 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWGSR-Bench: Wargame-based Game-theoretic Strategic Reasoning Benchmark for Large Language Models
Jun 12, 2025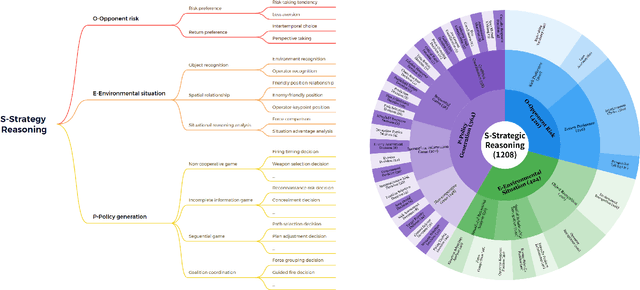
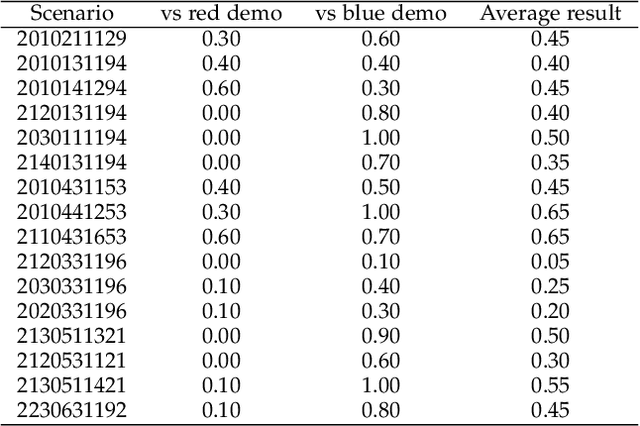
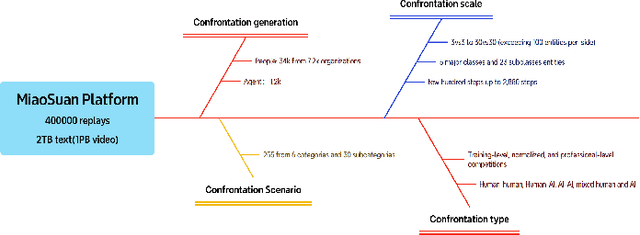
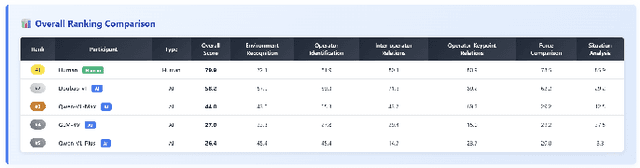
Recent breakthroughs in Large Language Models (LLMs) have led to a qualitative leap in artificial intelligence' s performance on reasoning tasks, particularly demonstrating remarkable capabilities in mathematical, symbolic, and commonsense reasoning. However, as a critical component of advanced human cognition, strategic reasoning, i.e., the ability to assess multi-agent behaviors in dynamic environments, formulate action plans, and adapt strategies, has yet to be systematically evaluated or modeled. To address this gap, this paper introduces WGSR-Bench, the first strategy reasoning benchmark for LLMs using wargame as its evaluation environment. Wargame, a quintessential high-complexity strategic scenario, integrates environmental uncertainty, adversarial dynamics, and non-unique strategic choices, making it an effective testbed for assessing LLMs' capabilities in multi-agent decision-making, intent inference, and counterfactual reasoning. WGSR-Bench designs test samples around three core tasks, i.e., Environmental situation awareness, Opponent risk modeling and Policy generation, which serve as the core S-POE architecture, to systematically assess main abilities of strategic reasoning. Finally, an LLM-based wargame agent is designed to integrate these parts for a comprehensive strategy reasoning assessment. With WGSR-Bench, we hope to assess the strengths and limitations of state-of-the-art LLMs in game-theoretic strategic reasoning and to advance research in large model-driven strategic intelligence.
