 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperServe: Fine-Grained Inference Serving for Unpredictable Workloads
Dec 27, 2023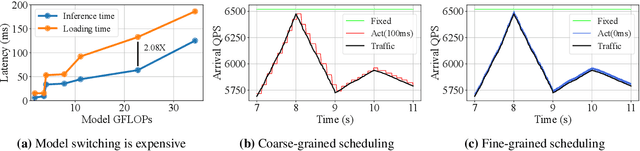
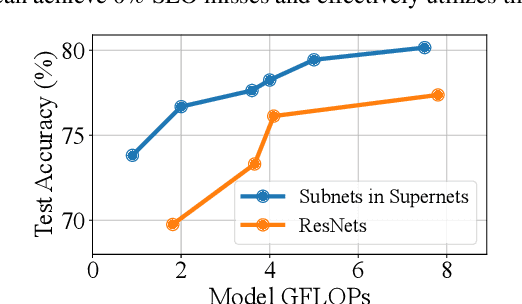
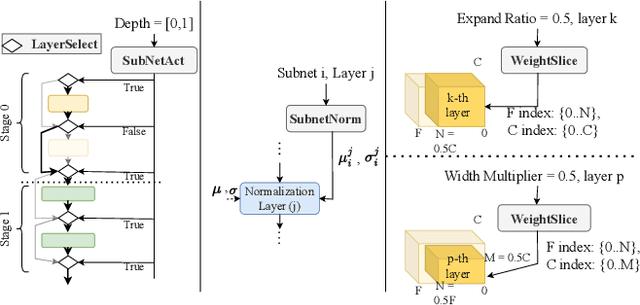
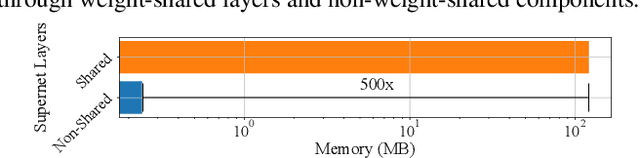
The increasing deployment of ML models on the critical path of production applications in both datacenter and the edge requires ML inference serving systems to serve these models under unpredictable and bursty request arrival rates. Serving models under such conditions requires these systems to strike a careful balance between the latency and accuracy requirements of the application and the overall efficiency of utilization of scarce resources. State-of-the-art systems resolve this tension by either choosing a static point in the latency-accuracy tradeoff space to serve all requests or load specific models on the critical path of request serving. In this work, we instead resolve this tension by simultaneously serving the entire-range of models spanning the latency-accuracy tradeoff space. Our novel mechanism, SubNetAct, achieves this by carefully inserting specialized operators in weight-shared SuperNetworks. These operators enable SubNetAct to dynamically route requests through the network to meet a latency and accuracy target. SubNetAct requires upto 2.6x lower memory to serve a vastly-higher number of models than prior state-of-the-art. In addition, SubNetAct's near-instantaneous actuation of models unlocks the design space of fine-grained, reactive scheduling policies. We explore the design of one such extremely effective policy, SlackFit and instantiate both SubNetAct and SlackFit in a real system, SuperServe. SuperServe achieves 4.67% higher accuracy for the same SLO attainment and 2.85x higher SLO attainment for the same accuracy on a trace derived from the real-world Microsoft Azure Functions workload and yields the best trade-offs on a wide range of extremely-bursty synthetic traces automatically.
