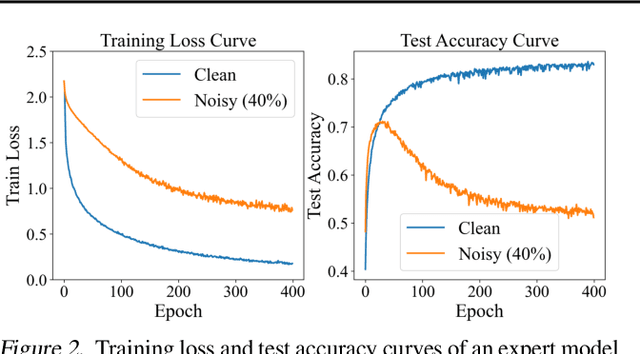
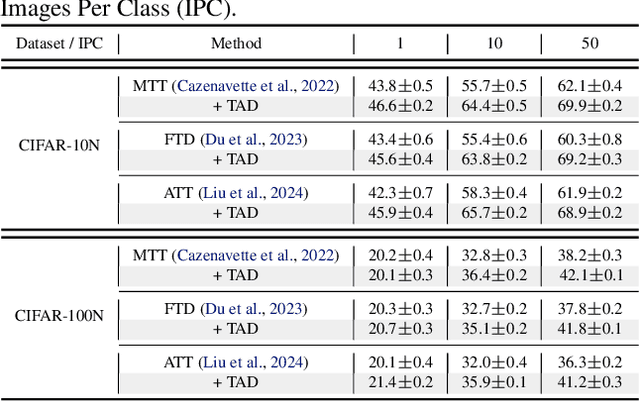
Dataset distillation compresses a large dataset into a small synthetic subset that retains essential information. Existing methods assume that all samples are perfectly labeled, limiting their real-world applications where incorrect labels are ubiquitous. These mislabeled samples introduce untrustworthy information into the dataset, which misleads model optimization in dataset distillation. To tackle this issue, we propose a Trust-Aware Diversion (TAD) dataset distillation method. Our proposed TAD introduces an iterative dual-loop optimization framework for data-effective distillation. Specifically, the outer loop divides data into trusted and untrusted spaces, redirecting distillation toward trusted samples to guarantee trust in the distillation process. This step minimizes the impact of mislabeled samples on dataset distillation. The inner loop maximizes the distillation objective by recalibrating untrusted samples, thus transforming them into valuable ones for distillation. This dual-loop iteratively refines and compensates for each other, gradually expanding the trusted space and shrinking the untrusted space. Experiments demonstrate that our method can significantly improve the performance of existing dataset distillation methods on three widely used benchmarks (CIFAR10, CIFAR100, and Tiny ImageNet) in three challenging mislabeled settings (symmetric, asymmetric, and real-world).
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.