Semantic Embedded Deep Neural Network: A Generic Approach to Boost Multi-Label Image Classification Performance
May 15, 2023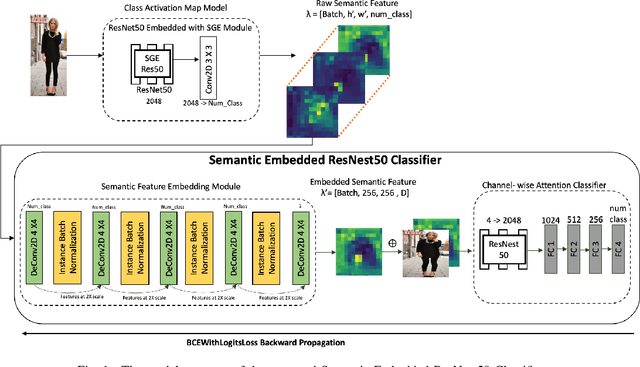
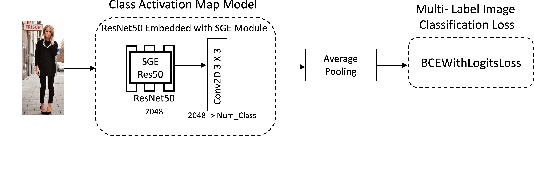

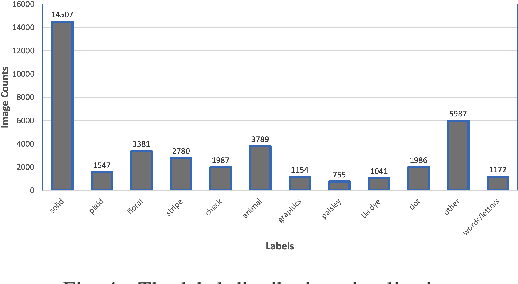
Fine-grained multi-label classification models have broad applications in Amazon production features, such as visual based label predictions ranging from fashion attribute detection to brand recognition. One challenge to achieve satisfactory performance for those classification tasks in real world is the wild visual background signal that contains irrelevant pixels which confuses model to focus onto the region of interest and make prediction upon the specific region. In this paper, we introduce a generic semantic-embedding deep neural network to apply the spatial awareness semantic feature incorporating a channel-wise attention based model to leverage the localization guidance to boost model performance for multi-label prediction. We observed an Avg.relative improvement of 15.27% in terms of AUC score across all labels compared to the baseline approach. Core experiment and ablation studies involve multi-label fashion attribute classification performed on Instagram fashion apparels' image. We compared the model performances among our approach, baseline approach, and 3 alternative approaches to leverage semantic features. Results show favorable performance for our approach.
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022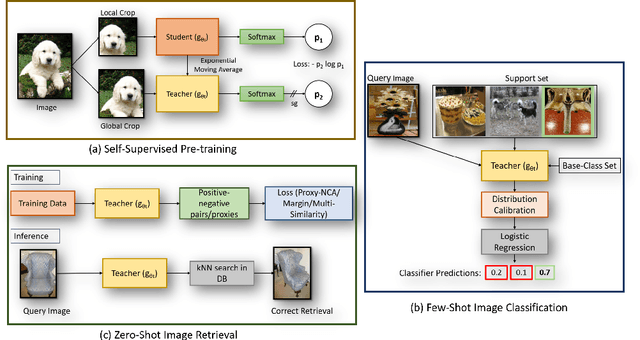
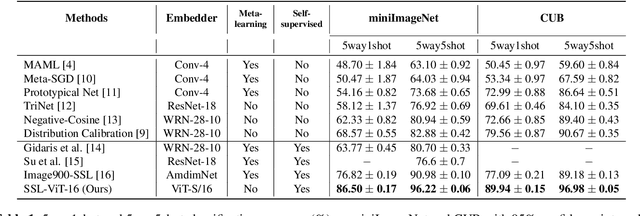
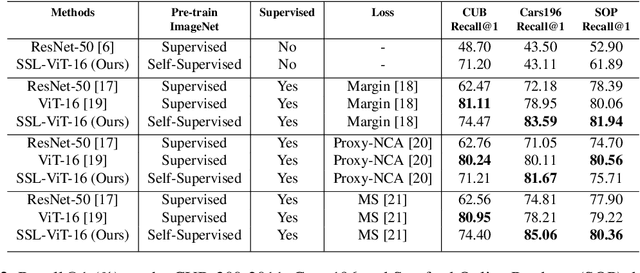

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
A weakly supervised adaptive triplet loss for deep metric learning
Sep 27, 2019
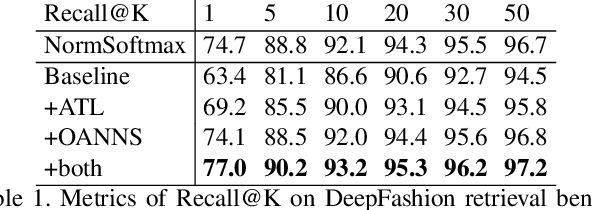
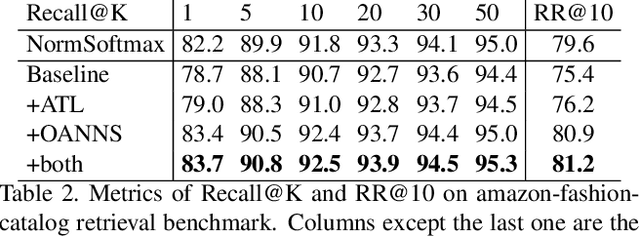
We address the problem of distance metric learning in visual similarity search, defined as learning an image embedding model which projects images into Euclidean space where semantically and visually similar images are closer and dissimilar images are further from one another. We present a weakly supervised adaptive triplet loss (ATL) capable of capturing fine-grained semantic similarity that encourages the learned image embedding models to generalize well on cross-domain data. The method uses weakly labeled product description data to implicitly determine fine grained semantic classes, avoiding the need to annotate large amounts of training data. We evaluate on the Amazon fashion retrieval benchmark and DeepFashion in-shop retrieval data. The method boosts the performance of triplet loss baseline by 10.6% on cross-domain data and out-performs the state-of-art model on all evaluation metrics.