 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCCL-EP: Portable Expert-Parallel Communication
Dec 22, 2025Mixture-of-Experts (MoE) workloads rely on expert parallelism (EP) to achieve high GPU efficiency. State-of-the-art EP communication systems such as DeepEP demonstrate strong performance but exhibit poor portability across heterogeneous GPU and NIC platforms. The poor portability is rooted in architecture: GPU-initiated token-level RDMA communication requires tight vertical integration between GPUs and NICs, e.g., GPU writes to NIC driver/MMIO interfaces. We present UCCL-EP, a portable EP communication system that delivers DeepEP-level performance across heterogeneous GPU and NIC hardware. UCCL-EP replaces GPU-initiated RDMA with a high-throughput GPU-CPU control channel: compact token-routing commands are transferred to multithreaded CPU proxies, which then issue GPUDirect RDMA operations on behalf of GPUs. UCCL-EP further emulates various ordering semantics required by specialized EP communication modes using RDMA immediate data, enabling correctness on NICs that lack such ordering, e.g., AWS EFA. We implement UCCL-EP on NVIDIA and AMD GPUs with EFA and Broadcom NICs. On EFA, it outperforms the best existing EP solution by up to $2.1\times$ for dispatch and combine throughput. On NVIDIA-only platform, UCCL-EP achieves comparable performance to the original DeepEP. UCCL-EP also improves token throughput on SGLang by up to 40% on the NVIDIA+EFA platform, and improves DeepSeek-V3 training throughput over the AMD Primus/Megatron-LM framework by up to 45% on a 16-node AMD+Broadcom platform.
Bandwidth Allocation for Cloud-Augmented Autonomous Driving
Mar 26, 2025Autonomous vehicle (AV) control systems increasingly rely on ML models for tasks such as perception and planning. Current practice is to run these models on the car's local hardware due to real-time latency constraints and reliability concerns, which limits model size and thus accuracy. Prior work has observed that we could augment current systems by running larger models in the cloud, relying on faster cloud runtimes to offset the cellular network latency. However, prior work does not account for an important practical constraint: limited cellular bandwidth. We show that, for typical bandwidth levels, proposed techniques for cloud-augmented AV models take too long to transfer data, thus mostly falling back to the on-car models and resulting in no accuracy improvement. In this work, we show that realizing cloud-augmented AV models requires intelligent use of this scarce bandwidth, i.e. carefully allocating bandwidth across tasks and providing multiple data compression and model options. We formulate this as a resource allocation problem to maximize car utility, and present our system \sysname which achieves an increase in average model accuracy by up to 15 percentage points on driving scenarios from the Waymo Open Dataset.
SkyServe: Serving AI Models across Regions and Clouds with Spot Instances
Nov 03, 2024



Recent years have witnessed an explosive growth of AI models. The high cost of hosting AI services on GPUs and their demanding service requirements, make it timely and challenging to lower service costs and guarantee service quality. While spot instances have long been offered with a large discount, spot preemptions have discouraged users from using them to host model replicas when serving AI models. To address this, we introduce SkyServe, a system that efficiently serves AI models over a mixture of spot and on-demand replicas across regions and clouds. SkyServe intelligently spreads spot replicas across different failure domains (e.g., regions or clouds) to improve availability and reduce correlated preemptions, overprovisions cheap spot replicas than required as a safeguard against possible preemptions, and dynamically falls back to on-demand replicas when spot replicas become unavailable. We compare SkyServe with both research and production systems on real AI workloads: SkyServe reduces cost by up to 44% while achieving high resource availability compared to using on-demand replicas. Additionally, SkyServe improves P50, P90, and P99 latency by up to 2.6x, 3.1x, 2.7x compared to other research and production systems.
