 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferences Improve LLM Alignment in Non-Verifiable Domains
Feb 18, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) has shown strong effectiveness in reasoning tasks, it cannot be directly applied to non-verifiable domains lacking ground-truth verifiers, such as LLM alignment. In this work, we investigate whether reference-guided LLM-evaluators can bridge this gap by serving as soft "verifiers". First, we design evaluation protocols that enhance LLM-based evaluators for LLM alignment using reference outputs. Through comprehensive experiments, we show that a reference-guided approach substantially improves the accuracy of less capable LLM-judges using references from frontier models; stronger LLM-judges can also be enhanced by high-quality (i.e., human-written) references. Building on these improved judges, we demonstrate the utility of high-quality references in alignment tuning, where LLMs guided with references are used as judges to self-improve. We show that reference-guided self-improvement yields clear gains over both direct SFT on reference outputs and self-improvement with reference-free judges, achieving performance comparable to training with ArmoRM, a strong finetuned reward model. Specifically, our method achieves 73.1% and 58.7% on AlpacaEval and Arena-Hard with Llama-3-8B-Instruct, and 70.0% and 74.1% with Qwen2.5-7B, corresponding to average absolute gains of +20.2 / +17.1 points over SFT distillation and +5.3 / +3.6 points over reference-free self-improvement on AlpacaEval / Arena-Hard. These results highlight the potential of using reference-guided LLM-evaluators to enable effective LLM post-training in non-verifiable domains.
MultiNRC: A Challenging and Native Multilingual Reasoning Evaluation Benchmark for LLMs
Jul 23, 2025


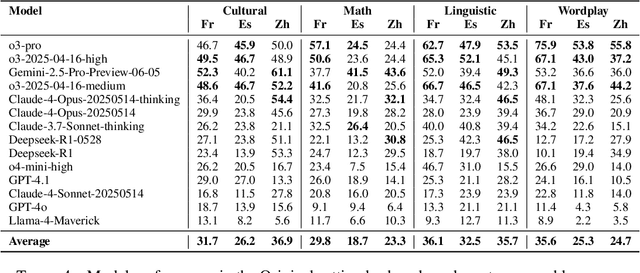
Although recent Large Language Models (LLMs) have shown rapid improvement on reasoning benchmarks in English, the evaluation of such LLMs' multilingual reasoning capability across diverse languages and cultural contexts remains limited. Existing multilingual reasoning benchmarks are typically constructed by translating existing English reasoning benchmarks, biasing these benchmarks towards reasoning problems with context in English language/cultures. In this work, we introduce the Multilingual Native Reasoning Challenge (MultiNRC), a benchmark designed to assess LLMs on more than 1,000 native, linguistic and culturally grounded reasoning questions written by native speakers in French, Spanish, and Chinese. MultiNRC covers four core reasoning categories: language-specific linguistic reasoning, wordplay & riddles, cultural/tradition reasoning, and math reasoning with cultural relevance. For cultural/tradition reasoning and math reasoning with cultural relevance, we also provide English equivalent translations of the multilingual questions by manual translation from native speakers fluent in English. This set of English equivalents can provide a direct comparison of LLM reasoning capacity in other languages vs. English on the same reasoning questions. We systematically evaluate current 14 leading LLMs covering most LLM families on MultiNRC and its English equivalent set. The results show that (1) current LLMs are still not good at native multilingual reasoning, with none scoring above 50% on MultiNRC; (2) LLMs exhibit distinct strengths and weaknesses in handling linguistic, cultural, and logical reasoning tasks; (3) Most models perform substantially better in math reasoning in English compared to in original languages (+10%), indicating persistent challenges with culturally grounded knowledge.
