 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond
May 23, 2023



With the recent appearance of LLMs in practical settings, having methods that can effectively detect factual inconsistencies is crucial to reduce the propagation of misinformation and improve trust in model outputs. When testing on existing factual consistency benchmarks, we find that a few large language models (LLMs) perform competitively on classification benchmarks for factual inconsistency detection compared to traditional non-LLM methods. However, a closer analysis reveals that most LLMs fail on more complex formulations of the task and exposes issues with existing evaluation benchmarks, affecting evaluation precision. To address this, we propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as we estimate inter-annotator agreement at about 0.9. Most LLMs struggle on SummEdits, with performance close to random chance. The best-performing model, GPT-4, is still 8\% below estimated human performance, highlighting the gaps in LLMs' ability to reason about facts and detect inconsistencies when they occur.
Socratic Pretraining: Question-Driven Pretraining for Controllable Summarization
Dec 20, 2022In long document controllable summarization, where labeled data is scarce, pretrained models struggle to adapt to the task and effectively respond to user queries. In this paper, we introduce Socratic pretraining, a question-driven, unsupervised pretraining objective specifically designed to improve controllability in summarization tasks. By training a model to generate and answer relevant questions in a given context, Socratic pretraining enables the model to more effectively adhere to user-provided queries and identify relevant content to be summarized. We demonstrate the effectiveness of this approach through extensive experimentation on two summarization domains, short stories and dialogue, and multiple control strategies: keywords, questions, and factoid QA pairs. Our pretraining method relies only on unlabeled documents and a question generation system and outperforms pre-finetuning approaches that use additional supervised data. Furthermore, our results show that Socratic pretraining cuts task-specific labeled data requirements in half, is more faithful to user-provided queries, and achieves state-of-the-art performance on QMSum and SQuALITY.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022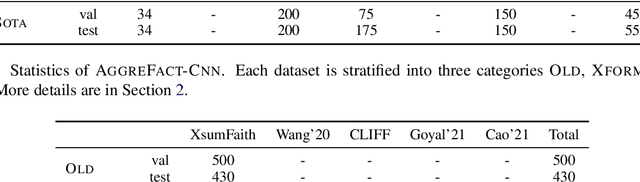
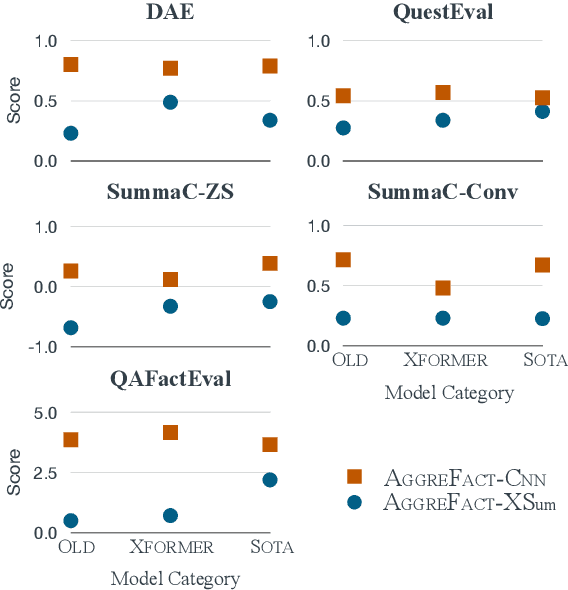
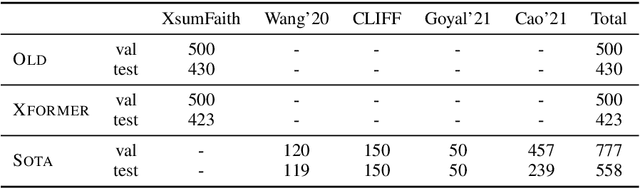
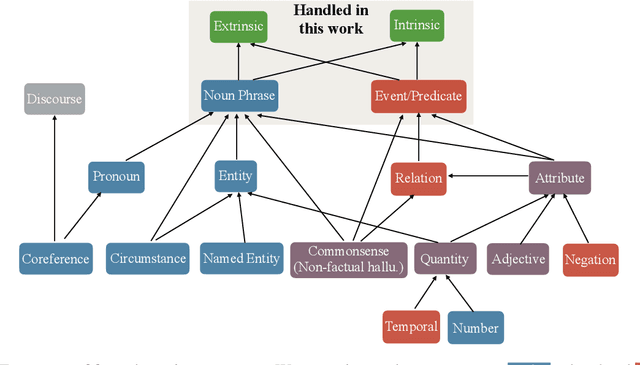
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.
