 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevati: Transparent GPU-Free Time-Warp Emulation for LLM Serving
Jan 01, 2026Deploying LLMs efficiently requires testing hundreds of serving configurations, but evaluating each one on a GPU cluster takes hours and costs thousands of dollars. Discrete-event simulators are faster and cheaper, but they require re-implementing the serving system's control logic -- a burden that compounds as frameworks evolve. We present Revati, a time-warp emulator that enables performance modeling by directly executing real serving system code at simulation-like speed. The system intercepts CUDA API calls to virtualize device management, allowing serving frameworks to run without physical GPUs. Instead of executing GPU kernels, it performs time jumps -- fast-forwarding virtual time by predicted kernel durations. We propose a coordination protocol that synchronizes these jumps across distributed processes while preserving causality. On vLLM and SGLang, Revati achieves less than 5% prediction error across multiple models and parallelism configurations, while running 5-17x faster than real GPU execution.
Maya: Optimizing Deep Learning Training Workloads using Emulated Virtual Accelerators
Mar 26, 2025



Training large foundation models costs hundreds of millions of dollars, making deployment optimization critical. Current approaches require machine learning engineers to manually craft training recipes through error-prone trial-and-error on expensive compute clusters. To enable efficient exploration of training configurations, researchers have developed performance modeling systems. However, these systems force users to translate their workloads into custom specification languages, introducing a fundamental semantic gap between the actual workload and its representation. This gap creates an inherent tradeoff: systems must either support a narrow set of workloads to maintain usability, require complex specifications that limit practical adoption, or compromise prediction accuracy with simplified models. We present Maya, a performance modeling system