 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandwidth Allocation for Cloud-Augmented Autonomous Driving
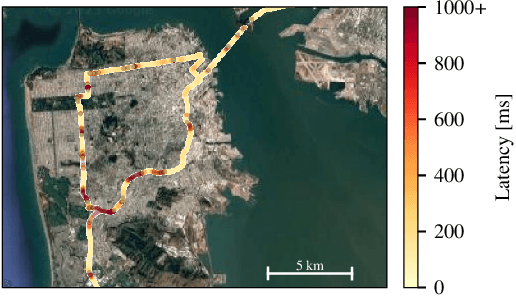
Mar 26, 2025Autonomous vehicle (AV) control systems increasingly rely on ML models for tasks such as perception and planning. Current practice is to run these models on the car's local hardware due to real-time latency constraints and reliability concerns, which limits model size and thus accuracy. Prior work has observed that we could augment current systems by running larger models in the cloud, relying on faster cloud runtimes to offset the cellular network latency. However, prior work does not account for an important practical constraint: limited cellular bandwidth. We show that, for typical bandwidth levels, proposed techniques for cloud-augmented AV models take too long to transfer data, thus mostly falling back to the on-car models and resulting in no accuracy improvement. In this work, we show that realizing cloud-augmented AV models requires intelligent use of this scarce bandwidth, i.e. carefully allocating bandwidth across tasks and providing multiple data compression and model options. We formulate this as a resource allocation problem to maximize car utility, and present our system \sysname which achieves an increase in average model accuracy by up to 15 percentage points on driving scenarios from the Waymo Open Dataset.
MoE-Lightning: High-Throughput MoE Inference on Memory-constrained GPUs
Nov 18, 2024



Efficient deployment of large language models, particularly Mixture of Experts (MoE), on resource-constrained platforms presents significant challenges, especially in terms of computational efficiency and memory utilization. The MoE architecture, renowned for its ability to increase model capacity without a proportional increase in inference cost, greatly reduces the token generation latency compared with dense models. However, the large model size makes MoE models inaccessible to individuals without high-end GPUs. In this paper, we propose a high-throughput MoE batch inference system, that significantly outperforms past work. MoE-Lightning introduces a novel CPU-GPU-I/O pipelining schedule, CGOPipe, with paged weights to achieve high resource utilization, and a performance model, HRM, based on a Hierarchical Roofline Model we introduce to help find policies with higher throughput than existing systems. MoE-Lightning can achieve up to 10.3x higher throughput than state-of-the-art offloading-enabled LLM inference systems for Mixtral 8x7B on a single T4 GPU (16GB). When the theoretical system throughput is bounded by the GPU memory, MoE-Lightning can reach the throughput upper bound with 2-3x less CPU memory, significantly increasing resource utilization. MoE-Lightning also supports efficient batch inference for much larger MoEs (e.g., Mixtral 8x22B and DBRX) on multiple low-cost GPUs (e.g., 2-4 T4).
