 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Time is Here for Just-in-Time Systems: Challenges and Opportunities
May 22, 2026Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model
Feb 26, 2026Optimizing GPU kernels is critical for efficient modern machine learning systems yet remains challenging due to the complex interplay of design factors and rapid hardware evolution. Existing automated approaches typically treat Large Language Models (LLMs) merely as stochastic code generators within heuristic-guided evolutionary loops. These methods often struggle with complex kernels requiring coordinated, multi-step structural transformations, as they lack explicit planning capabilities and frequently discard promising strategies due to inefficient or incorrect intermediate implementations. To address this, we propose Search via Co-Evolving World Model and build K-Search based on this method. By replacing static search heuristics with a co-evolving world model, our framework leverages LLMs' prior domain knowledge to guide the search, actively exploring the optimization space. This approach explicitly decouples high-level algorithmic planning from low-level program instantiation, enabling the system to navigate non-monotonic optimization paths while remaining resilient to temporary implementation defects. We evaluate K-Search on diverse, complex kernels from FlashInfer, including GQA, MLA, and MoE kernels. Our results show that K-Search significantly outperforms state-of-the-art evolutionary search methods, achieving an average 2.10x improvement and up to a 14.3x gain on complex MoE kernels. On the GPUMode TriMul task, K-Search achieves state-of-the-art performance on H100, reaching 1030us and surpassing both prior evolution and human-designed solutions.
UCCL-EP: Portable Expert-Parallel Communication
Dec 22, 2025Mixture-of-Experts (MoE) workloads rely on expert parallelism (EP) to achieve high GPU efficiency. State-of-the-art EP communication systems such as DeepEP demonstrate strong performance but exhibit poor portability across heterogeneous GPU and NIC platforms. The poor portability is rooted in architecture: GPU-initiated token-level RDMA communication requires tight vertical integration between GPUs and NICs, e.g., GPU writes to NIC driver/MMIO interfaces. We present UCCL-EP, a portable EP communication system that delivers DeepEP-level performance across heterogeneous GPU and NIC hardware. UCCL-EP replaces GPU-initiated RDMA with a high-throughput GPU-CPU control channel: compact token-routing commands are transferred to multithreaded CPU proxies, which then issue GPUDirect RDMA operations on behalf of GPUs. UCCL-EP further emulates various ordering semantics required by specialized EP communication modes using RDMA immediate data, enabling correctness on NICs that lack such ordering, e.g., AWS EFA. We implement UCCL-EP on NVIDIA and AMD GPUs with EFA and Broadcom NICs. On EFA, it outperforms the best existing EP solution by up to $2.1\times$ for dispatch and combine throughput. On NVIDIA-only platform, UCCL-EP achieves comparable performance to the original DeepEP. UCCL-EP also improves token throughput on SGLang by up to 40% on the NVIDIA+EFA platform, and improves DeepSeek-V3 training throughput over the AMD Primus/Megatron-LM framework by up to 45% on a 16-node AMD+Broadcom platform.
LEANN: A Low-Storage Vector Index
Jun 09, 2025Embedding-based search is widely used in applications such as recommendation and retrieval-augmented generation (RAG). Recently, there is a growing demand to support these capabilities over personal data stored locally on devices. However, maintaining the necessary data structure associated with the embedding-based search is often infeasible due to its high storage overhead. For example, indexing 100 GB of raw data requires 150 to 700 GB of storage, making local deployment impractical. Reducing this overhead while maintaining search quality and latency becomes a critical challenge. In this paper, we present LEANN, a storage-efficient approximate nearest neighbor (ANN) search index optimized for resource-constrained personal devices. LEANN combines a compact graph-based structure with an efficient on-the-fly recomputation strategy to enable fast and accurate retrieval with minimal storage overhead. Our evaluation shows that LEANN reduces index size to under 5% of the original raw data, achieving up to 50 times smaller storage than standard indexes, while maintaining 90% top-3 recall in under 2 seconds on real-world question answering benchmarks.
Locality-aware Fair Scheduling in LLM Serving
Jan 24, 2025

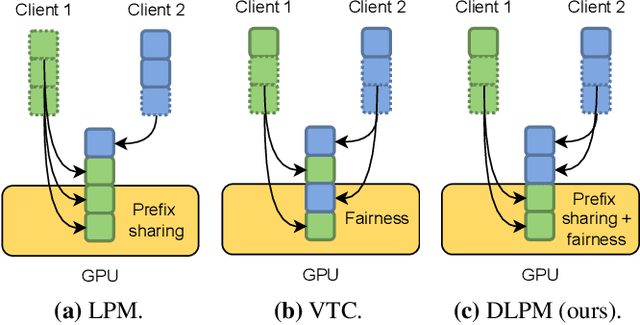
Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.