that eliminates these tradeoffs through transparent device emulation. By operating at the narrow interface between training frameworks and accelerator devices, Maya can capture complete workload behavior without requiring code modifications or translations. Maya intercepts device API calls from unmodified training code to directly observe low-level operations, enabling accurate performance prediction while maintaining both ease of use and generality. Our evaluation shows Maya achieves less than 5% prediction error across diverse models and optimization strategies, identifying configurations that reduce training costs by up to 56% compared to existing approaches.
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Sep 25, 2024
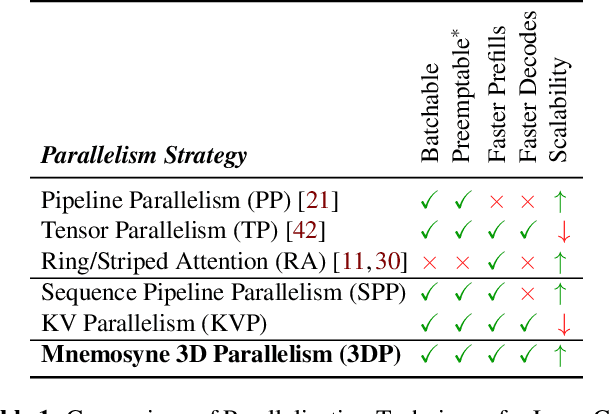
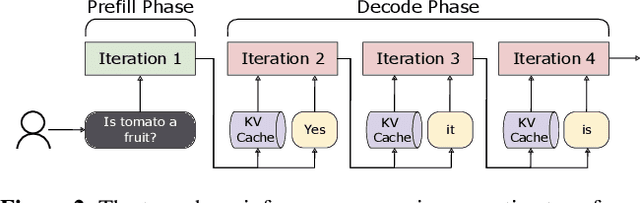
As large language models (LLMs) evolve to handle increasingly longer contexts, serving inference requests for context lengths in the range of millions of tokens presents unique challenges. While existing techniques are effective for training, they fail to address the unique challenges of inference, such as varying prefill and decode phases and their associated latency constraints - like Time to First Token (TTFT) and Time Between Tokens (TBT). Furthermore, there are no long context inference solutions that allow batching requests to increase the hardware utilization today. In this paper, we propose three key innovations for efficient interactive long context LLM inference, without resorting to any approximation: adaptive chunking to reduce prefill overheads in mixed batching, Sequence Pipeline Parallelism (SPP) to lower TTFT, and KV Cache Parallelism (KVP) to minimize TBT. These contributions are combined into a 3D parallelism strategy, enabling Mnemosyne to scale interactive inference to context lengths at least up to 10 million tokens with high throughput enabled with batching. To our knowledge, Mnemosyne is the first to be able to achieve support for 10 million long context inference efficiently, while satisfying production-grade SLOs on TBT (30ms) on contexts up to and including 10 million.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024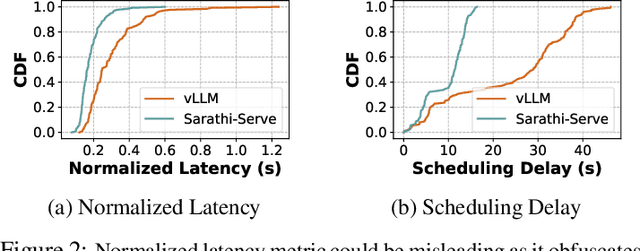