Long Document Summarization with Top-down and Bottom-up Inference
Mar 15, 2022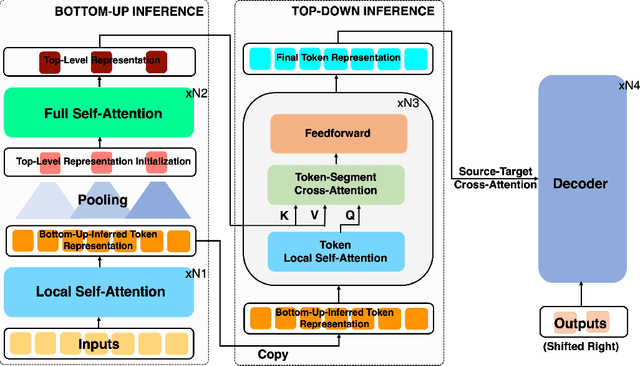
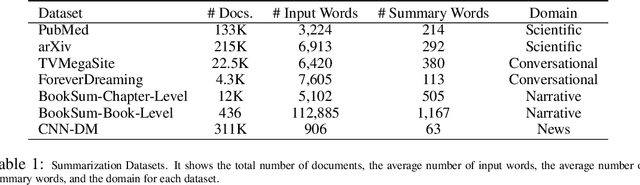
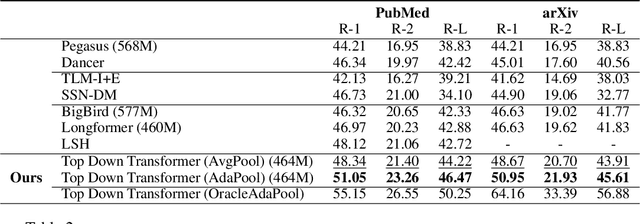

Text summarization aims to condense long documents and retain key information. Critical to the success of a summarization model is the faithful inference of latent representations of words or tokens in the source documents. Most recent models infer the latent representations with a transformer encoder, which is purely bottom-up. Also, self-attention-based inference models face the challenge of quadratic complexity with respect to sequence length. We propose a principled inference framework to improve summarization models on these two aspects. Our framework assumes a hierarchical latent structure of a document where the top-level captures the long range dependency at a coarser time scale and the bottom token level preserves the details. Critically, this hierarchical structure enables token representations to be updated in both a bottom-up and top-down manner. In the bottom-up pass, token representations are inferred with local self-attention to leverage its efficiency. Top-down correction is then applied to allow tokens to capture long-range dependency. We demonstrate the effectiveness of the proposed framework on a diverse set of summarization datasets, including narrative, conversational, scientific documents and news. Our model achieves (1) competitive or better performance on short documents with higher memory and compute efficiency, compared to full attention transformers, and (2) state-of-the-art performance on a wide range of long document summarization benchmarks, compared to recent efficient transformers. We also show that our model can summarize an entire book and achieve competitive performance using $0.27\%$ parameters (464M vs. 175B) and much less training data, compared to a recent GPT-3-based model. These results indicate the general applicability and benefits of the proposed framework.