Pie: Pooling CPU Memory for LLM Inference
Nov 14, 2024
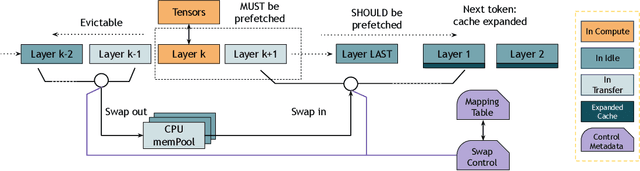


The rapid growth of LLMs has revolutionized natural language processing and AI analysis, but their increasing size and memory demands present significant challenges. A common solution is to spill over to CPU memory; however, traditional GPU-CPU memory swapping often results in higher latency and lower throughput. This paper introduces Pie, an LLM inference framework that addresses these challenges with performance-transparent swapping and adaptive expansion. By leveraging predictable memory access patterns and the high bandwidth of modern hardware like the NVIDIA GH200 Grace Hopper Superchip, Pie enables concurrent data swapping without affecting foreground computation, expanding effective memory without added latency. Adaptive expansion dynamically adjusts CPU memory allocation based on real-time information, optimizing memory usage and performance under varying conditions. Pie maintains low computation latency, high throughput, and high elasticity. Our experimental evaluation demonstrates that Pie achieves optimal swapping policy during cache warmup and effectively balances increased memory capacity with negligible impact on computation. With its extended capacity, Pie outperforms vLLM by up to 1.9X in throughput and 2X in latency. Additionally, Pie can reduce GPU memory usage by up to 1.67X while maintaining the same performance. Compared to FlexGen, an offline profiling-based swapping solution, Pie achieves magnitudes lower latency and 9.4X higher throughput.
SkyServe: Serving AI Models across Regions and Clouds with Spot Instances
Nov 03, 2024