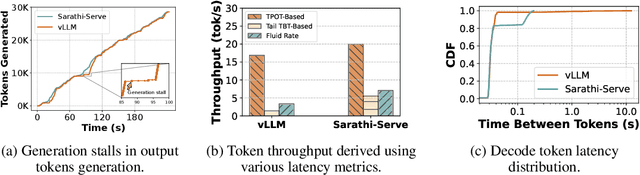
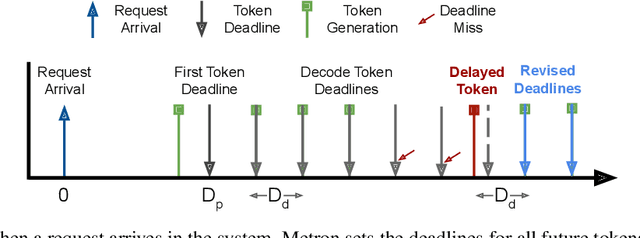
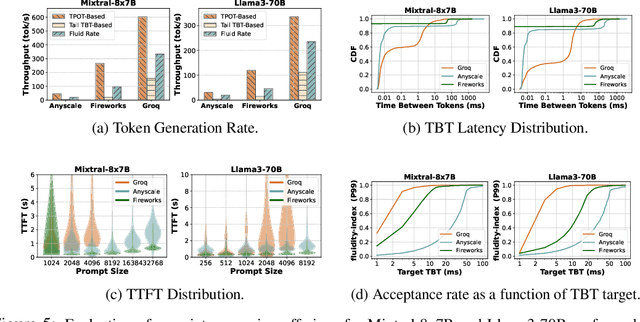
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024

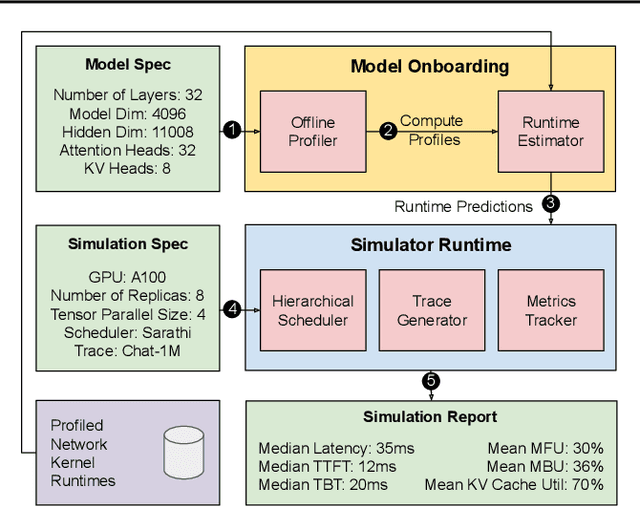
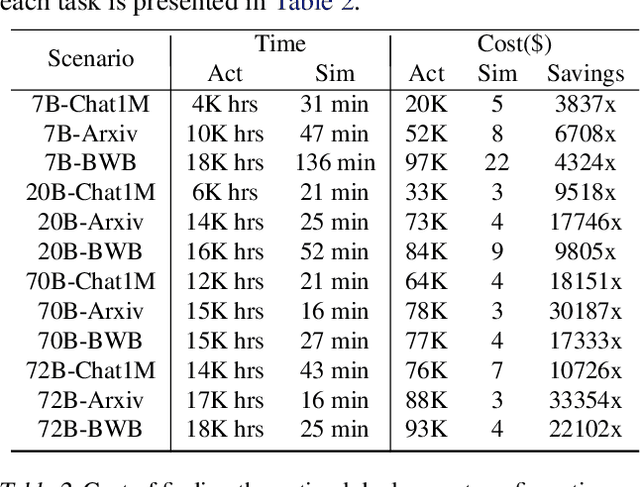
Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024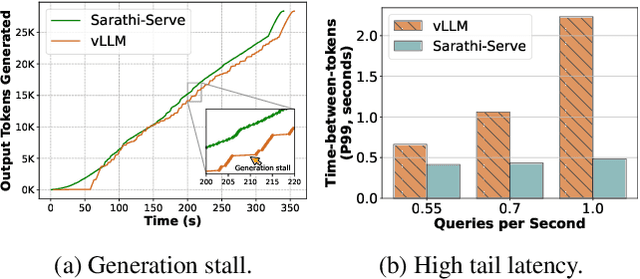

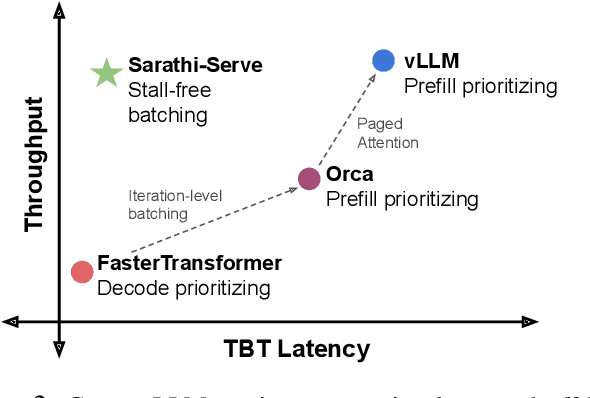

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Aug 31, 2023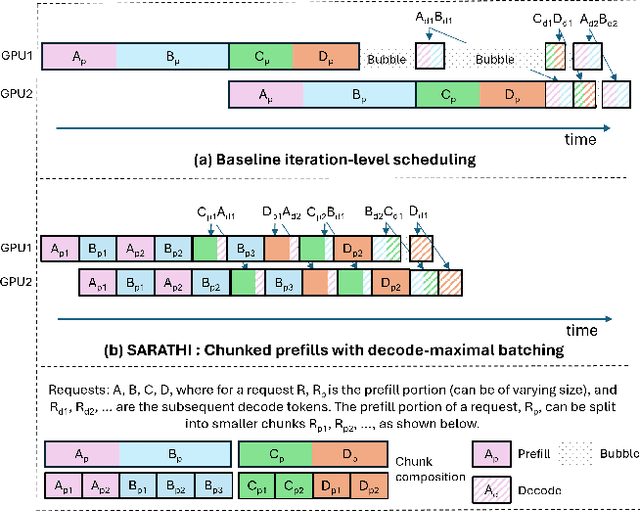
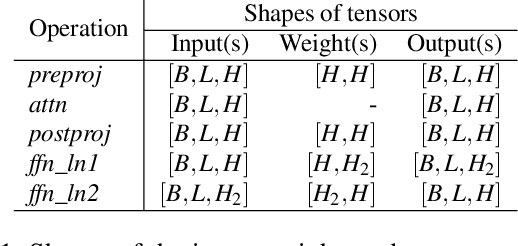
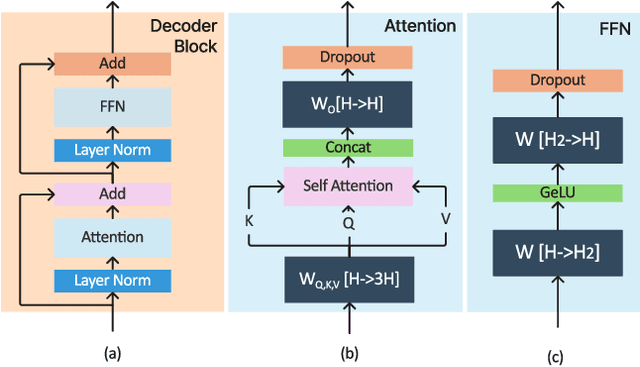
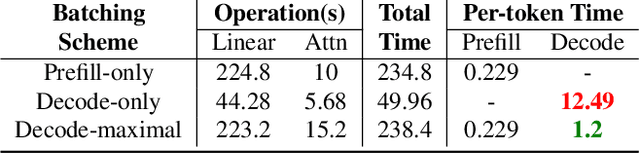
Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill phase effectively saturates GPU compute at small batch sizes, the decode phase results in low compute utilization as it generates one token at a time per request. The varying prefill and decode times also lead to imbalance across micro-batches when using pipeline parallelism, resulting in further inefficiency due to bubbles. We present SARATHI to address these challenges. SARATHI employs chunked-prefills, which splits a prefill request into equal sized chunks, and decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests 'piggyback' and cost up to an order of magnitude less compared to a decode-only batch. Chunked-prefills allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform compute design of these batches ameliorates the imbalance between micro-batches, significantly reducing pipeline bubbles. Our techniques yield significant improvements in inference performance across models and hardware. For the LLaMA-13B model on A6000 GPU, SARATHI improves decode throughput by up to 10x, and accelerates end-to-end throughput by up to 1.33x. For LLaMa-33B on A100 GPU, we achieve 1.25x higher end-to-end-throughput and up to 4.25x higher decode throughput. When used with pipeline parallelism on GPT-3, SARATHI reduces bubbles by 6.29x, resulting in an end-to-end throughput improvement of 1.91x.
