 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKLAS: Using Similarity to Stitch Neural Networks for Improved Accuracy-Efficiency Tradeoffs
May 28, 2026Given the wide range of deployment targets, flexible model selection is essential for optimizing performance within a given compute budget. Recent work demonstrates that stitching pretrained models within a model family enables cost-effective interpolation of the accuracy-efficiency tradeoff space. Stitching transforms intermediate activations from one pretrained model into another, producing a new interpolated stitched network. Such networks provide a pool of deployment options along the accuracy-efficiency spectrum. However, existing stitching approaches often yield suboptimal tradeoffs and lack generalizability, as they primarily rely on heuristics to select stitch configurations. We argue that constructing improved accuracy-efficiency tradeoffs requires explicitly capturing and leveraging the similarity between pretrained models being stitched. To this end, we introduce KLAS, a novel stitch selection framework that automates and generalizes stitch selection across model families by leveraging KL divergence between intermediate representations. KLAS identifies the most promising binary stitches from the $O(k^2n^2)$ possibilities for $k$ pretrained models of depth $n$. Through comprehensive experiments, we demonstrate that KLAS improves the accuracy-efficiency curve of stitched models at the same finetuning cost as baselines. KLAS achieves up to $1.21\%$ higher ImageNet-1K top-1 accuracy at the same computational cost, or maintains accuracy with a $1.33\times$ reduction in FLOPs.
Revati: Transparent GPU-Free Time-Warp Emulation for LLM Serving
Jan 01, 2026Deploying LLMs efficiently requires testing hundreds of serving configurations, but evaluating each one on a GPU cluster takes hours and costs thousands of dollars. Discrete-event simulators are faster and cheaper, but they require re-implementing the serving system's control logic -- a burden that compounds as frameworks evolve. We present Revati, a time-warp emulator that enables performance modeling by directly executing real serving system code at simulation-like speed. The system intercepts CUDA API calls to virtualize device management, allowing serving frameworks to run without physical GPUs. Instead of executing GPU kernels, it performs time jumps -- fast-forwarding virtual time by predicted kernel durations. We propose a coordination protocol that synchronizes these jumps across distributed processes while preserving causality. On vLLM and SGLang, Revati achieves less than 5% prediction error across multiple models and parallelism configurations, while running 5-17x faster than real GPU execution.
Maya: Optimizing Deep Learning Training Workloads using Emulated Virtual Accelerators
Mar 26, 2025



Training large foundation models costs hundreds of millions of dollars, making deployment optimization critical. Current approaches require machine learning engineers to manually craft training recipes through error-prone trial-and-error on expensive compute clusters. To enable efficient exploration of training configurations, researchers have developed performance modeling systems. However, these systems force users to translate their workloads into custom specification languages, introducing a fundamental semantic gap between the actual workload and its representation. This gap creates an inherent tradeoff: systems must either support a narrow set of workloads to maintain usability, require complex specifications that limit practical adoption, or compromise prediction accuracy with simplified models. We present Maya, a performance modeling system that eliminates these tradeoffs through transparent device emulation. By operating at the narrow interface between training frameworks and accelerator devices, Maya can capture complete workload behavior without requiring code modifications or translations. Maya intercepts device API calls from unmodified training code to directly observe low-level operations, enabling accurate performance prediction while maintaining both ease of use and generality. Our evaluation shows Maya achieves less than 5% prediction error across diverse models and optimization strategies, identifying configurations that reduce training costs by up to 56% compared to existing approaches.
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
Feb 19, 2025



Transformer-based Large Language Models rely critically on KV cache to efficiently handle extended contexts during the decode phase. Yet, the size of the KV cache grows proportionally with the input length, burdening both memory bandwidth and capacity as decoding progresses. To address this challenge, we present RocketKV, a training-free KV cache compression strategy designed specifically to reduce both memory bandwidth and capacity demand of KV cache during the decode phase. RocketKV contains two consecutive stages. In the first stage, it performs coarse-grain KV cache eviction on the input sequence tokens with SnapKV++, a method improved upon SnapKV by introducing adaptive pooling size and full compatibility with grouped-query attention. In the second stage, it adopts a hybrid attention method to conduct fine-grain top-k sparse attention, approximating the attention scores by leveraging both head and sequence dimensional reductions. Combining these two stages, RocketKV achieves significant KV cache fetching bandwidth and storage savings while maintaining comparable accuracy to full KV cache attention. We show that RocketKV provides end-to-end speedup by up to 3$\times$ as well as peak memory reduction by up to 31% in the decode phase on an NVIDIA H100 GPU compared to the full KV cache baseline, while achieving negligible accuracy loss on a variety of long-context tasks.
Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
Nov 29, 2024