Recent years have witnessed an explosive growth of AI models. The high cost of hosting AI services on GPUs and their demanding service requirements, make it timely and challenging to lower service costs and guarantee service quality. While spot instances have long been offered with a large discount, spot preemptions have discouraged users from using them to host model replicas when serving AI models. To address this, we introduce SkyServe, a system that efficiently serves AI models over a mixture of spot and on-demand replicas across regions and clouds. SkyServe intelligently spreads spot replicas across different failure domains (e.g., regions or clouds) to improve availability and reduce correlated preemptions, overprovisions cheap spot replicas than required as a safeguard against possible preemptions, and dynamically falls back to on-demand replicas when spot replicas become unavailable. We compare SkyServe with both research and production systems on real AI workloads: SkyServe reduces cost by up to 44% while achieving high resource availability compared to using on-demand replicas. Additionally, SkyServe improves P50, P90, and P99 latency by up to 2.6x, 3.1x, 2.7x compared to other research and production systems.
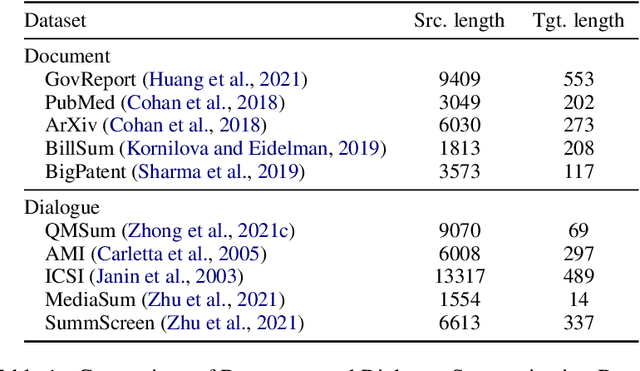
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021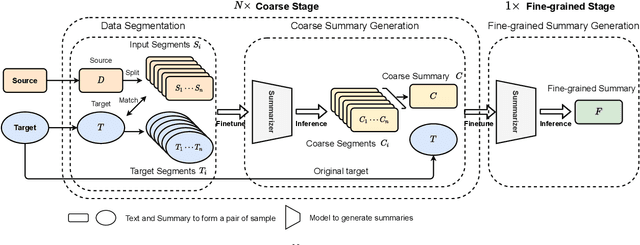
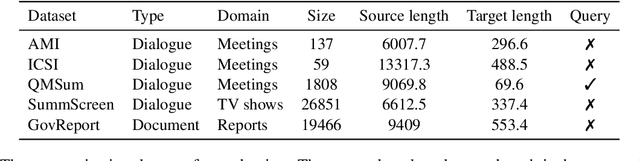
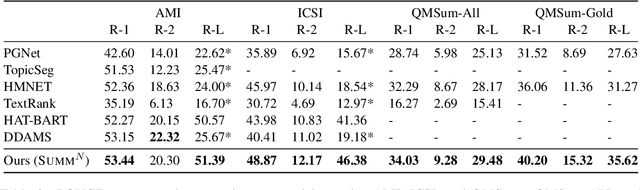
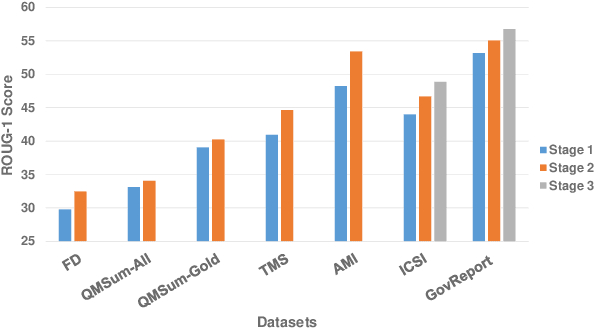
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021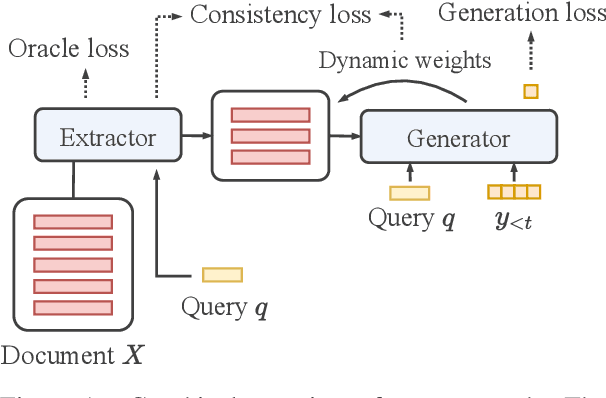
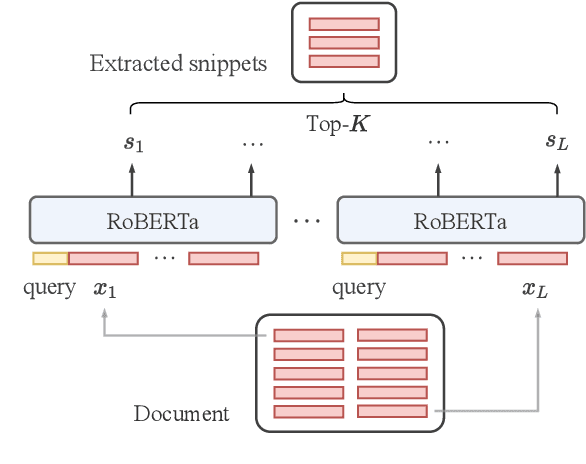
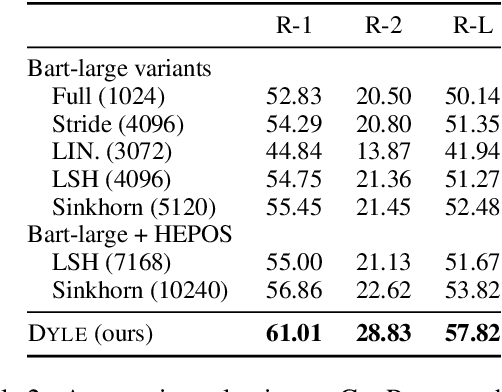
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.
Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Sep 21, 2021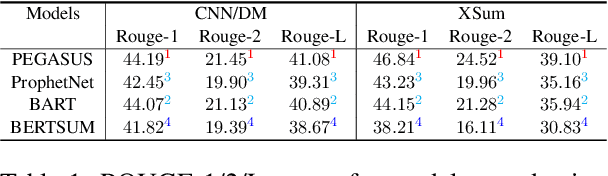
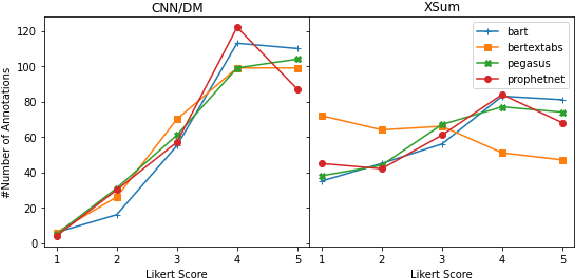
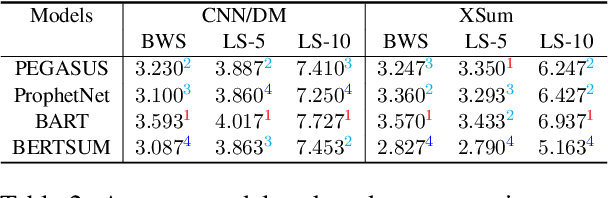
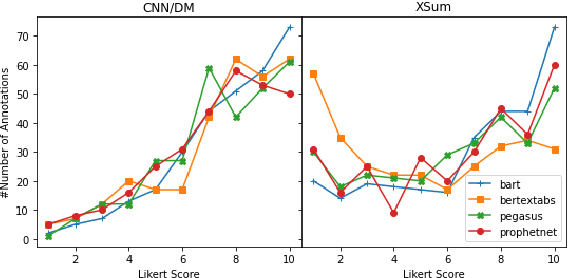
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.