 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Trade-off: A Synthesis of Defensive Strategies for Zero-Shot Adversarial Robustness in Vision-Language Models
Aug 07, 2025This report synthesizes eight seminal papers on the zero-shot adversarial robustness of vision-language models (VLMs) like CLIP. A central challenge in this domain is the inherent trade-off between enhancing adversarial robustness and preserving the model's zero-shot generalization capabilities. We analyze two primary defense paradigms: Adversarial Fine-Tuning (AFT), which modifies model parameters, and Training-Free/Test-Time Defenses, which preserve them. We trace the evolution from alignment-preserving methods (TeCoA) to embedding space re-engineering (LAAT, TIMA), and from input heuristics (AOM, TTC) to latent-space purification (CLIPure). Finally, we identify key challenges and future directions including hybrid defense strategies and adversarial pre-training.
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022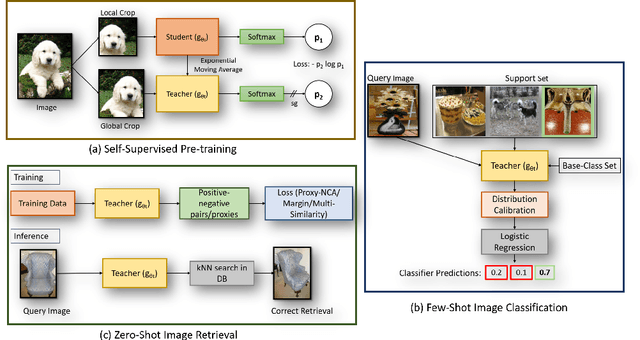
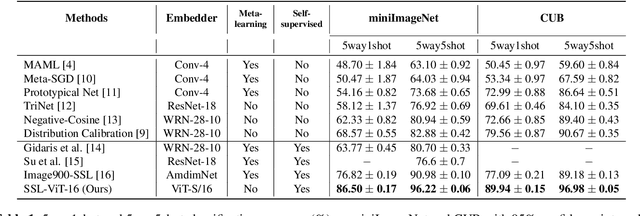
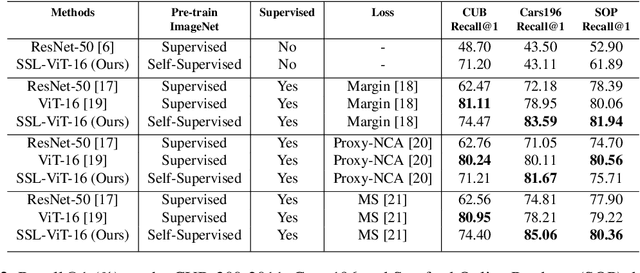

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
A neural interlingua for multilingual machine translation
Oct 16, 2018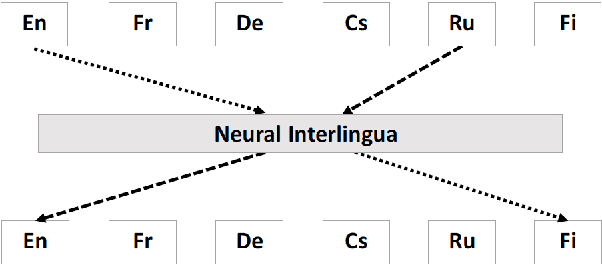
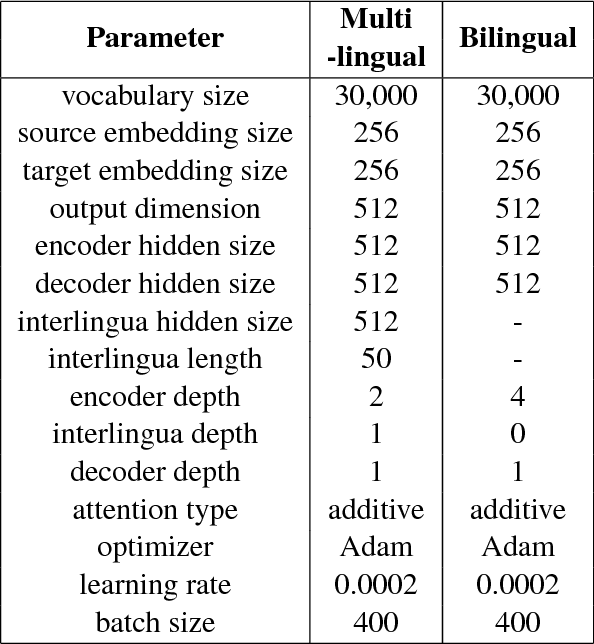
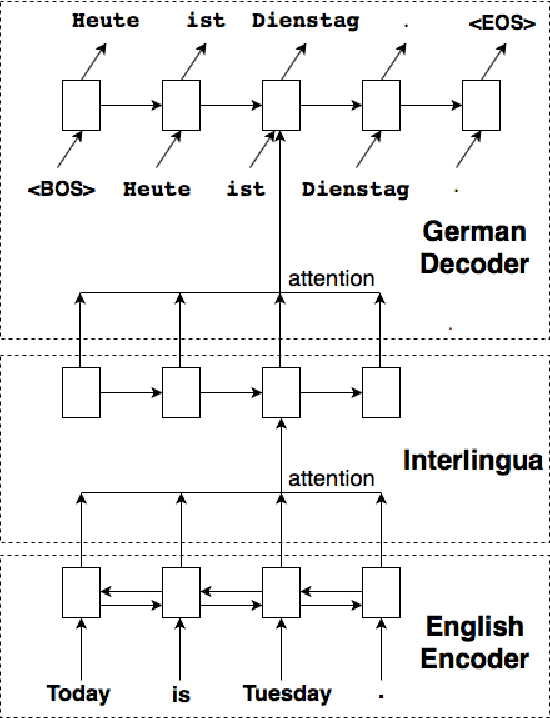
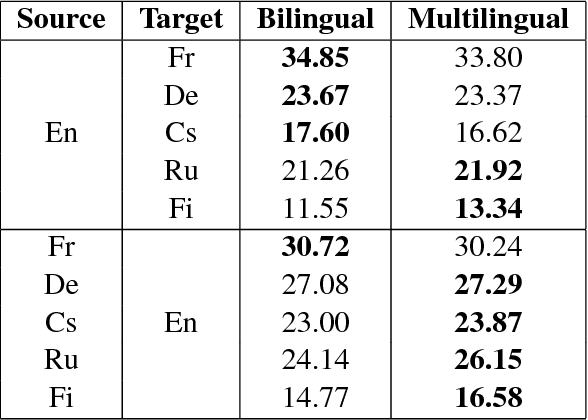
