 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Prompt-based Few-Shot Learning for Natural Language Understanding
Jun 21, 2023State-of-the-art few-shot learning (FSL) methods leverage prompt-based fine-tuning to obtain remarkable results for natural language understanding (NLU) tasks. While much of the prior FSL methods focus on improving downstream task performance, there is a limited understanding of the adversarial robustness of such methods. In this work, we conduct an extensive study of several state-of-the-art FSL methods to assess their robustness to adversarial perturbations. To better understand the impact of various factors towards robustness (or the lack of it), we evaluate prompt-based FSL methods against fully fine-tuned models for aspects such as the use of unlabeled data, multiple prompts, number of few-shot examples, model size and type. Our results on six GLUE tasks indicate that compared to fully fine-tuned models, vanilla FSL methods lead to a notable relative drop in task performance (i.e., are less robust) in the face of adversarial perturbations. However, using (i) unlabeled data for prompt-based FSL and (ii) multiple prompts flip the trend. We further demonstrate that increasing the number of few-shot examples and model size lead to increased adversarial robustness of vanilla FSL methods. Broadly, our work sheds light on the adversarial robustness evaluation of prompt-based FSL methods for NLU tasks.
DynaQuant: Compressing Deep Learning Training Checkpoints via Dynamic Quantization
Jun 20, 2023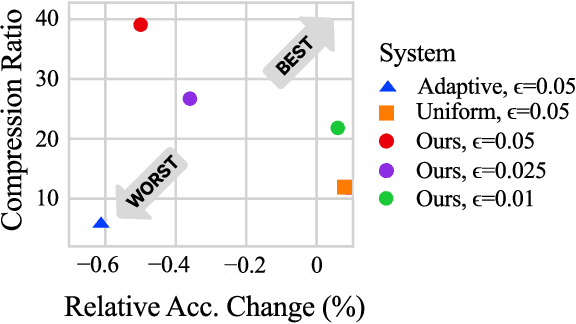

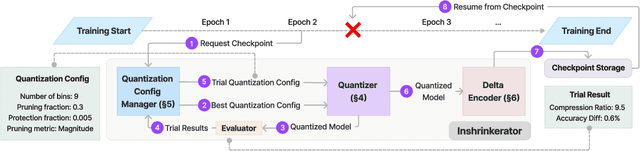
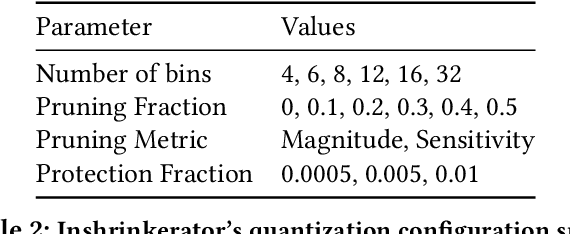
With the increase in the scale of Deep Learning (DL) training workloads in terms of compute resources and time consumption, the likelihood of encountering in-training failures rises substantially, leading to lost work and resource wastage. Such failures are typically offset by a checkpointing mechanism, which comes at the cost of storage and network bandwidth overhead. State-of-the-art approaches involve lossy model compression mechanisms, which induce a tradeoff between the resulting model quality (accuracy) and compression ratio. Delta compression is then also used to further reduce the overhead by only storing the difference between consecutive checkpoints. We make a key enabling observation that the sensitivity of model weights to compression varies during training, and different weights benefit from different quantization levels (ranging from retaining full precision to pruning). We propose (1) a non-uniform quantization scheme that leverages this variation, (2) an efficient search mechanism to dynamically adjust to the best quantization configurations, and (3) a quantization-aware delta compression mechanism that rearranges weights to minimize checkpoint differences, thereby maximizing compression. We instantiate these contributions in DynaQuant - a framework for DL workload checkpoint compression. Our experiments show that DynaQuant consistently achieves better tradeoff between accuracy and compression ratios compared to prior works, enabling a compression ratio up to 39x and withstanding up to 10 restores with negligible accuracy impact for fault-tolerant training. DynaQuant achieves at least an order of magnitude reduction in checkpoint storage overhead for training failure recovery as well as transfer learning use cases without any loss of accuracy