Low-rank adapters have become a standard approach for efficiently fine-tuning large language models (LLMs), but they often fall short of achieving the performance of full fine-tuning. We propose a method, LoRA Silver Bullet or LoRA-SB, that approximates full fine-tuning within low-rank subspaces using a carefully designed initialization strategy. We theoretically demonstrate that the architecture of LoRA-XS, which inserts a trainable (r x r) matrix between B and A while keeping other matrices fixed, provides the precise conditions needed for this approximation. We leverage its constrained update space to achieve optimal scaling for high-rank gradient updates while removing the need for hyperparameter tuning. We prove that our initialization offers an optimal low-rank approximation of the initial gradient and preserves update directions throughout training. Extensive experiments across mathematical reasoning, commonsense reasoning, and language understanding tasks demonstrate that our approach exceeds the performance of standard LoRA while using 27-90x fewer parameters, and comprehensively outperforms LoRA-XS. Our findings establish that it is possible to simulate full fine-tuning in low-rank subspaces, and achieve significant efficiency gains without sacrificing performance. Our code is publicly available at https://github.com/RaghavSinghal10/lora-sb.
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Sep 25, 2024
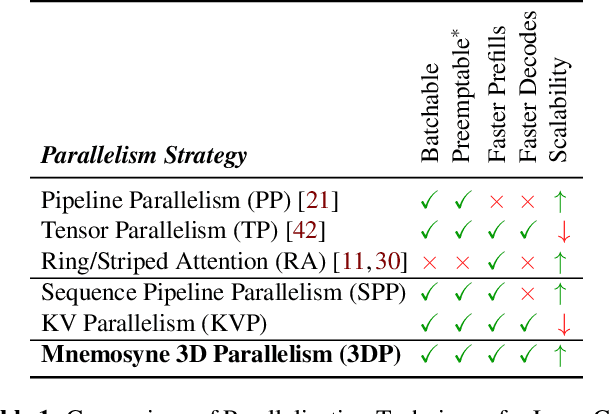
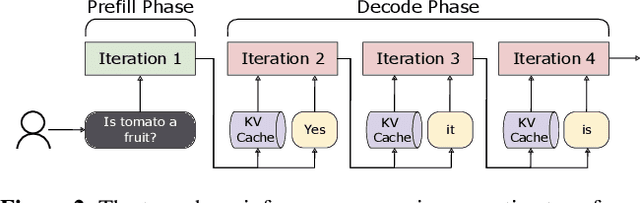
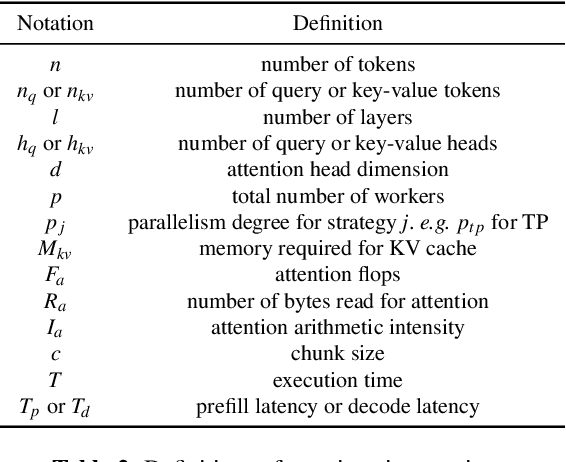
As large language models (LLMs) evolve to handle increasingly longer contexts, serving inference requests for context lengths in the range of millions of tokens presents unique challenges. While existing techniques are effective for training, they fail to address the unique challenges of inference, such as varying prefill and decode phases and their associated latency constraints - like Time to First Token (TTFT) and Time Between Tokens (TBT). Furthermore, there are no long context inference solutions that allow batching requests to increase the hardware utilization today. In this paper, we propose three key innovations for efficient interactive long context LLM inference, without resorting to any approximation: adaptive chunking to reduce prefill overheads in mixed batching, Sequence Pipeline Parallelism (SPP) to lower TTFT, and KV Cache Parallelism (KVP) to minimize TBT. These contributions are combined into a 3D parallelism strategy, enabling Mnemosyne to scale interactive inference to context lengths at least up to 10 million tokens with high throughput enabled with batching. To our knowledge, Mnemosyne is the first to be able to achieve support for 10 million long context inference efficiently, while satisfying production-grade SLOs on TBT (30ms) on contexts up to and including 10 million.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024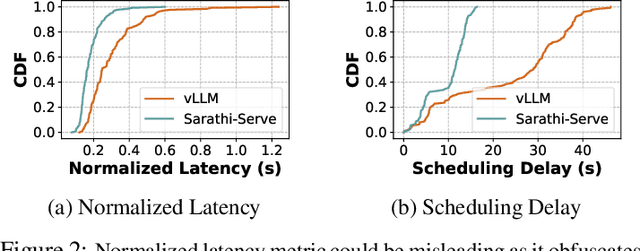
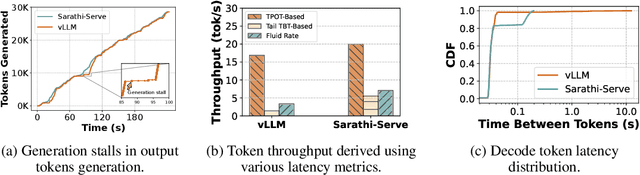
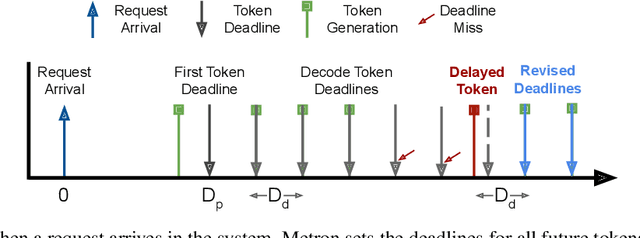
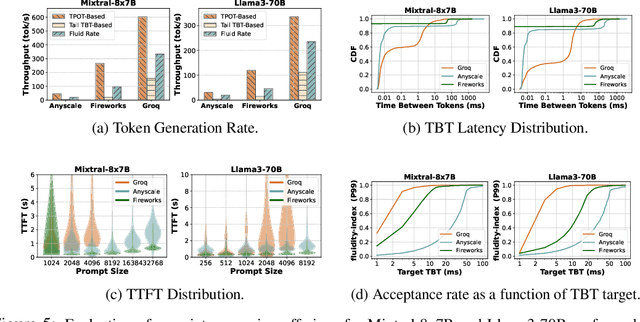
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
DεpS: Delayed ε-Shrinking for Faster Once-For-All Training
Jul 08, 2024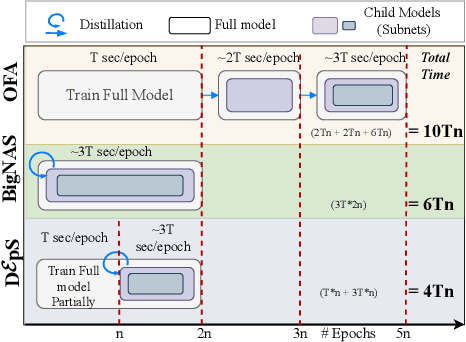