We incorporate an explicit neural interlingua into a multilingual encoder-decoder neural machine translation (NMT) architecture. We demonstrate that our model learns a language-independent representation by performing direct zero-shot translation (without using pivot translation), and by using the source sentence embeddings to create an English Yelp review classifier that, through the mediation of the neural interlingua, can also classify French and German reviews. Furthermore, we show that, despite using a smaller number of parameters than a pairwise collection of bilingual NMT models, our approach produces comparable BLEU scores for each language pair in WMT15.
A practical approach to dialogue response generation in closed domains
Mar 28, 2017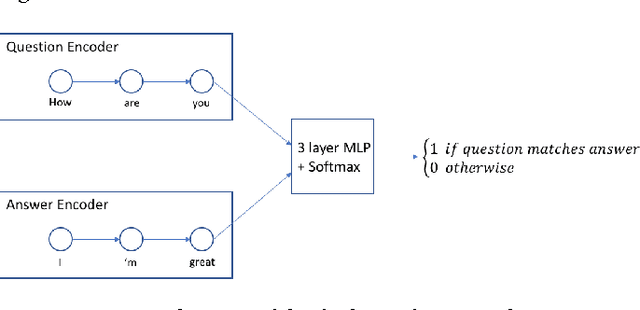


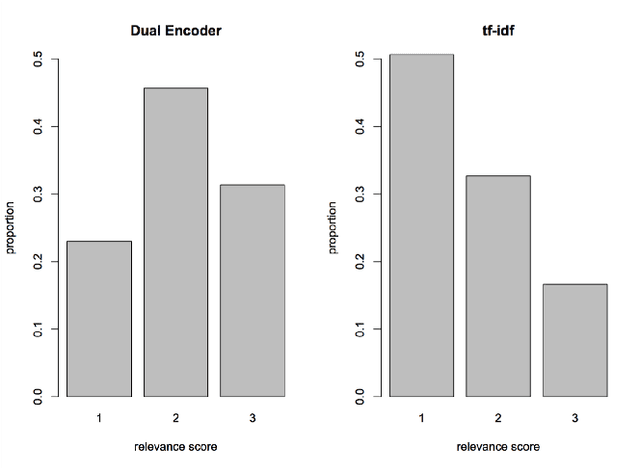
We describe a prototype dialogue response generation model for the customer service domain at Amazon. The model, which is trained in a weakly supervised fashion, measures the similarity between customer questions and agent answers using a dual encoder network, a Siamese-like neural network architecture. Answer templates are extracted from embeddings derived from past agent answers, without turn-by-turn annotations. Responses to customer inquiries are generated by selecting the best template from the final set of templates. We show that, in a closed domain like customer service, the selected templates cover $>$70\% of past customer inquiries. Furthermore, the relevance of the model-selected templates is significantly higher than templates selected by a standard tf-idf baseline.