Leveraging Cloud Computing to Make Autonomous Vehicles Safer
Aug 06, 2023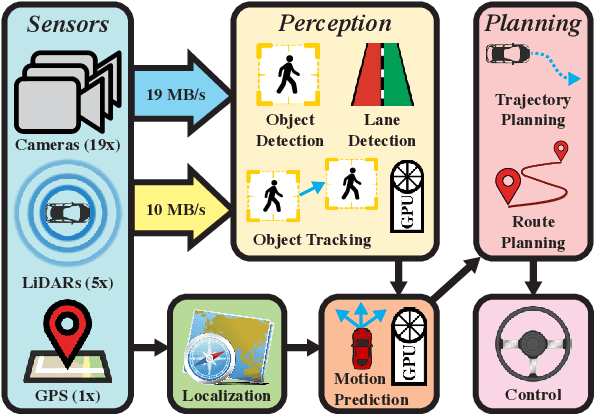
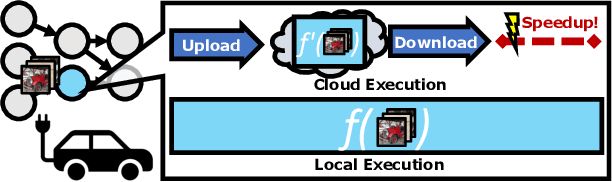
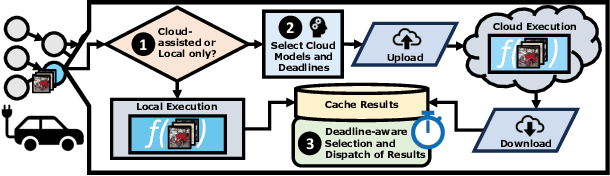
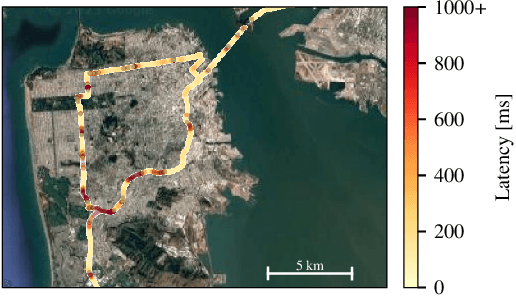
The safety of autonomous vehicles (AVs) depends on their ability to perform complex computations on high-volume sensor data in a timely manner. Their ability to run these computations with state-of-the-art models is limited by the processing power and slow update cycles of their onboard hardware. In contrast, cloud computing offers the ability to burst computation to vast amounts of the latest generation of hardware. However, accessing these cloud resources requires traversing wireless networks that are often considered to be too unreliable for real-time AV driving applications. Our work seeks to harness this unreliable cloud to enhance the accuracy of an AV's decisions, while ensuring that it can always fall back to its on-board computational capabilities. We identify three mechanisms that can be used by AVs to safely leverage the cloud for accuracy enhancements, and elaborate why current execution systems fail to enable these mechanisms. To address these limitations, we provide a system design based on the speculative execution of an AV's pipeline in the cloud, and show the efficacy of this approach in simulations of complex real-world scenarios that apply these mechanisms.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022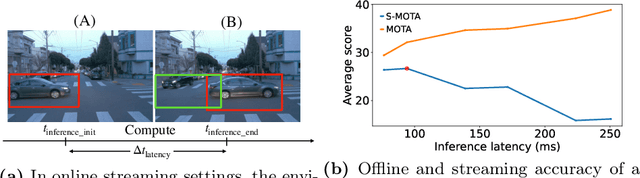
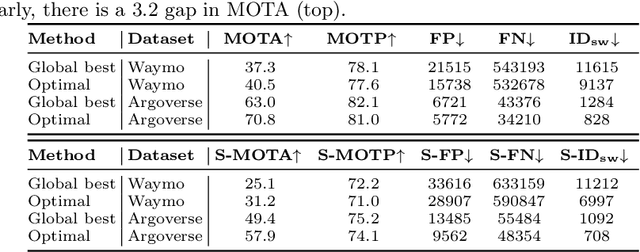
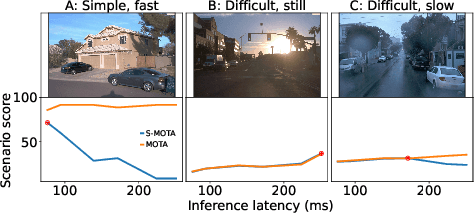