Managing Bandwidth: The Key to Cloud-Assisted Autonomous Driving
Oct 21, 2024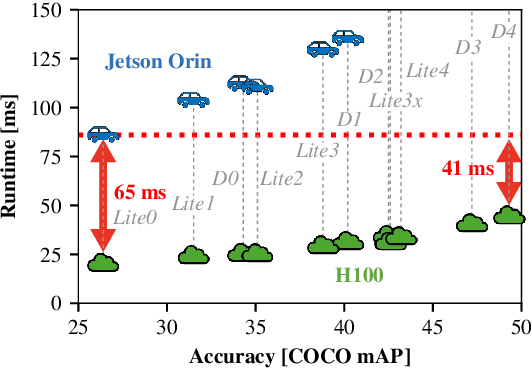
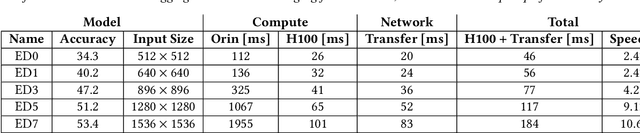

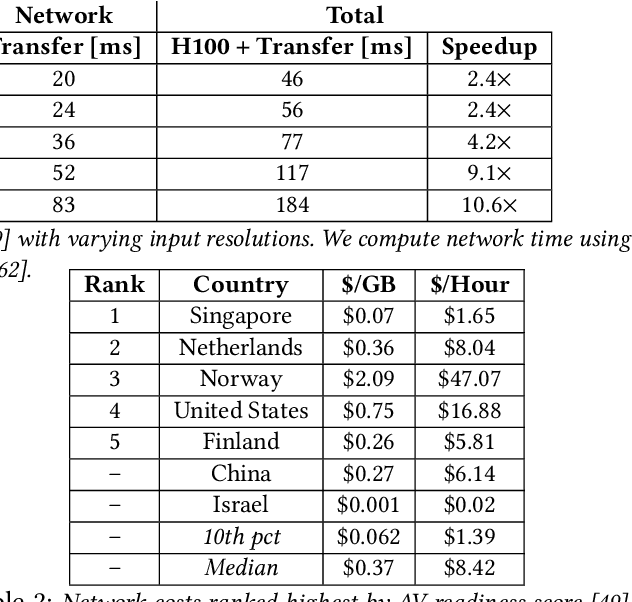
Prevailing wisdom asserts that one cannot rely on the cloud for critical real-time control systems like self-driving cars. We argue that we can, and must. Following the trends of increasing model sizes, improvements in hardware, and evolving mobile networks, we identify an opportunity to offload parts of time-sensitive and latency-critical compute to the cloud. Doing so requires carefully allocating bandwidth to meet strict latency SLOs, while maximizing benefit to the car.
Scalable Multi-Domain Adaptation of Language Models using Modular Experts
Oct 14, 2024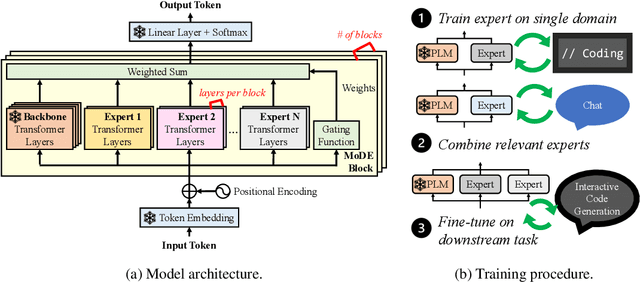
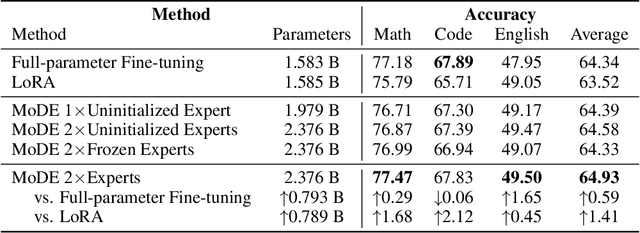
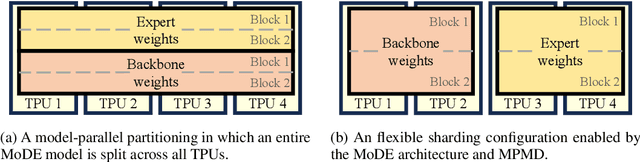
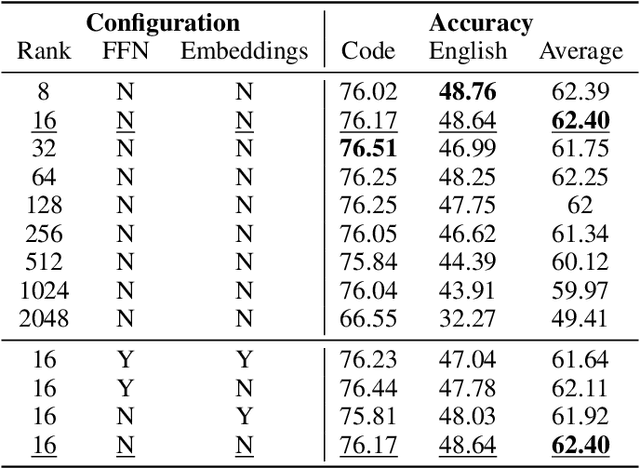
Domain-specific adaptation is critical to maximizing the performance of pre-trained language models (PLMs) on one or multiple targeted tasks, especially under resource-constrained use cases, such as edge devices. However, existing methods often struggle to balance domain-specific performance, retention of general knowledge, and efficiency for training and inference. To address these challenges, we propose Modular Domain Experts (MoDE). MoDE is a mixture-of-experts architecture that augments a general PLMs with modular, domain-specialized experts. These experts are trained independently and composed together via a lightweight training process. In contrast to standard low-rank adaptation methods, each MoDE expert consists of several transformer layers which scale better with more training examples and larger parameter counts. Our evaluation demonstrates that MoDE achieves comparable target performances to full parameter fine-tuning while achieving 1.65% better retention performance. Moreover, MoDE's architecture enables flexible sharding configurations and improves training speeds by up to 38% over state-of-the-art distributed training configurations.