Managing Bandwidth: The Key to Cloud-Assisted Autonomous Driving
Oct 21, 2024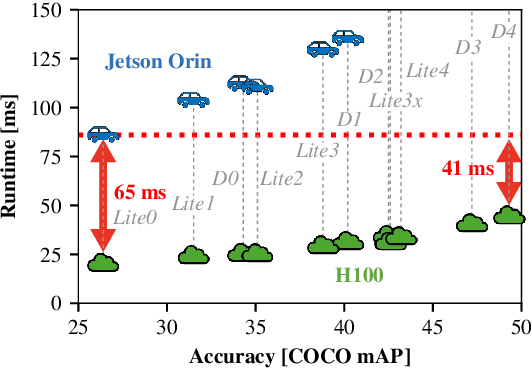
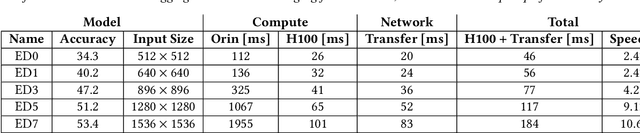

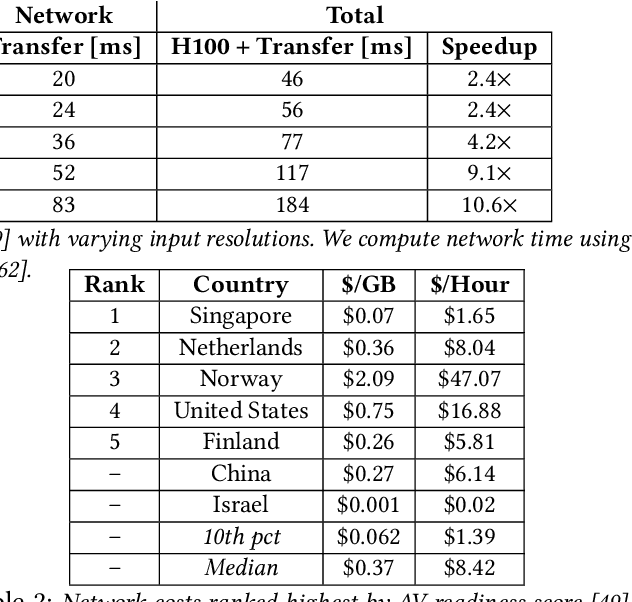
Prevailing wisdom asserts that one cannot rely on the cloud for critical real-time control systems like self-driving cars. We argue that we can, and must. Following the trends of increasing model sizes, improvements in hardware, and evolving mobile networks, we identify an opportunity to offload parts of time-sensitive and latency-critical compute to the cloud. Doing so requires carefully allocating bandwidth to meet strict latency SLOs, while maximizing benefit to the car.
How to Train your DNN: The Network Operator Edition
Apr 21, 2020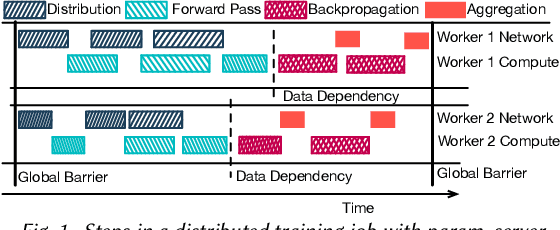
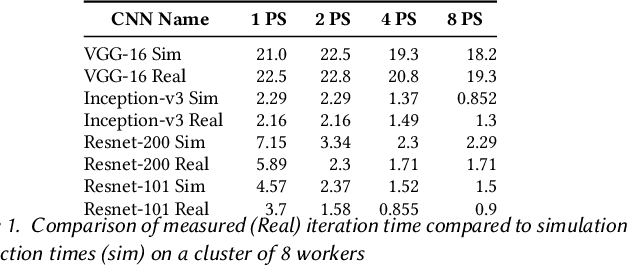
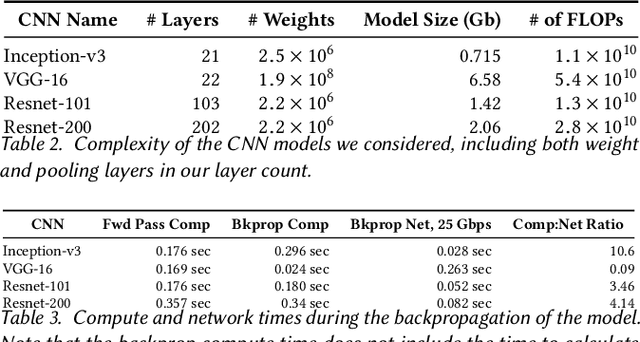
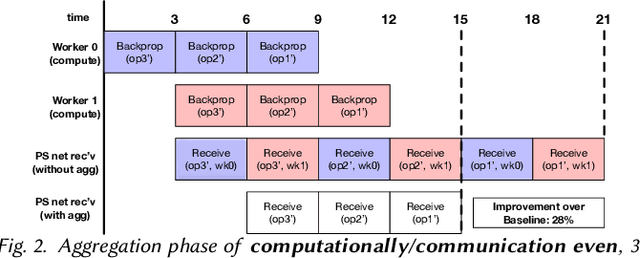
Deep Neural Nets have hit quite a crest, But physical networks are where they must rest, And here we put them all to the test, To see which network optimization is best.