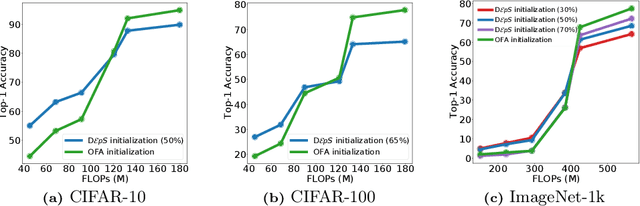

CNNs are increasingly deployed across different hardware, dynamic environments, and low-power embedded devices. This has led to the design and training of CNN architectures with the goal of maximizing accuracy subject to such variable deployment constraints. As the number of deployment scenarios grows, there is a need to find scalable solutions to design and train specialized CNNs. Once-for-all training has emerged as a scalable approach that jointly co-trains many models (subnets) at once with a constant training cost and finds specialized CNNs later. The scalability is achieved by training the full model and simultaneously reducing it to smaller subnets that share model weights (weight-shared shrinking). However, existing once-for-all training approaches incur huge training costs reaching 1200 GPU hours. We argue this is because they either start the process of shrinking the full model too early or too late. Hence, we propose Delayed $\epsilon$-Shrinking (D$\epsilon$pS) that starts the process of shrinking the full model when it is partially trained (~50%) which leads to training cost improvement and better in-place knowledge distillation to smaller models. The proposed approach also consists of novel heuristics that dynamically adjust subnet learning rates incrementally (E), leading to improved weight-shared knowledge distillation from larger to smaller subnets as well. As a result, DEpS outperforms state-of-the-art once-for-all training techniques across different datasets including CIFAR10/100, ImageNet-100, and ImageNet-1k on accuracy and cost. It achieves 1.83% higher ImageNet-1k top1 accuracy or the same accuracy with 1.3x reduction in FLOPs and 2.5x drop in training cost (GPU*hrs)
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024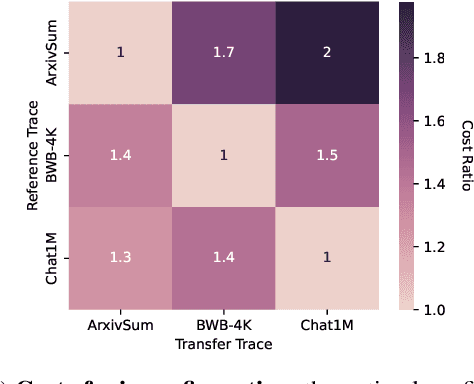