Leveraging Cloud Computing to Make Autonomous Vehicles Safer
Aug 06, 2023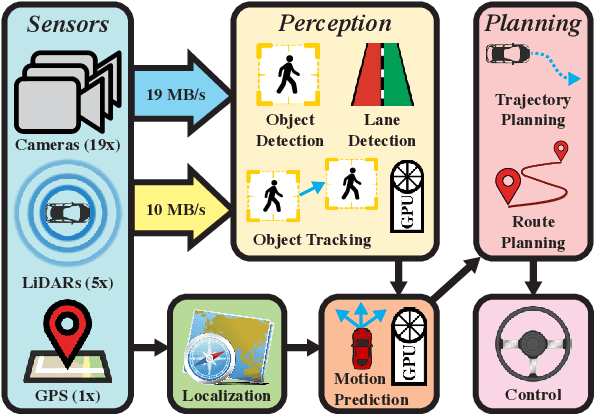
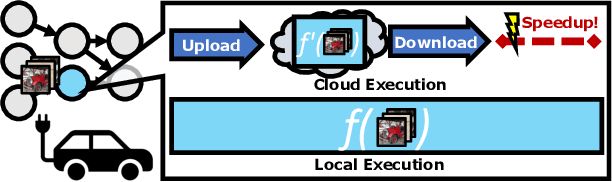
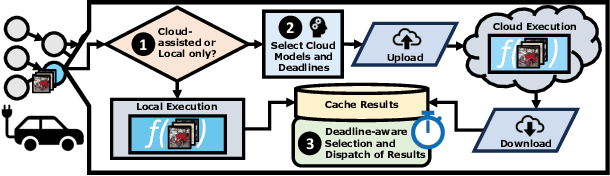
The safety of autonomous vehicles (AVs) depends on their ability to perform complex computations on high-volume sensor data in a timely manner. Their ability to run these computations with state-of-the-art models is limited by the processing power and slow update cycles of their onboard hardware. In contrast, cloud computing offers the ability to burst computation to vast amounts of the latest generation of hardware. However, accessing these cloud resources requires traversing wireless networks that are often considered to be too unreliable for real-time AV driving applications. Our work seeks to harness this unreliable cloud to enhance the accuracy of an AV's decisions, while ensuring that it can always fall back to