Exploring Neural Models for Query-Focused Summarization
Dec 15, 2021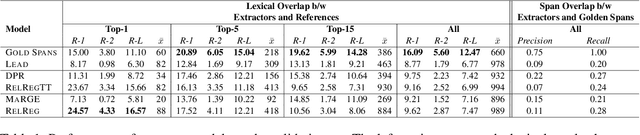
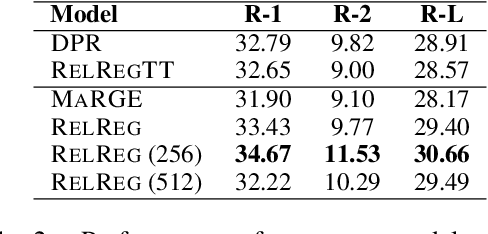
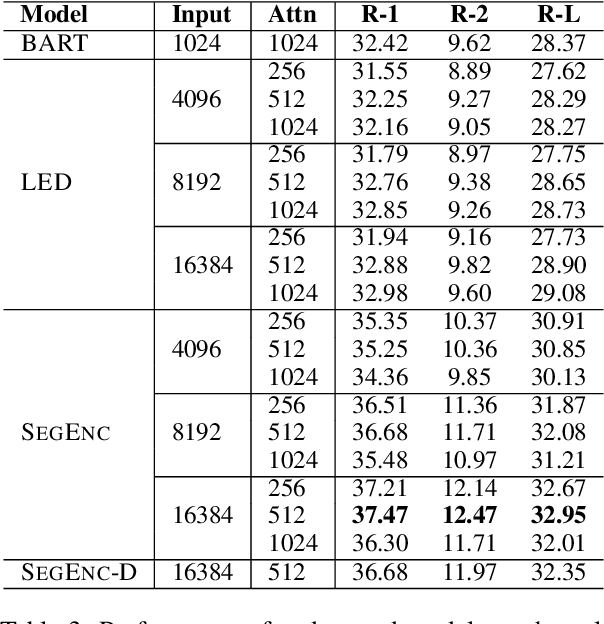
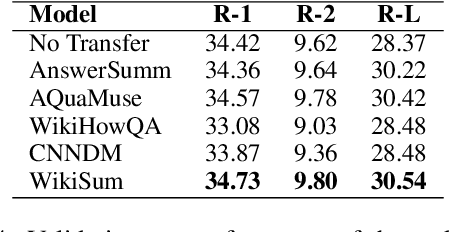
Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. While recently released datasets, such as QMSum or AQuaMuSe, facilitate research efforts in QFS, the field lacks a comprehensive study of the broad space of applicable modeling methods. In this paper we conduct a systematic exploration of neural approaches to QFS, considering two general classes of methods: two-stage extractive-abstractive solutions and end-to-end models. Within those categories, we investigate existing methods and present two model extensions that achieve state-of-the-art performance on the QMSum dataset by a margin of up to 3.38 ROUGE-1, 3.72 ROUGE-2, and 3.28 ROUGE-L. Through quantitative experiments we highlight the trade-offs between different model configurations and explore the transfer abilities between summarization tasks. Code and checkpoints are made publicly available: https://github.com/salesforce/query-focused-sum.
HydraSum: Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models
Nov 03, 2021
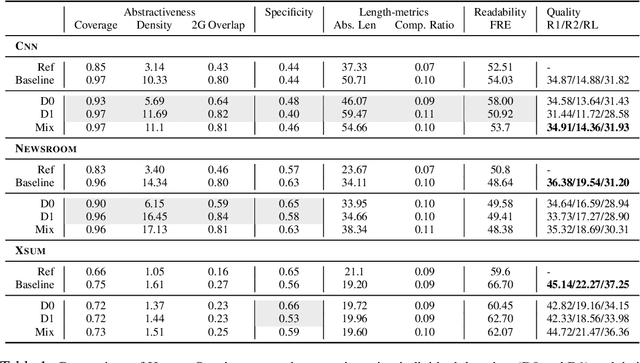
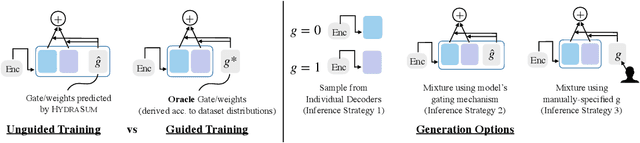

Existing abstractive summarization models lack explicit control mechanisms that would allow users to influence the stylistic features of the model outputs. This results in generating generic summaries that do not cater to the users needs or preferences. To address this issue we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models, e.g. BART, to a mixture-of-experts version consisting of multiple decoders. Our proposed model encourages each expert, i.e. decoder, to learn and generate stylistically-distinct summaries along dimensions such as abstractiveness, length, specificity, and others. At each time step, HydraSum employs a gating mechanism that decides the contribution of each individual decoder to the next token's output probability distribution. Through experiments on three summarization datasets (CNN, Newsroom, XSum), we demonstrate that this gating mechanism automatically learns to assign contrasting summary styles to different HydraSum decoders under the standard training objective without the need for additional supervision. We further show that a guided version of the training process can explicitly govern which summary style is partitioned between decoders, e.g. high abstractiveness vs. low abstractiveness or high specificity vs. low specificity, and also increase the stylistic-difference between individual decoders. Finally, our experiments demonstrate that our decoder framework is highly flexible: during inference, we can sample from individual decoders or mixtures of different subsets of the decoders to yield a diverse set of summaries and enforce single- and multi-style control over summary generation.