Evaluating Cultural and Social Awareness of LLM Web Agents
Oct 30, 2024As large language models (LLMs) expand into performing as agents for real-world applications beyond traditional NLP tasks, evaluating their robustness becomes increasingly important. However, existing benchmarks often overlook critical dimensions like cultural and social awareness. To address these, we introduce CASA, a benchmark designed to assess LLM agents' sensitivity to cultural and social norms across two web-based tasks: online shopping and social discussion forums. Our approach evaluates LLM agents' ability to detect and appropriately respond to norm-violating user queries and observations. Furthermore, we propose a comprehensive evaluation framework that measures awareness coverage, helpfulness in managing user queries, and the violation rate when facing misleading web content. Experiments show that current LLMs perform significantly better in non-agent than in web-based agent environments, with agents achieving less than 10% awareness coverage and over 40% violation rates. To improve performance, we explore two methods: prompting and fine-tuning, and find that combining both methods can offer complementary advantages -- fine-tuning on culture-specific datasets significantly enhances the agents' ability to generalize across different regions, while prompting boosts the agents' ability to navigate complex tasks. These findings highlight the importance of constantly benchmarking LLM agents' cultural and social awareness during the development cycle.
ReIFE: Re-evaluating Instruction-Following Evaluation
Oct 09, 2024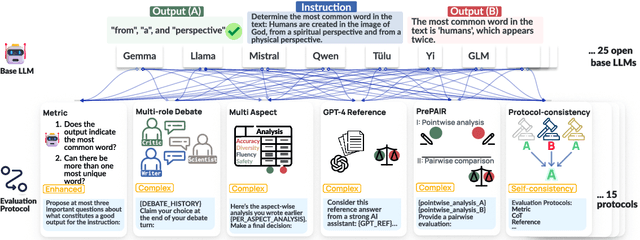
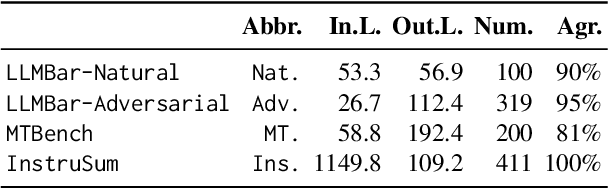
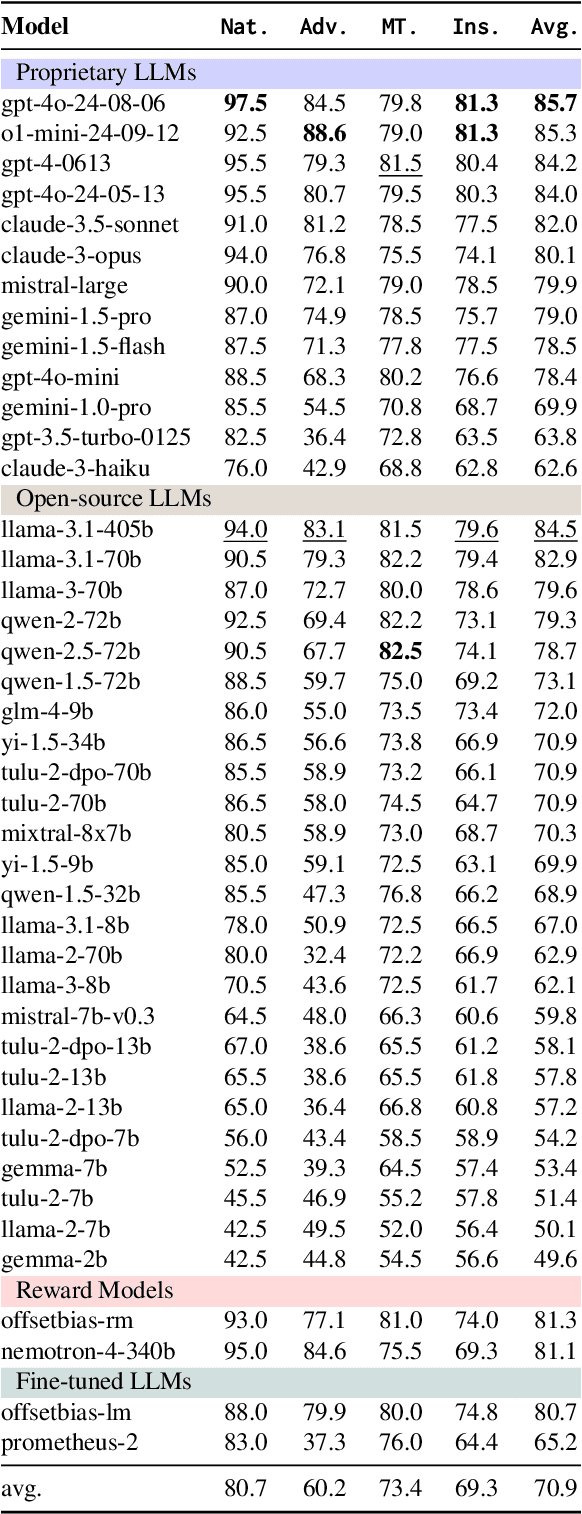
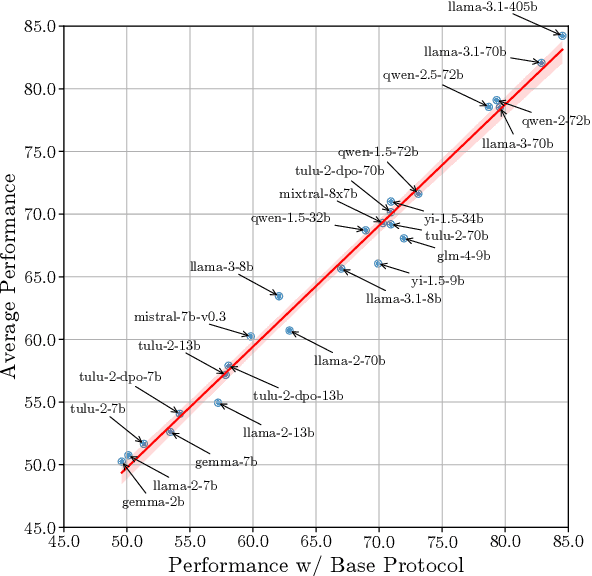
The automatic evaluation of instruction following typically involves using large language models (LLMs) to assess response quality. However, there is a lack of comprehensive evaluation of these LLM-based evaluators across two dimensions: the base LLMs and the evaluation protocols. Therefore, we present a thorough meta-evaluation of instruction following, including 25 base LLMs and 15 recently proposed evaluation protocols, on 4 human-annotated datasets, assessing the evaluation accuracy of the LLM-evaluators. Our evaluation allows us to identify the best-performing base LLMs and evaluation protocols with a high degree of robustness. Moreover, our large-scale evaluation reveals: (1) Base LLM performance ranking remains largely consistent across evaluation protocols, with less capable LLMs showing greater improvement from protocol enhancements; (2) Robust evaluation of evaluation protocols requires many base LLMs with varying capability levels, as protocol effectiveness can depend on the base LLM used; (3) Evaluation results on different datasets are not always consistent, so a rigorous evaluation requires multiple datasets with distinctive features. We release our meta-evaluation suite ReIFE, which provides the codebase and evaluation result collection for more than 500 LLM-evaluator configurations, to support future research in instruction-following evaluation.
Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
Jul 01, 2024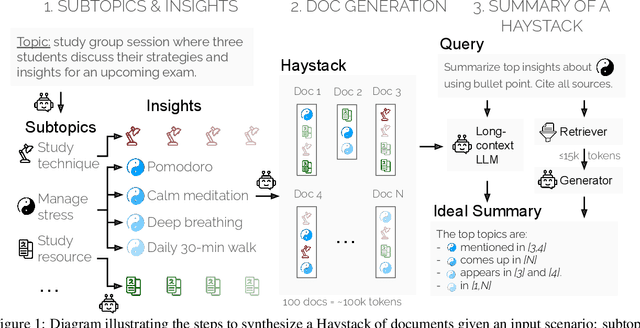
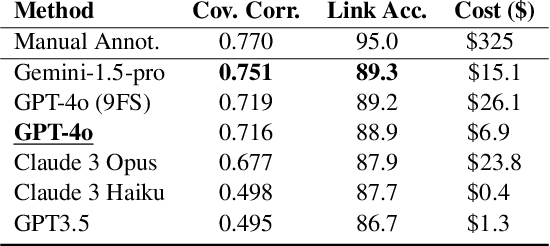


LLMs and RAG systems are now capable of handling millions of input tokens or more. However, evaluating the output quality of such systems on long-context tasks remains challenging, as tasks like Needle-in-a-Haystack lack complexity. In this work, we argue that summarization can play a central role in such evaluation. We design a procedure to synthesize Haystacks of documents, ensuring that specific \textit{insights} repeat across documents. The "Summary of a Haystack" (SummHay) task then requires a system to process the Haystack and generate, given a query, a summary that identifies the relevant insights and precisely cites the source documents. Since we have precise knowledge of what insights should appear in a haystack summary and what documents should be cited, we implement a highly reproducible automatic evaluation that can score summaries on two aspects - Coverage and Citation. We generate Haystacks in two domains (conversation, news), and perform a large-scale evaluation of 10 LLMs and corresponding 50 RAG systems. Our findings indicate that SummHay is an open challenge for current systems, as even systems provided with an Oracle signal of document relevance lag our estimate of human performance (56\%) by 10+ points on a Joint Score. Without a retriever, long-context LLMs like GPT-4o and Claude 3 Opus score below 20% on SummHay. We show SummHay can also be used to study enterprise RAG systems and position bias in long-context models. We hope future systems can equal and surpass human performance on SummHay.
Investigating the prompt leakage effect and black-box defenses for multi-turn LLM interactions
Apr 26, 2024



Prompt leakage in large language models (LLMs) poses a significant security and privacy threat, particularly in retrieval-augmented generation (RAG) systems. However, leakage in multi-turn LLM interactions along with mitigation strategies has not been studied in a standardized manner. This paper investigates LLM vulnerabilities against prompt leakage across 4 diverse domains and 10 closed- and open-source LLMs. Our unique multi-turn threat model leverages the LLM's sycophancy effect and our analysis dissects task instruction and knowledge leakage in the LLM response. In a multi-turn setting, our threat model elevates the average attack success rate (ASR) to 86.2%, including a 99% leakage with GPT-4 and claude-1.3. We find that some black-box LLMs like Gemini show variable susceptibility to leakage across domains - they are more likely to leak contextual knowledge in the news domain compared to the medical domain. Our experiments measure specific effects of 6 black-box defense strategies, including a query-rewriter in the RAG scenario. Our proposed multi-tier combination of defenses still has an ASR of 5.3% for black-box LLMs, indicating room for enhancement and future direction for LLM security research.