DynaQuant: Compressing Deep Learning Training Checkpoints via Dynamic Quantization
Jun 20, 2023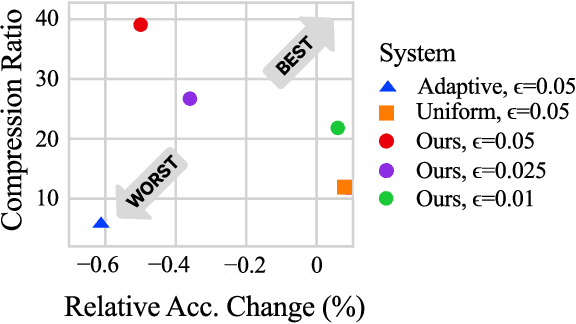

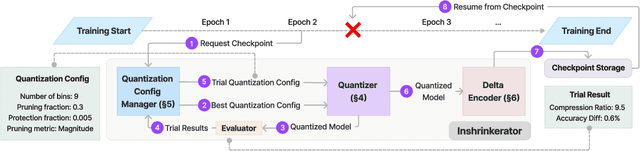
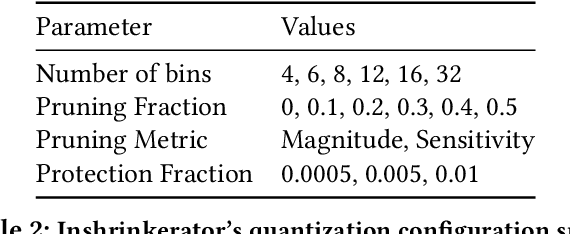
With the increase in the scale of Deep Learning (DL) training workloads in terms of compute resources and time consumption, the likelihood of encountering in-training failures rises substantially, leading to lost work and resource wastage. Such failures are typically offset by a checkpointing mechanism, which comes at the cost of storage and network bandwidth overhead. State-of-the-art approaches involve lossy model compression mechanisms, which induce a tradeoff between the resulting model quality (accuracy) and compression ratio. Delta compression is then also used to further reduce the overhead by only storing the difference between consecutive checkpoints. We make a key enabling observation that the sensitivity of model weights to compression varies during training, and different weights benefit from different quantization levels (ranging from retaining full precision to pruning). We propose (1) a non-uniform quantization scheme that leverages this variation, (2) an efficient search mechanism to dynamically adjust to the best quantization configurations, and (3) a quantization-aware delta compression mechanism that rearranges weights to minimize checkpoint differences, thereby maximizing compression. We instantiate these contributions in DynaQuant - a framework for DL workload checkpoint compression. Our experiments show that DynaQuant consistently achieves better tradeoff between