BookSum: A Collection of Datasets for Long-form Narrative Summarization
May 18, 2021

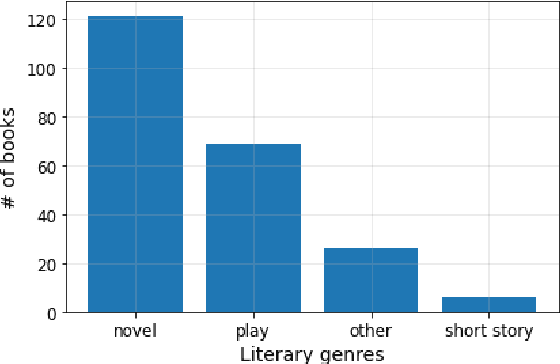

The majority of available text summarization datasets include short-form source documents that lack long-range causal and temporal dependencies, and often contain strong layout and stylistic biases. While relevant, such datasets will offer limited challenges for future generations of text summarization systems. We address these issues by introducing BookSum, a collection of datasets for long-form narrative summarization. Our dataset covers source documents from the literature domain, such as novels, plays and stories, and includes highly abstractive, human written summaries on three levels of granularity of increasing difficulty: paragraph-, chapter-, and book-level. The domain and structure of our dataset poses a unique set of challenges for summarization systems, which include: processing very long documents, non-trivial causal and temporal dependencies, and rich discourse structures. To facilitate future work, we trained and evaluated multiple extractive and abstractive summarization models as baselines for our dataset.
FeTaQA: Free-form Table Question Answering
Apr 01, 2021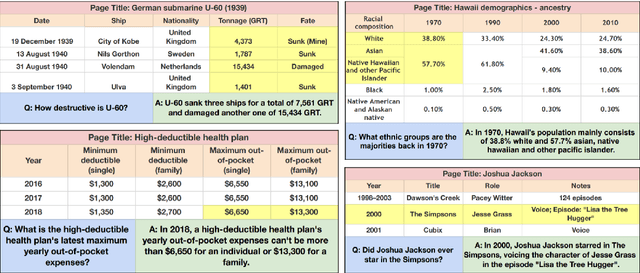

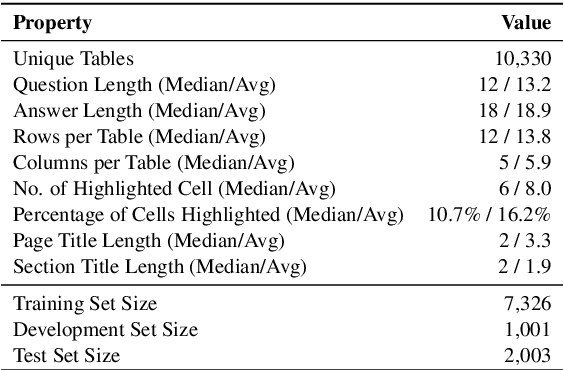
Existing table question answering datasets contain abundant factual questions that primarily evaluate the query and schema comprehension capability of a system, but they fail to include questions that require complex reasoning and integration of information due to the constraint of the associated short-form answers. To address these issues and to demonstrate the full challenge of table question answering, we introduce FeTaQA, a new dataset with 10K Wikipedia-based {table, question, free-form answer, supporting table cells} pairs. FeTaQA yields a more challenging table question answering setting because it requires generating free-form text answers after retrieval, inference, and integration of multiple discontinuous facts from a structured knowledge source. Unlike datasets of generative QA over text in which answers are prevalent with copies of short text spans from the source, answers in our dataset are human-generated explanations involving entities and their high-level relations. We provide two benchmark methods for the proposed task: a pipeline method based on semantic-parsing-based QA systems and an end-to-end method based on large pretrained text generation models, and show that FeTaQA poses a challenge for both methods.