Lexical Repetitions Lead to Rote Learning: Unveiling the Impact of Lexical Overlap in Train and Test Reference Summaries
Nov 15, 2023
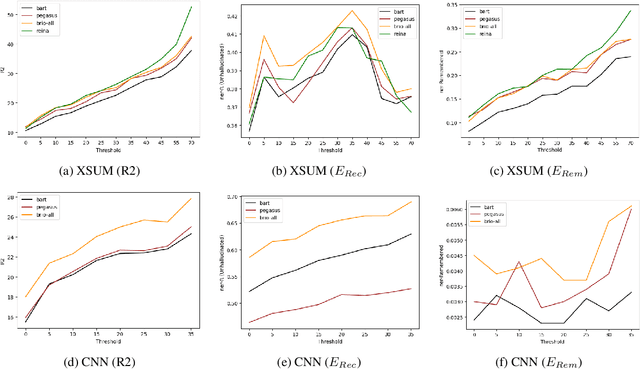
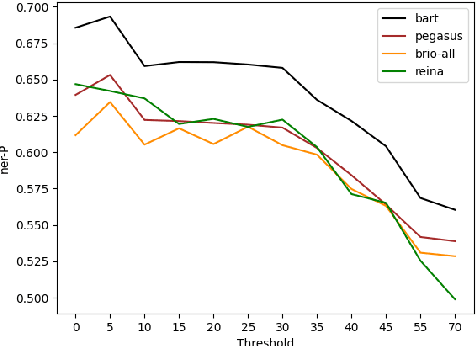
Ideal summarization models should generalize to novel summary-worthy content without remembering reference training summaries by rote. However, a single average performance score on the entire test set is inadequate in determining such model competencies. We propose a fine-grained evaluation protocol by partitioning a test set based on the lexical similarity of reference test summaries with training summaries. We observe up to a 5x (1.2x) difference in ROUGE-2 (entity recall) scores between the subsets with the lowest and highest similarity. Next, we show that such training repetitions also make a model vulnerable to rote learning, reproducing data artifacts such as factual errors, especially when reference test summaries are lexically close to training summaries. Consequently, we propose to limit lexical repetitions in training summaries during both supervised fine-tuning and likelihood calibration stages to improve the performance on novel test cases while retaining average performance. Our automatic and human evaluations on novel test subsets and recent news articles show that limiting lexical repetitions in training summaries can prevent rote learning and improve generalization.
Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization
Nov 15, 2023While large language models (LLMs) already achieve strong performance on standard generic summarization benchmarks, their performance on more complex summarization task settings is less studied. Therefore, we benchmark LLMs on instruction controllable text summarization, where the model input consists of both a source article and a natural language requirement for the desired summary characteristics. To this end, we curate an evaluation-only dataset for this task setting and conduct human evaluation on 5 LLM-based summarization systems. We then benchmark LLM-based automatic evaluation for this task with 4 different evaluation protocols and 11 LLMs, resulting in 40 evaluation methods in total. Our study reveals that instruction controllable text summarization remains a challenging task for LLMs, since (1) all LLMs evaluated still make factual and other types of errors in their summaries; (2) all LLM-based evaluation methods cannot achieve a strong alignment with human annotators when judging the quality of candidate summaries; (3) different LLMs show large performance gaps in summary generation and evaluation. We make our collected benchmark, InstruSum, publicly available to facilitate future research in this direction.
Embrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles
Sep 17, 2023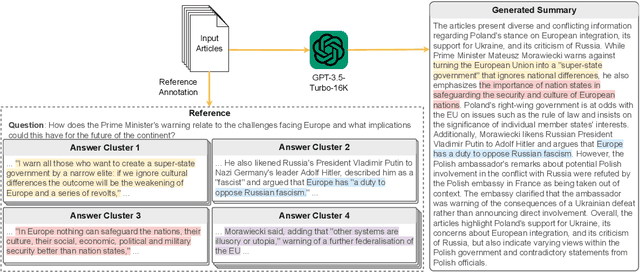



Previous research in multi-document news summarization has typically concentrated on collating information that all sources agree upon. However, to our knowledge, the summarization of diverse information dispersed across multiple articles about an event has not been previously investigated. The latter imposes a different set of challenges for a summarization model. In this paper, we propose a new task of summarizing diverse information encountered in multiple news articles encompassing the same event. To facilitate this task, we outlined a data collection schema for identifying diverse information and curated a dataset named DiverseSumm. The dataset includes 245 news stories, with each story comprising 10 news articles and paired with a human-validated reference. Moreover, we conducted a comprehensive analysis to pinpoint the position and verbosity biases when utilizing Large Language Model (LLM)-based metrics for evaluating the coverage and faithfulness of the summaries, as well as their correlation with human assessments. We applied our findings to study how LLMs summarize multiple news articles by analyzing which type of diverse information LLMs are capable of identifying. Our analyses suggest that despite the extraordinary capabilities of LLMs in single-document summarization, the proposed task remains a complex challenge for them mainly due to their limited coverage, with GPT-4 only able to cover less than 40% of the diverse information on average.