accuracy and compression ratios compared to prior works, enabling a compression ratio up to 39x and withstanding up to 10 restores with negligible accuracy impact for fault-tolerant training. DynaQuant achieves at least an order of magnitude reduction in checkpoint storage overhead for training failure recovery as well as transfer learning use cases without any loss of accuracy
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022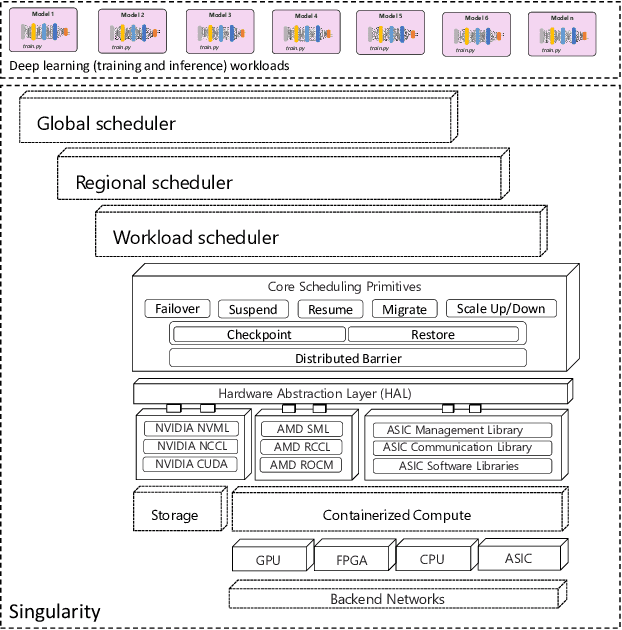
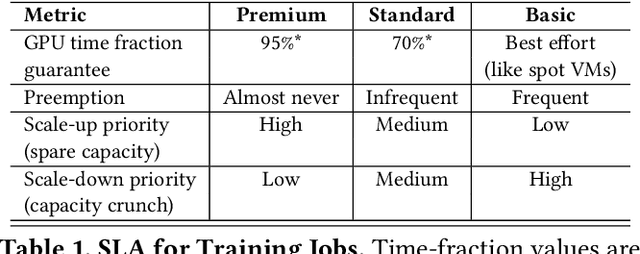
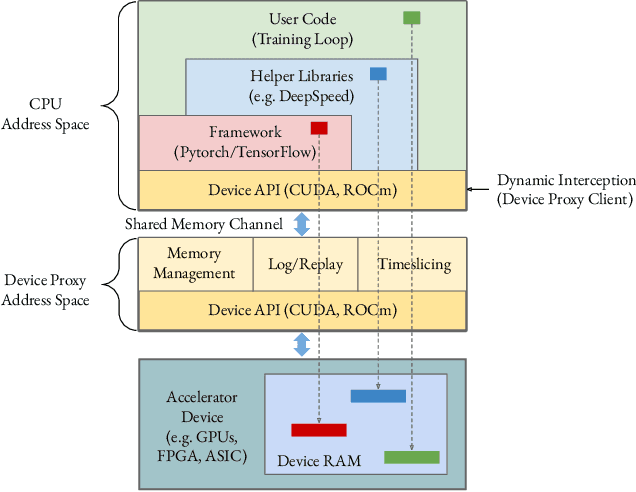
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).
Learning Digital Circuits: A Journey Through Weight Invariant Self-Pruning Neural Networks
Sep 05, 2019
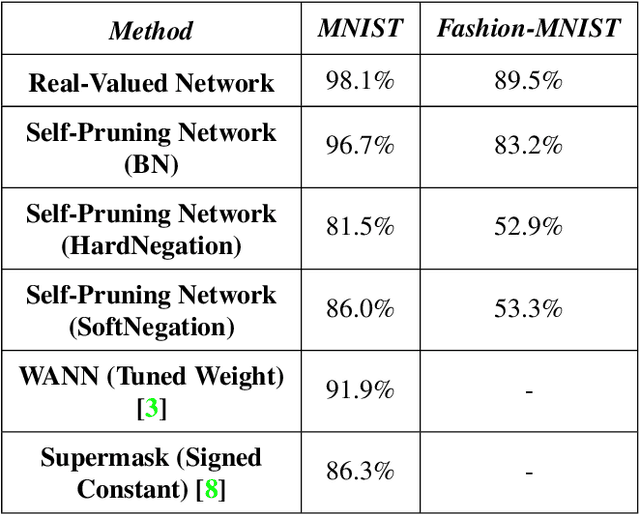
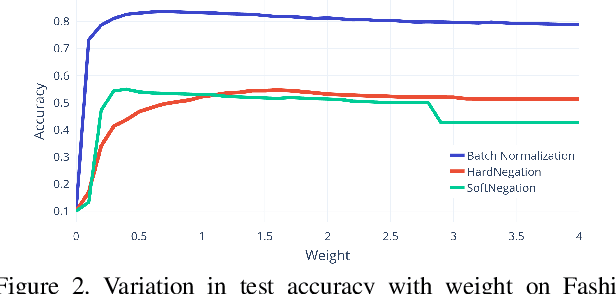
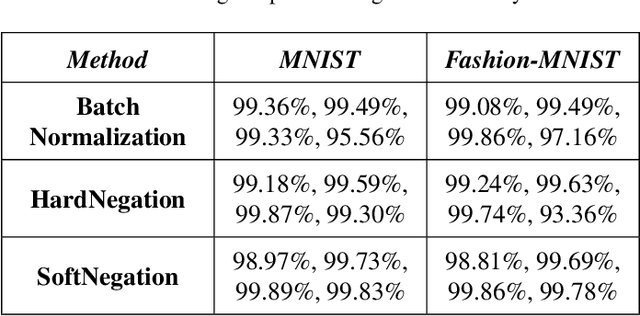
Recently, in the paper "Weight Agnostic Neural Networks" Gaier & Ha utilized architecture search to find networks where the topology completely encodes the knowledge. However, architecture search in topology space is expensive. We use the existing framework of binarized networks to find performant topologies by constraining the weights to be either, zero or one. We show that such topologies achieve performance similar to standard networks while pruning more than 99% weights. We further demonstrate that these topologies can perform tasks using constant weights without any explicit tuning. Finally, we discover that in our setup each neuron acts like a NOR gate, virtually learning a digital circuit. We demonstrate the efficacy of our approach on computer vision datasets.