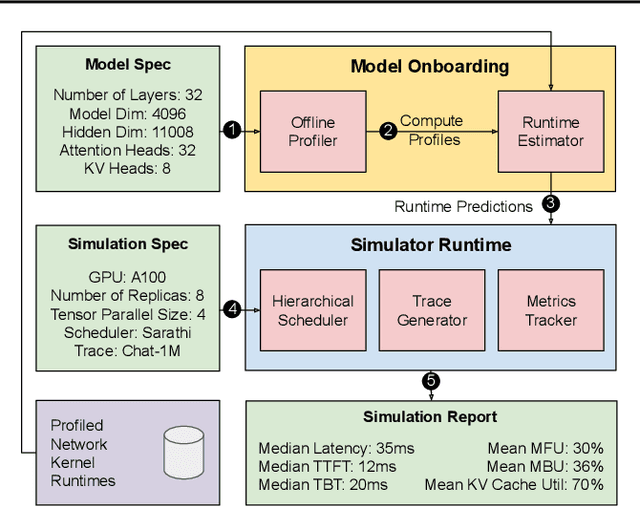
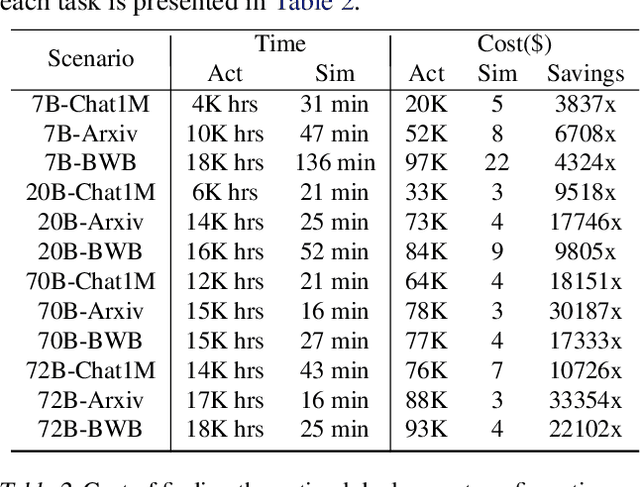
Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024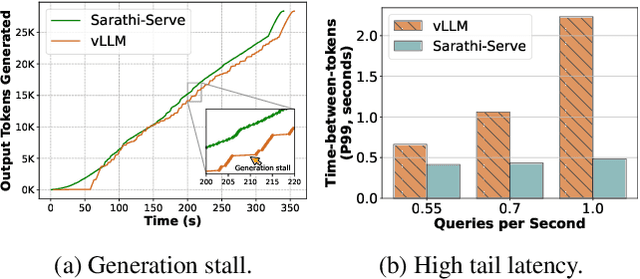

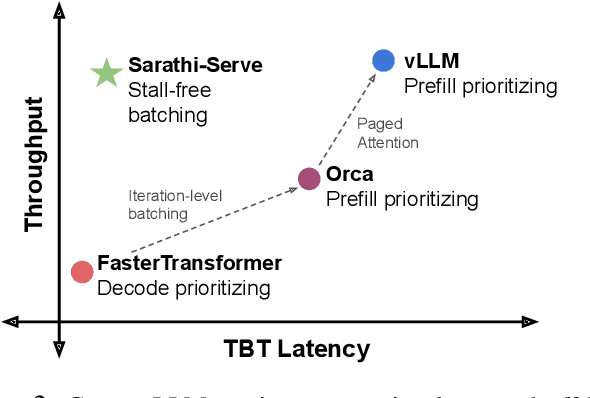

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.