Generating EDU Extracts for Plan-Guided Summary Re-Ranking
May 28, 2023
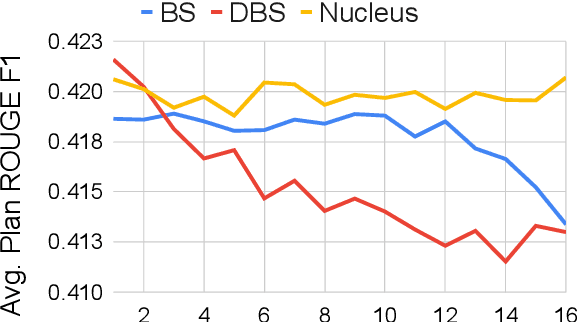
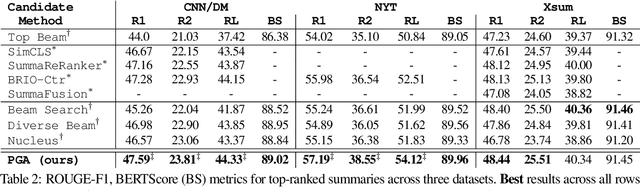
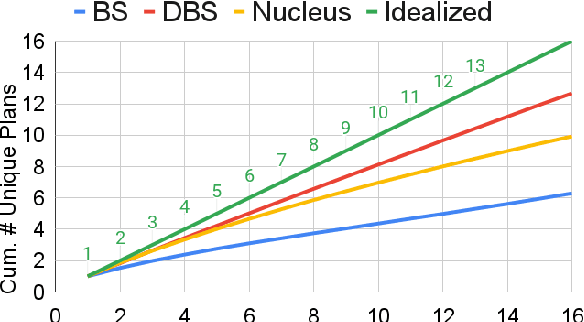
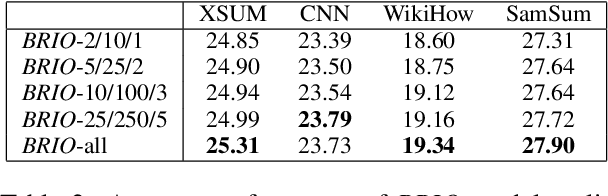
Two-step approaches, in which summary candidates are generated-then-reranked to return a single summary, can improve ROUGE scores over the standard single-step approach. Yet, standard decoding methods (i.e., beam search, nucleus sampling, and diverse beam search) produce candidates with redundant, and often low quality, content. In this paper, we design a novel method to generate candidates for re-ranking that addresses these issues. We ground each candidate abstract on its own unique content plan and generate distinct plan-guided abstracts using a model's top beam. More concretely, a standard language model (a BART LM) auto-regressively generates elemental discourse unit (EDU) content plans with an extractive copy mechanism. The top K beams from the content plan generator are then used to guide a separate LM, which produces a single abstractive candidate for each distinct plan. We apply an existing re-ranker (BRIO) to abstractive candidates generated from our method, as well as baseline decoding methods. We show large relevance improvements over previously published methods on widely used single document news article corpora, with ROUGE-2 F1 gains of 0.88, 2.01, and 0.38 on CNN / Dailymail, NYT, and Xsum, respectively. A human evaluation on CNN / DM validates these results. Similarly, on 1k samples from CNN / DM, we show that prompting GPT-3 to follow EDU plans outperforms sampling-based methods by 1.05 ROUGE-2 F1 points. Code to generate and realize plans is available at https://github.com/griff4692/edu-sum.