 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
SWAN-GPT: An Efficient and Scalable Approach for Long-Context Language Modeling
Apr 11, 2025We present a decoder-only Transformer architecture that robustly generalizes to sequence lengths substantially longer than those seen during training. Our model, SWAN-GPT, interleaves layers without positional encodings (NoPE) and sliding-window attention layers equipped with rotary positional encodings (SWA-RoPE). Experiments demonstrate strong performance on sequence lengths significantly longer than the training length without the need for additional long-context training. This robust length extrapolation is achieved through our novel architecture, enhanced by a straightforward dynamic scaling of attention scores during inference. In addition, SWAN-GPT is more computationally efficient than standard GPT architectures, resulting in cheaper training and higher throughput. Further, we demonstrate that existing pre-trained decoder-only models can be efficiently converted to the SWAN architecture with minimal continued training, enabling longer contexts. Overall, our work presents an effective approach for scaling language models to longer contexts in a robust and efficient manner.
L0-Reasoning Bench: Evaluating Procedural Correctness in Language Models via Simple Program Execution
Mar 28, 2025Complex reasoning tasks often rely on the ability to consistently and accurately apply simple rules across incremental steps, a foundational capability which we term "level-0" reasoning. To systematically evaluate this capability, we introduce L0-Bench, a language model benchmark for testing procedural correctness -- the ability to generate correct reasoning processes, complementing existing benchmarks that primarily focus on outcome correctness. Given synthetic Python functions with simple operations, L0-Bench grades models on their ability to generate step-by-step, error-free execution traces. The synthetic nature of L0-Bench enables systematic and scalable generation of test programs along various axes (e.g., number of trace steps). We evaluate a diverse array of recent closed-source and open-weight models on a baseline test set. All models exhibit degradation as the number of target trace steps increases, while larger models and reasoning-enhanced models better maintain correctness over multiple steps. Additionally, we use L0-Bench to explore test-time scaling along three dimensions: input context length, number of solutions for majority voting, and inference steps. Our results suggest substantial room to improve "level-0" reasoning and potential directions to build more reliable reasoning systems.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
Incorporating Human Explanations for Robust Hate Speech Detection
Nov 09, 2024
Given the black-box nature and complexity of large transformer language models (LM), concerns about generalizability and robustness present ethical implications for domains such as hate speech (HS) detection. Using the content rich Social Bias Frames dataset, containing human-annotated stereotypes, intent, and targeted groups, we develop a three stage analysis to evaluate if LMs faithfully assess hate speech. First, we observe the need for modeling contextually grounded stereotype intents to capture implicit semantic meaning. Next, we design a new task, Stereotype Intent Entailment (SIE), which encourages a model to contextually understand stereotype presence. Finally, through ablation tests and user studies, we find a SIE objective improves content understanding, but challenges remain in modeling implicit intent.
STORYSUMM: Evaluating Faithfulness in Story Summarization
Jul 09, 2024
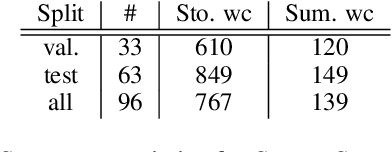
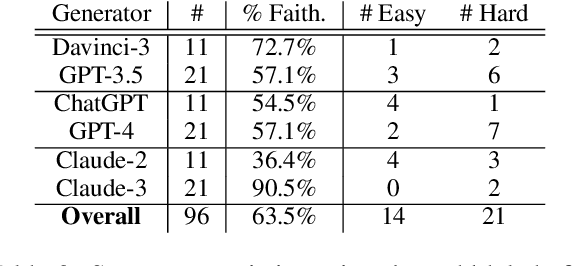

Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, STORYSUMM, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Aligning Large Language Models via Fine-grained Supervision
Jun 04, 2024



Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1\%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
Proving Test Set Contamination in Black Box Language Models
Oct 26, 2023Large language models are trained on vast amounts of internet data, prompting concerns and speculation that they have memorized public benchmarks. Going from speculation to proof of contamination is challenging, as the pretraining data used by proprietary models are often not publicly accessible. We show that it is possible to provide provable guarantees of test set contamination in language models without access to pretraining data or model weights. Our approach leverages the fact that when there is no data contamination, all orderings of an exchangeable benchmark should be equally likely. In contrast, the tendency for language models to memorize example order means that a contaminated language model will find certain canonical orderings to be much more likely than others. Our test flags potential contamination whenever the likelihood of a canonically ordered benchmark dataset is significantly higher than the likelihood after shuffling the examples. We demonstrate that our procedure is sensitive enough to reliably prove test set contamination in challenging situations, including models as small as 1.4 billion parameters, on small test sets of only 1000 examples, and datasets that appear only a few times in the pretraining corpus. Using our test, we audit five popular publicly accessible language models for test set contamination and find little evidence for pervasive contamination.
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Sep 08, 2023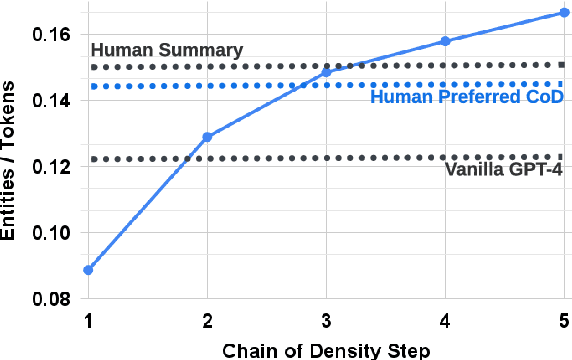



Selecting the ``right'' amount of information to include in a summary is a difficult task. A good summary should be detailed and entity-centric without being overly dense and hard to follow. To better understand this tradeoff, we solicit increasingly dense GPT-4 summaries with what we refer to as a ``Chain of Density'' (CoD) prompt. Specifically, GPT-4 generates an initial entity-sparse summary before iteratively incorporating missing salient entities without increasing the length. Summaries generated by CoD are more abstractive, exhibit more fusion, and have less of a lead bias than GPT-4 summaries generated by a vanilla prompt. We conduct a human preference study on 100 CNN DailyMail articles and find that that humans prefer GPT-4 summaries that are more dense than those generated by a vanilla prompt and almost as dense as human written summaries. Qualitative analysis supports the notion that there exists a tradeoff between informativeness and readability. 500 annotated CoD summaries, as well as an extra 5,000 unannotated summaries, are freely available on HuggingFace (https://huggingface.co/datasets/griffin/chain_of_density).