 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Paper and Code
Sep 25, 2024
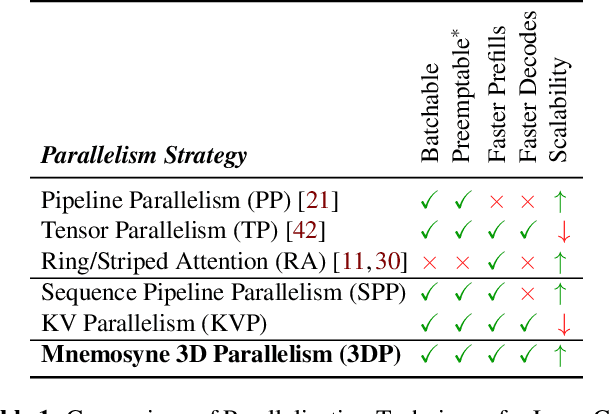
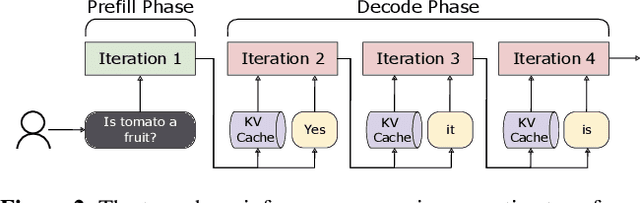
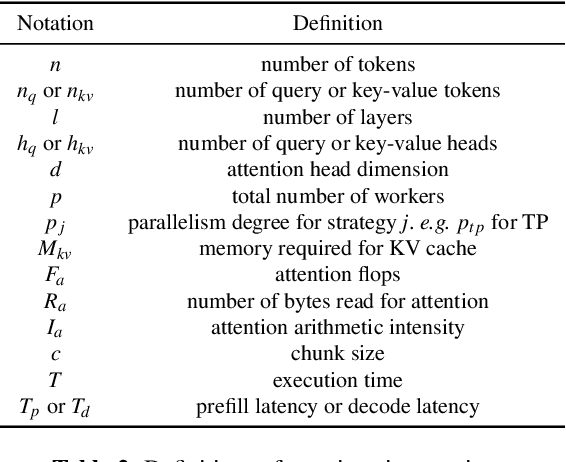
As large language models (LLMs) evolve to handle increasingly longer contexts, serving inference requests for context lengths in the range of millions of tokens presents unique challenges. While existing techniques are effective for training, they fail to address the unique challenges of inference, such as varying prefill and decode phases and their associated latency constraints - like Time to First Token (TTFT) and Time Between Tokens (TBT). Furthermore, there are no long context inference solutions that allow batching requests to increase the hardware utilization today. In this paper, we propose three key innovations for efficient interactive long context LLM inference, without resorting to any approximation: adaptive chunking to reduce prefill overheads in mixed batching, Sequence Pipeline Parallelism (SPP) to lower TTFT, and KV Cache Parallelism (KVP) to minimize TBT. These contributions are combined into a 3D parallelism strategy, enabling Mnemosyne to scale interactive inference to context lengths at least up to 10 million tokens with high throughput enabled with batching. To our knowledge, Mnemosyne is the first to be able to achieve support for 10 million long context inference efficiently, while satisfying production-grade SLOs on TBT (30ms) on contexts up to and including 10 million.