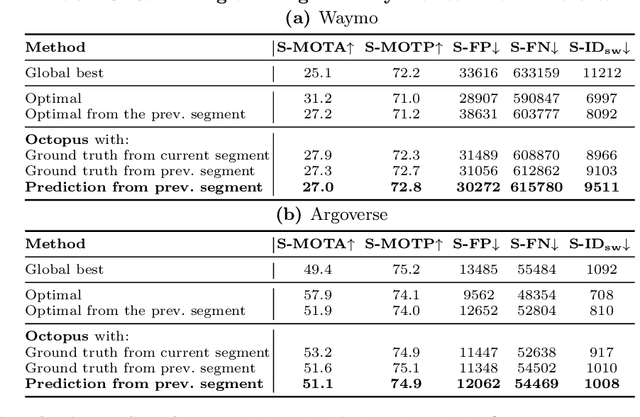
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Pylot: A Modular Platform for Exploring Latency-Accuracy Tradeoffs in Autonomous Vehicles
Apr 16, 2021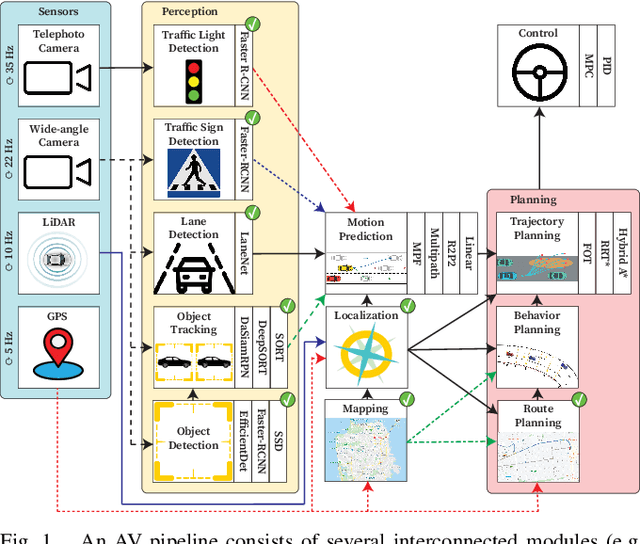

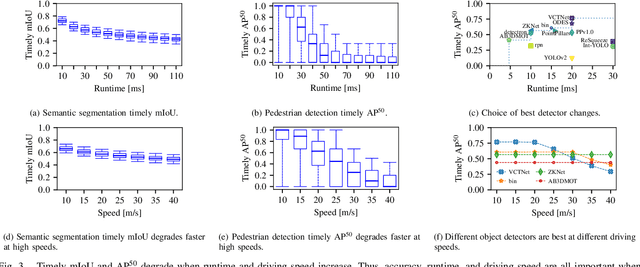
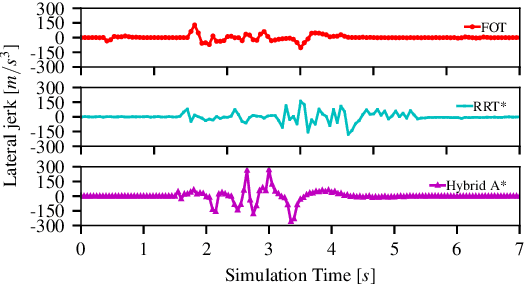
We present Pylot, a platform for autonomous vehicle (AV) research and development, built with the goal to allow researchers to study the effects of the latency and accuracy of their models and algorithms on the end-to-end driving behavior of an AV. This is achieved through a modular structure enabled by our high-performance dataflow system that represents AV software pipeline components (object detectors, motion planners, etc.) as a dataflow graph of operators which communicate on data streams using timestamped messages. Pylot readily interfaces with popular AV simulators like CARLA, and is easily deployable to real-world vehicles with minimal code changes. To reduce the burden of developing an entire pipeline for evaluating a single component, Pylot provides several state-of-the-art reference implementations for the various components of an AV pipeline. Using these reference implementations, a Pylot-based AV pipeline is able to drive a real vehicle, and attains a high score on the CARLA Autonomous Driving Challenge. We also present several case studies enabled by Pylot, including evidence of a need for context-dependent components, and per-component time allocation. Pylot is open source, with the code available at https://github.com/erdos-project/pylot.