its on-board computational capabilities. We identify three mechanisms that can be used by AVs to safely leverage the cloud for accuracy enhancements, and elaborate why current execution systems fail to enable these mechanisms. To address these limitations, we provide a system design based on the speculative execution of an AV's pipeline in the cloud, and show the efficacy of this approach in simulations of complex real-world scenarios that apply these mechanisms.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022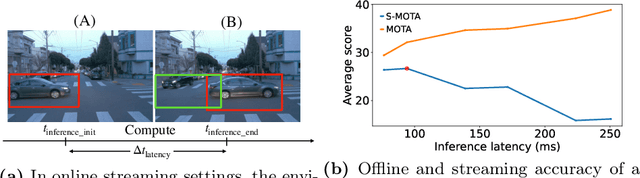
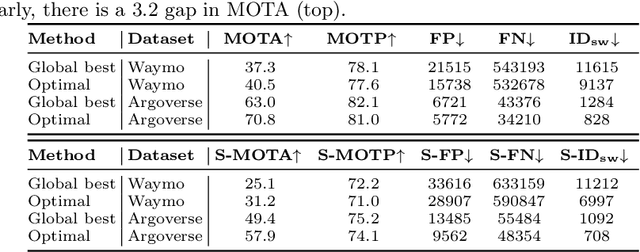
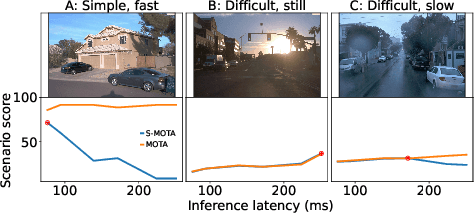
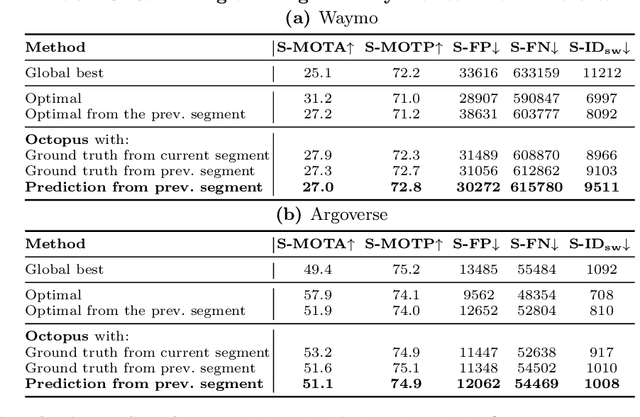
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021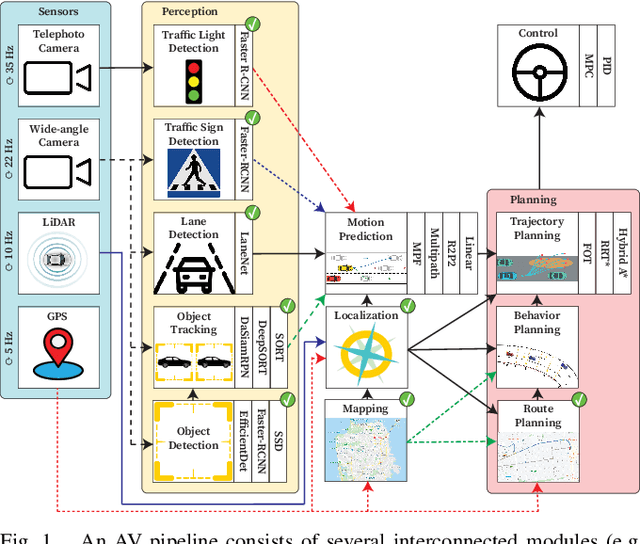

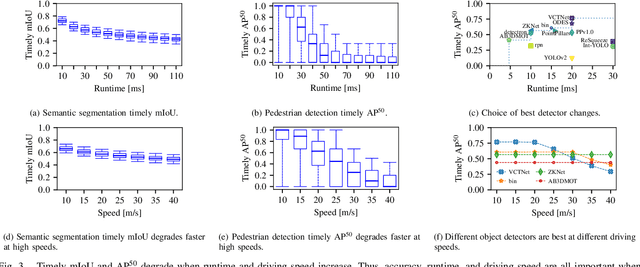
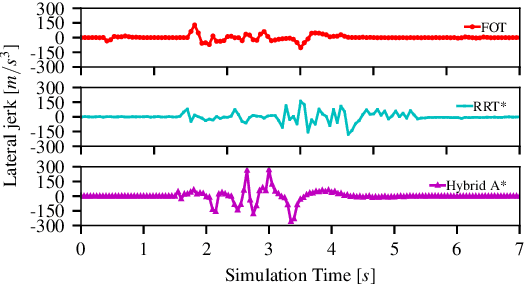
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.